如果你是一位算法科学家或者是AI应用开发者,当你的算法在GPU上的运行速度非常慢时,你通常会怎么想?是不是会先怀疑自己,觉得算法有问题,或者是软件代码有问题?
其实还有一种情况,如果算法模型是较为稀疏的卷积,那么问题则可能出在GPU身上,因为GPU的架构不适应稀疏的卷积,而擅长处理这一场景的处理器叫IPU。在许多机器学习场景下,IPU都比GPU快,而且,这类场景会越来越多,IPU是一种非常有前景的AI芯片,如今是仅次于GPU和TPU的第三大商用AI芯片方案。
IPU是什么?
众所周知,GPU的并行能力远胜于CPU,相比之下,GPU更擅长处理机器学习工作负载,而IPU与CPU、GPU又完全不同,它是专为机器学习设计的处理器架构,比GPU更擅长处理机器学习的工作负载。
据Graphcore高级副总裁兼中国区总经理卢涛介绍,IPU在现有以及下一代模型上的性能均优于GPU,在自然语言处理方面的速度能比GPU快25%到 50%;在图像分类方面,吞吐量6倍于GPU,而且时延更低;在一些金融模型方面,速度相比于GPU能提升26倍以上。

Graphcore 高级副总裁兼中国区总经理
这三部分涵盖了人工智能的大部分场景,可以说,在许多场景中,IPU相对于GPU有很大优势,IPU很是厉害。
英国半导体之父、Arm联合创始人Hermann爵士说:“在计算机历史上只发生过三次革命,一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。”因为Graphcore率先提出了为AI计算而生的IPU。
Graphcore被许多业内大佬看好,目前已经获得了4.5亿美金的融资,除了许多知名金融投资机构外,包括宝马、博世、戴尔科技集团、微软、三星等都是其战略投资者。IPU也很争气,目前IPU GC2已经量产,并装载在戴尔EMC DSS8440服务器供客户使用。此外,目前Graphcore在Microsoft Azure公有云上开放了IPU服务,并且马上将要推出和国内云服务商的合作。
为什么说IPU是面向AI设计的处理器?
首先,AI的工作负载与CPU、GPU提供的能力不太一样。AI工作负载的特点有许多,比如非常大规模的CPU不擅长的那种并行计算,又比如数据结构非常稀疏。此外,AI工作负载属于低精度计算,有大量的数据参数复用,还有静态图结构。以上种种都说明,AI负载是全新的计算负载。
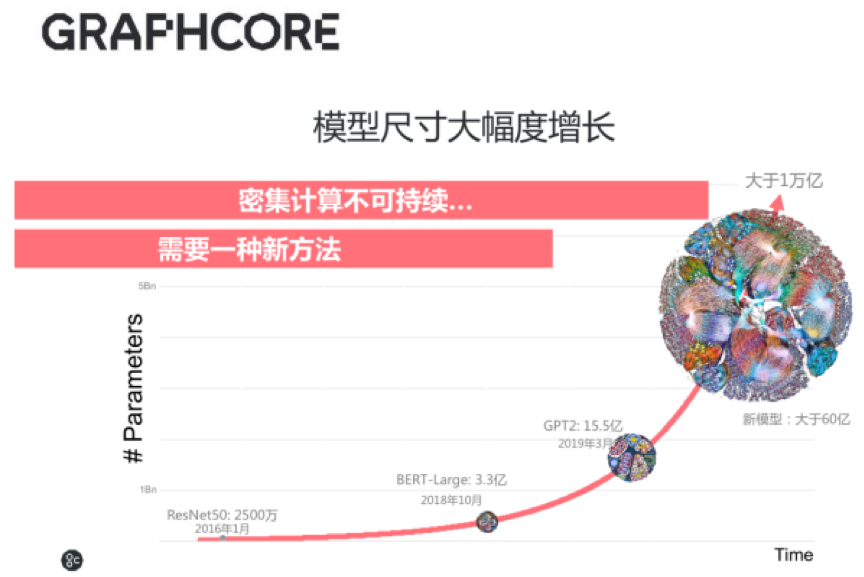
其次,IPU解决了CPU和GPU没能解决的问题。一般而言,一个AI模型的参数越多,那么预测就越精准,为了让AI发挥更大作用,模型会不可避免地变得越来越大。模型变大对应着更密集的计算,意味着需要更大的算力提升。然而,现有架构已经支撑不了这样的增速,所以,必须有专门面向AI的处理器来解决性能问题。
IPU诞生于此次人工智能兴起期间,又主要解决CPU和GPU解决不了的问题,所以完全可以说,IPU是面向AI设计的处理器。
三大特性解决性能问题

首先,片上内存解决内存性能问题。这么多年来,虽然内存主频在提升,内存带宽也在提升,但并没有跟上性能提升的速度,为了解决这一问题,Graphcore的IPU采用了大规模并行的MIMD(多指令流多数据流),并且在片上放置了大量SRAM内存,因为它能将AI模型和数据放到芯片上,这一做法非常激进,但性能真的是非常高,相对于CPU或者GPU的内存方案,内存性能有10到320倍的提升。

