作者:百分点大数据团队
编者按
在数字政府领域,许多项目中都有各种类型的文件,它们有不同的大小、不同的用途,甚至编码方式都会千差万别。我们希望通过OSS来将这些文件按照一定的规则存储起来,在我们需要的时候,能很快的取出来,并且应用到当前的项目中,甚至能和其他的应用系统集成起来,形成一整套的基于OSS存储的生态系统。百分点基于实践探索自主研发出了OSS,可以将海量的网页内容、图片、音视频等非结构化数据,在高并发的场景下被快速、准确的存储及方便的下载。
对象存储服务(Object Storage Service,简称OSS),是百分点对外提供的海量、安全、低成本、高可靠的对象存储服务。用户可以通过简单的REST接口,进行数据的上传和下载。同时,OSS提供Java语言的SDK,简化用户的编程。基于OSS,用户可以搭建出各种个人和企业数据备份、业务数据应用等基于大规模数据存储的服务。同时OSS还可以与其他组件搭配使用,广泛应用于海量数据存储与备份,数据加工与处理,内容加速分发,业务数据挖掘等多种业务场景。
1.架构设计
基于对OSS的要求,我们设计的架构如下图所示:
我们采用了HBase+Ceph来进行底层存储,对于小于1MB的数据进入HBase,对于大于1MB的数据进入Ceph,同时数据通过Tomcat提供对外服务。基于上面的架构,我们的OSS可以实现以下的性能目标。
1.1 高吞吐性
OSS的底层存储充分利用各组件的性能优势,来使整个集群可以达到较高的吞吐量。
HBase(Hadoop Database),是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。对于小于1MB的文件写入HBase是一个很棒的设计。
那么大于1MB的文件,我们存入哪里呢?有这么几种方案可供我们选择,比如Hadoop,FastDFS,Ceph等组件。我们最终选择了Ceph做大文件存储。
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。Ceph的开发目标可以简单定义为以下三项:
- 可轻松扩展到数PB容量
- 支持多种工作负载的高性能
- 高可靠性
1.2 高可用性
高可用性对文件存储系统是极为重要的,因为数据是极为宝贵的,如果数据在OSS中很容易丢失或者不可靠,那么它的存在意义就不大了。
对于OSS的高可用,我们早就做了深思熟虑的思考。HBase的数据最终存储HDFS中,而HDFS是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(DistributedFile System)。我们可以通过定义它的多副本机制来达到它的高可用性。
和HBase类似,Ceph也可以通过多副本机制来实现它的高可用性。
同时,我们可以定义存储的文件的过期时间来避免存储的文件无限增长,在我们的应用中,默认设置为90天。
1.3 可扩展性
当系统的吞吐量越来越大,或者存储容量以及快达到OSS所能承受的流量瓶颈时,我们可以通过横向扩展相关组件来应对流量的变化。
对于直接对外提供Rest接口的Tomcat服务,如果单Tomcat服务器达到性能瓶颈时,我们可以增加Tomcat服务器来进行横向扩展,同时为了对外提供统一的网关,我们增加了LVS+Keepalived这一层来实现,如下图所示:
正常情况下,LVS使用DR模式代理若干台Tomcat服务器,keepalived是实现LVS的高可用的。当其中一台LVS出现故障下线后,keepalived通过虚拟IP技术快速切换到另外一台可用的LVS上。
另外对于HBase和Ceph的扩展性是简单易于实现的,只需要增加待扩展的机器,进行相关配置,即可快速加入集群,相应的数据也会进行rebalance。
1.4 限流算法
在上面的功能概览中简单的说明了在某些场景中我们需要进行流量限制,那么这里将详细介绍限流的原理。
在OSS中,我们使用Guava的RateLimiter作为限流的组件。Guava的RateLimiter的限流方式有两种:漏桶算法和令牌桶算法。我们采用的是令牌桶算法。
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
