正值618大促,小张遇到了一个棘手的问题,需要在一周内将公司近1年电商部门的营收和线下门店经营数据进行联合分析。
这将产生哪些数据难题呢?
· 数据孤岛:电商部门的数据存在数仓A;门店经营收入数据存在数仓B;如何便捷的进行多仓联合分析?
· PB级数据量:多电商平台+全国线下门店每天将产生TB级数据量,年数据量高达PB级!
他在第一时间联系了集团CTO,希望将各部门数据在一天内导出给他。
这时候,CTO犯难了:
公司现有的资源池可自如应对TB级数据量,而小张要的数据量粗略估计达到了PB级,大大超出了公司现有资源池承受范围,只能以时间为代价导出;而为了不常见场景扩大公司资源池,整体的成本太高。
面对小张遇到的棘手问题,云湖湖推荐了一款华为云大数据查询分析神器——数据湖探索(DLI)服务;一个DLI即可撬动EB级数据量联合查询,每CU仅需0.35元/小时(1CU=1Core4G Mem),1CU包月仅需150元。
数据湖探索(DLI)服务 2.0是完全兼容Apache Spark和Apache Flink生态的Serverless大数据计算分析服务,用户仅需使用标准SQL或程序即可查询分析各类异构数据源。
DLI是如何解决小张问题的呢?
1、 DLI服务架构——Serverless
DLI是无服务器化的大数据查询分析服务它的优势在于:
01. 按量计费:真正的按使用量(扫描量/CU时)计费,不运行作业时0费用。
02. 自动扩缩容:根据业务负载,对计算资源进行预估和自动扩缩容。
DLI Serverless架构就可轻松解决小张成本、资源不足和临时性业务需求的问题。
2、 DLI核心引擎——Spark+Flink
Spark是用于大规模数据处理的统一分析引擎,聚焦于查询计算分析。DLI在开源Spark基础上进行了大量的性能优化与服务化改造,不仅兼容Apache Spark生态和接口,性能较开源提升了2.5倍,在小时级即可实现EB级数据查询分析。同时,DLI也提供用于实时处理的Flink引擎。
3、 DLI王牌功能——跨源分析
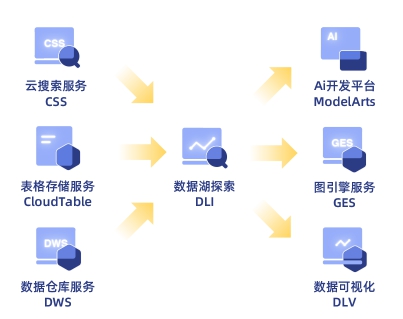
DLI支持云上多种云服务、自建数据库以及线下数据库,可直接实现多数据源跨库分析,构建企业的统一视图。
小张将线下数仓A与数仓B同时接入DLI,就可直接在DLI上进行联合查询。避免了两仓数据迁移再重新建仓进行联合查询的过程,轻松搞定跨库查询。
数据湖探索(DLI)服务的其他优势
1. 纯SQL操作:提供标准SQL接口,用户仅需使用SQL便可实现海量数据查询分析。
2. 存算分离:存储和计算解耦,分开申请和计费,降低成本的同时,提高了资源利用率。
3. 企业级多租户:支持计算资源按租户隔离,数据权限控制到队列、作业,帮助企业实现部门间数据共享和权限管理
4. 免运维、高可用:用户无需感知底层运维、升级、跨AZ高可用,跨AZ双活。
数据湖探索(DLI)服务的应用场景
1. 数据库分析+DLI 2.0 :一键建仓 保留数据库的易用体验
痛点:
01. 数据库多无法做全量分析
02. 数据库复杂关系无法查询
03. 影响在线其他数据业务
解决方案:
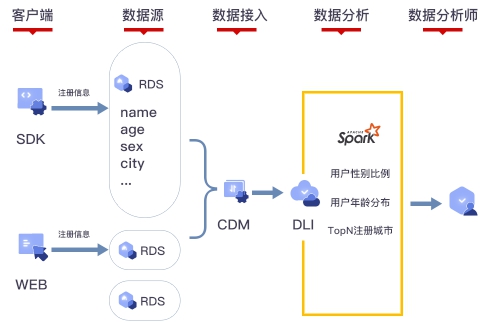
仅使用标准SQL即可完成大数据查询分析
2. 精准营销+DLI 2.0:电商智能推荐 跨库跨源海量数据秒级查询
痛点:
01. 数据源太多怎么联合分析
02. 智能推荐需要短时间内实现
解决方案:
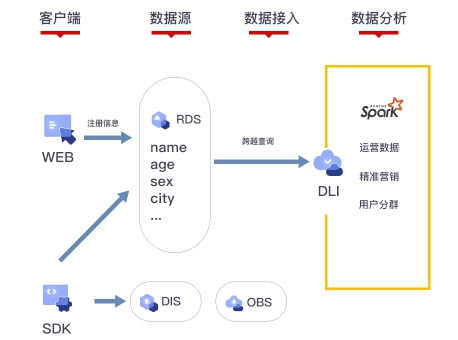
DLI跨源能力,轻松打破数据孤岛。现已支持10类数据源和线下自建数据。
3. 日志分析+DLI 2.0:公司必备场景 按量计费成本更低
痛点:
01. 日志分析时间跨度大
02. 资源空闲大利用率低
解决方案:

DLI按量计费,单CU每小时仅需0.35元。
4. 实时风控+DLI 2.0:金融、运维等实时场景 减少风险事件发生
痛点:
01. 数据刷新不及时,风险事件频繁发生
02. 需要深入了解Flink后台架构进行实时数据分析
解决方案:

风控系统对实时性要求很高,DLI采用高性能计算资源,单CPU每秒吞吐1千~2万条消息。