多核计算提供并行能力。目前已量产的IPU处理器(GC2)片内有1216个核,支持7296个线程,也就是支持7296个应用程序同时运行,多核并行能力奠定了性能基础。而想让多核高效运行,当然离不开通信技术。
高效的多核通信技术。一个IPU的处理器内部的1216个核心之间通过一个叫BSP(Bulk Synchronous Parallel)技术实现通信,核与核之间通过8 TB/s的交换总线交流数据。据了解,Graphcore的IPU是全球第一款BSP处理器。此外,在不同IPU处理器之间,用IPU-Links实现通信,带宽高达2.5 TB/s。

以上几点特性的加持使得在自然语言处理的BERT、ResNeXt这样的机器视觉场景下,Graphcore的IPU相对于GPU表现出许多优势,这里作为对比的GPU都是英伟达的上一代旗舰V100。谈到英伟达最新的A100时,卢涛表示对自己的产品也非常有信心。
看到这里,你就会发现,IPU最大的特点和优点其实就是一个字:快!
芯片设计只是第一步,配套工具链也很重要

对用户来说,AI芯片真的是太多了,Github上有人总结了AI芯片的全景图,一大类是各种巨头,包括谷歌、AWS、Facebook这样的超级互联网公司以及IT巨头;另一大类是老牌芯片设计厂商,比如英特尔、英伟达;最后一类是各种初创公司。AI芯片领域真的是不要太拥挤,看起来一片繁荣,但有时候选择太多也不是一件好事。
从芯片厂商看来,芯片设计完成后只是做了第一步,配套的工具链也非常重要。在开发人员看来,选择一个AI芯片平台的成本其实很高,开发人员需要熟悉这一平台,熟悉芯片配套的各种软件工具,熟悉从开发、训练、调试、部署、推理等方方面面。为了降低用户选择新平台的障碍,Graphcore做了许多工作。
据卢涛介绍,IPU支持的BSP协议能把整个计算逻辑分成计算、同步、交换三部分,对软件工程师或开发者来说,能让编程难度显著降低,因为它不用处理“锁(Lock)”的问题,有过开发经验的人应该知道锁的问题,如何避免“死锁”,如何优化“锁”是需要大量实践教训才能做的事情。
在芯片配套的开发软件上,Graphcore准备的也非常完备。分析机构Moor Insights & Strategy的分析师表示, “Graphcore是我们目前已知的唯一一家将其产品扩展到囊括如此庞大的部署软件和基础架构套件的初创公司。”
Graphcore配套的开发软件叫Poplar SDK,它是介于硬件平台和机器学习框架之间的工具,Poplar SDK支持各种常见的机器学习开发框架,比如TensorFlow、PyTorch和ONNX。
为了简化部署,Poplar SDK还提供容器化部署,能快速启动和运行起来。此外,也支持包括微软Hyper-V在内的虚拟化技术,支持Ubuntu、红帽以及CentOS等常见的Linux发行版。
5月,Graphcore还推出了一个叫PopVision Graph Analyser的分析工具。开发者、研究者在使用IPU进行编程的时候,可以通过PopVision这个可视化的图形展示工具来分析软件运行效率,并进行调试调优。
IPU是第三大AI芯片平台
虽然芯片门类很多,看似选择很多,但从实际部署来看,IPU是仅次于GPU和谷歌TPU的第三大部署平台,Graphcore的商业化合作进展其实非常快,目前,基于IPU的应用已经覆盖了机器学习的各个应用领域,包括自然语言处理、图像/视频处理、时序分析、推荐/排名及概率模型等。
不久前的Intelligent Health峰会上,微软分享了如何使用IPU训练CXR(胸部X光射线样片),帮助医学研究人员进行新冠肺炎的快速诊断。微软用IPU在30分钟内完成了传统GPU需要5个小时才能完成的训练工作量。
在金融领域涉及算法交易、投资管理、风险管理及诈骗识别的场景中,相对于GPU,IPU可以更快、更准确地发挥人工智能的能力。
在医疗和生命科学领域,IPU的使用可以让人工智能在新药发现、医学图像、医学研究、精准医疗等场景中的过程加速。
在电信领域的智慧网络、5G创新、预测性维护和客户体验方面,由于性能表现远高于GPU,IPU的创新技术和能力也展示出了较高价值。
在中国市场,Graphcore与阿里巴巴和百度两家互联网巨头建立合作关系。OCP峰会上,阿里巴巴异构计算首席科学家张伟丰博士宣布了Graphcore支持ODLA的接口标准;Wave Summit 2020上,百度宣布Graphcore为百度飞桨硬件生态圈共建合作伙伴,此举对于Graphcore在中国市场的发展非常重要。