我们的OSS就是采用令牌桶的方式来对流量进行限制的,当客户端以某一稳定的速率来向OSS写入的时候,系统是稳定的并且大多数的时候是这样的。但是我们有时需要应对流量峰值,这个时候超过我们规定的流量就会被限制。现在问题来了,被限制的流量如果直接丢弃,那么可能重要的文件被丢弃,这样显然不符合我们对OSS定位为高可用存储系统的要求。于是在限流的逻辑中我们加入了以下处理流程:当流量达到系统的瓶颈时,我们将被限流的流量写入kafka,等到系统负载降低的时候,再从kafka中读取这部分流量重放至OSS,这样既保证了OSS的稳定性,又解决因限流带来的数据丢失问题。
2.功能概览
2.1 文件上传
客户端以RESTFul接口方式向OSS服务器发送上传文件的请求,OSS将文件存储到HBase或Ceph中,然后向客户端返回存储的状态。
我们将文件名作为存储的唯一标识,这样设计的好处有两点,第一,我们不需要返回用户文件在OSS服务器的存储路径;第二,也可以避免同名文件反复上传。
2.2 文件下载
客户端以RESTFul接口方式带上需要查询的文件名请求OSS服务器,OSS根据文件名查询对应的文件,返回请求客户端。
2.3 流量限制
流量限制是以一种被动的方式来对流量进行控制的方式。我们可以通过压力测试来粗略估计OSS所能承受的最大压力,然后在配置文件中配置限流的数值。这里要注意的是,需要根据业务的特点对限制的流量进行处理,其一,可以完全丢弃掉被限制的流量;其二,也可以对限制的流量进行相应的处理。
3.场景分析
现以公司某项目做讲解来进一步说明OSS在项目中的实际应用以及最佳实践。
3.1 项目的现状
3.1.1 流量情况
以中期某城市交付为基准:每秒约120Gb流量,每天1.5亿个文件,每秒大概1800个文件。
其它各分中心的数据均为上述城市的倍数,比如A中心的比例系数为33.33,那么它每秒的流量约4000Gb,每天约34亿个文件,每秒大概6万个文件,以此类推。
3.1.2 单机性能
目前单机Tomcat能支撑最大12000TPS,对于各中心每秒的数据量,单机显然不能支撑这么大的数据量,我们需要采用Tomcat集群来支撑这么大的数据流量。
3.1.3 流量峰值
在进行机器数以及相关硬件进行评估时,需要考虑流量峰值的情况,我们一般以正常流量的2到3倍来进行规划,比如,某个分中心的流量为每秒1300Gb,那么我们设计时就需要考虑峰值的情况,也就是最大能支撑每秒3900的流量。
3.2 集群的设计目标
基于上面描述的项目现状,经过分析,我们的整个OSS集群需要实现以下设计目标:
- 各中心采用Tomcat集群来支撑数据流量
- 各中心的流量均衡打到每台Tomcat服务器
- 负载均衡设备的高可用
- 存储服务的稳定性
3.3 最佳实践
3.3.1 如何保证Tomcat单机的性能最优
我们主要从以下几个方面来优化Tomcat的性能:
1)JVM内存大小
2)最大线程数(maxThreads)
3)最大连接数(maxConnections)
4)全连接队列长度(acceptCount)
我们选用单台机器来测试Tomcat的性能,硬件配置如下:

Tomcat的版本选用8.5.43。
测试的目标:
- 单台Tomcat支持的最大并发数
- 单台Tomcat支持的最大TPS
- NIO模型和APR模型的性能对比
测试工具使用:ApacheBench。
我们使用对比测试的方法,分别测试在上传1KB,10KB,100KB,1M,10M,100M的时候,Tomcat各项指标的数值。
Tomcat配置:maxThreads=100,minSpareThreads=10,acceptCount=102400,maxConnections=1000000,acceptorThreadCount=2
JVM配置:-Xmx16384m -Xms16384m
-Xmn1024m -XX:+UseConcMarkSweepGC
-XX:MaxPermSize=256m
1、使用NIO模型的测试结果如下:
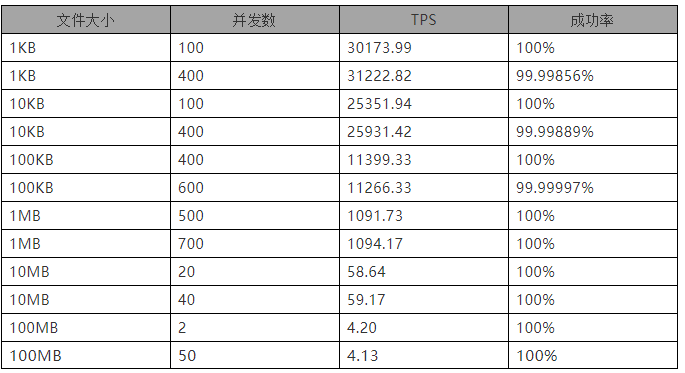
根据以上测试结果可得出以下结论:
1)在上传相同文件大小的情况下,随着并发数的增大,会出现一定的丢包情况;
2)在相同并发量的情况下,随着上传文件大小增大,吞吐量会随之下降。
2、使用APR模型的测试结果如下:
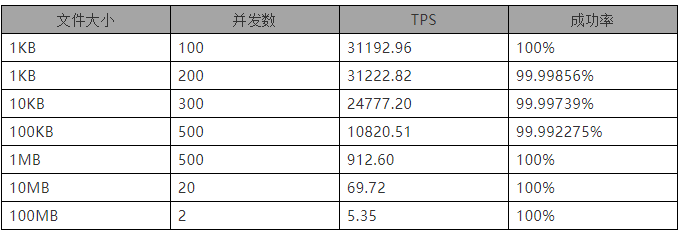
根据以上测试结果以及对比NIO模型的测试结果,我们可以得出以下结论:
