OpenAI,是的,小编对这家机构最深的记忆还是用AI玩Dota 2。该组织在6月12日正式宣布,AI文字产生系统已开放API,以私下申请制向外界付费公开,Reddit已率先使用。
OpenAI文字产生模型GPT-2,能根据输入的简短文字生成几可乱真的文章,去年初公布时,外界还担心新闻杜撰问题。
去年底该公司认为并没有被滥用作为非法的事,于是发布完整的GPT-2模型。本月2日又发布高达1750亿个参数的GPT-3模型,是上一代的100多倍,不仅能写文章,还会算数学,而且完全不须任何微调或梯度更新,只需要提供少量的文字范例即可。最新的API即是建立在这最先进AI模型上。
新服务目前以私有beta版形式开放,接受外界申请、存取OpenAI的AI模型。不同于多数AI系统为单一使用情境而设计,OpenAI强调其API支持多种用途,让客户试用几乎任何全英文任务。企业用户可将新的API整合到产品中开发出新应用。
这项服务的商业化除了能营收外,也能藉由不同案例协助OpenAI改良其通用型模型。目前申请这个服务的组织包含搜寻引擎初创公司Algolia、行为学习工具Quizlet、Reddit及加州明德大学蒙特雷国际研究学院(Middlebury Institute)。
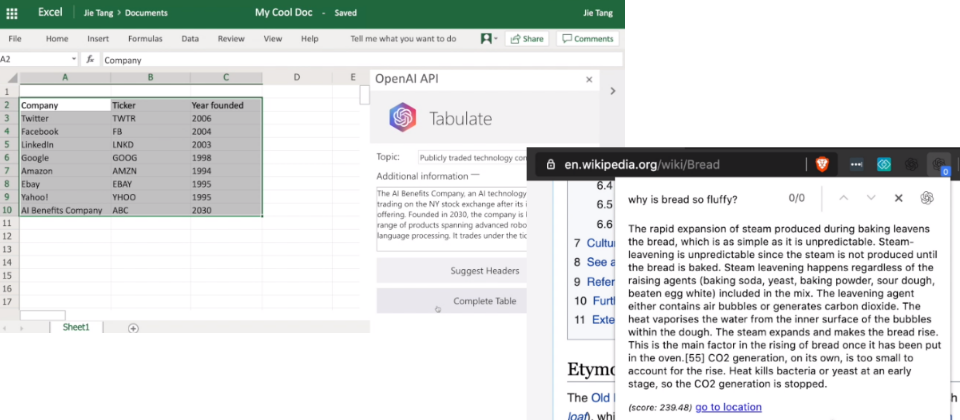
新的GPT-3 API具备文字进、文字出界面,就是用户给一段文字,API就会配合文字的模式回覆一段文字。使用者可设定少量文字的几个例子,但OpenAI文字产出的成果良窳,就得视任务的複杂度而定。这个API还能提升用户系统效能,利用用户提供的范例资料集来训练,或根据用户或标注者提供的回馈而学习。
OpenAI指出这个API一方面够简单到任何人都会用,另一方面却能支持机器学习团队的工作生产力。他们表示自己的机器学习团队,也是用该API来精进技术。
但为了防止有人利用其API服务从事明显有害的任务,像是骚扰、释出垃圾邮件、造假、製造极端对立等,OpenAI一开始会以私下申请制而非向大众公开,并提供工具协助使用者控管产出的API内容,该公司也说会投入文字偏见的分析、改良和干预,并等初期测试顺畅后再推向更多用户。