1)小文件上传APR模式不如NIO模式,大文件上传APR模式要好于NIO模式;
2)随着并发的增加,TPS先增加后减少,平均响应时间不断增加;
3)小文件应该关注TPS,大文件应该关注平均响应时间;
4)小文件TPS大概在2万到3万之间,能接受的并发在300到500之间。
3.3.2 如何保证HBase存储的稳定性
HBase以高吞吐著称,那么我们应该如何在保证高吞吐的情况下,能保证稳定的存储。主要应该关注两个点:
1)GC的次数以及停顿时间;
2)HBase的compaction机制。
3.3.2.1 GC调优
由于HBase是使用Java编写的,所以垃圾收集(GC)对HBase的影响也是很大的,我们需要适当调整GC相关的参数,使得HBase能达到较好的性能和稳定的运行。在JVM中,有很多种垃圾收集器,我们在项目中使用的是CMS GC,下面首先介绍CMS GC的工作原理,再详细说明调优的相关细节。
3.3.2.2 GC调优目标
在介绍具体的调优技巧之前,有必要先来看看GC调优的最终目标和基本原则:
1)平均Minor GC时间尽可能短;
2)CMS GC次数越少越好。
3.3.2.3 HBase 场景内存分析
一般来讲,每种应用都会有自己的内存对象特性,分类来说无非就两种:一种是对象的生存期较短的工程,比如大多数的HTTP请求处理工程,这类的对象可能占到所有对象的70%左右;另一种是对象生存期居多的工程,比如类似于HBase,Flink等这类大内存工程。这里以HBase为例,来看看具体的内存对象:
1)RPC请求对象
2)Memstore对象
3)BlockCache对象
因此可以看到,HBase系统属于对象生存期居多的工程,因为GC的时候只需要将RPC这类对象生存期较短的Young区淘汰掉就可以达到最好的GC效果。
在HBase优化中比较关键的两个GC的参数。
1)年轻代Young区的大小;
2)年轻代Young区中的Survivor区的大小以及进入老年代的阈值。
3.3.2.4 生产环境中的GC配置
假设我们机器的物理内存是80G,所以根据上面的分析,我们可以对相关的参数做如下配置:
1)缓存模式采用BucketCache策略Offheap模式
2)内存我们采用如下配置:
-Xmx64g -Xms64g -Xmn4g -Xss256k
-XX:MaxPermSize=512m
-XX:SurvivorRatio=2
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+CMSParallelRemarkEnabled
-XX:MaxTenuringThreshold=15
-XX:+UseCMSCompactAtFullCollection
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=75
-XX:-DisableExplicitGC
3.3.3 如何保证大流量情况下系统稳定运行
流量限制是以一种被动的方式来对流量进行控制的方式。我们可以通过压力测试来粗略估计OSS所能承受的最大压力,然后在配置文件中配置限流的数值。这里要注意的是,需要根据业务的特点对限制的流量进行处理,其一,可以完全丢弃掉被限制的流量;其二,也可以对限制的流量进行相应的处理。
4.OSS监控
OSS在运行过程中,我们需要了解相关的监控信息,比如每种文件类型在一段时间的占比,或者在一段时间的网络吞吐量等等,下面就来一一介绍我们是如何来对OSS进行监控的吧。
4.1 以文件类型划分的指定时间段内的总存储占比
该图表用于统计当前OSS中各文件类型存储的占比。
4.2 以文件类型划分的指定时间段内的文件数量占比
该图表用于统计当前OSS中各文件类型数量的占比。
4.3 OSS服务指定时间段内的网络吞吐量
该图表用于统计OSS的吞吐量。
4.4 OSS服务指定时间段内的每秒并发处理数(TPS)
该图表用于统计当前OSS的负载情况。
5.结语与展望
我们认为,OSS一定会成为一个集安全性、可靠性于一体的底层存储服务。基于OSS,在公安领域可以存储天网中的卡口和视频数据,并与公安内部的其他应用形成一个基于高可用存储、多方向应用的解决方案;在社会治理方面,可以存储网络上的各种类型的数据,包括文字、音频以及视频,通过使用人工智能分析其中的关联性,为社会提供更安全的保证。