一、智能货柜发展背景
近年来,随着各项创新技术渐趋成熟,智能售货柜逐渐取代其他零售物种,成为无人零售终端的行业选择。相比于传统自动售货机,智能售货柜具有成本低,运营方便、灵活性高等优势,为越来越多的零售运营商和品牌商所接受。本文针对当前各种不同形态的智能柜,从技术和使用方面做个大盘点。
二、智能货柜技术方案解析
当下主流的智能货柜技术方案有RFID电子标签识别、重力感应、视觉识别这几大类。在这其中,RFID识别方案因为需要给商品贴电子标签带来的成本太高,已经逐步淡出运营商的视野,本文将不再重点讲述。接下来,笔者将重点讨论重力感应、视觉识别这几种方案,从技术原理和用户体验等方面做深度分析。
2.1 重力感应解决方案

社区生鲜重力柜
重力感应解决方案在每个货道上均装有重力感应器,核心原理即通过感知货道上的重力变化来判断消费者实际拿取的商品。基于底层原理,该方案拥有以下应用特性:
(1)不涉及人工智能算法模型搭建,无需对商品进行学习,便于商品上新
(2)可自动称重售卖散装生鲜产品,非常适用于社区生鲜零售场景;
(3)支持多品类SKU售卖,商品可堆叠摆放以充分利用柜体空间。
同时,该方案中,商品重量成为唯一识别标准,这也造成了诸多弊端:
(1)无法识别重量相同的SKU;
(2)置换商品位置后会出现识别误差;
(3)长期放置后,胀气、湿度等影响因素将使商品重量发生变化,同时重力感应器长久发生形变后难以感知小幅度重力变化,识别精度无法保证;
(4)只感知单次消费重力变量,不涉及库存盘点,给实际运营管理造成困难。
2.2 动态视觉识别

动态视觉柜购物视频截图
动态视觉识别方案通常是在柜体顶端或两侧安装1-4个摄像头,对消费者开门后拿取商品的过程进行录制,视频上传至后台系统后,通过对购物视频进行识别从而确定消费者拿取的商品信息。基于此,笔者总结了动态视觉柜的应用特性:
(1)对商品陈列无任何要求,商品可堆叠摆放,能够提高空间利用率,适用于仓储运营场景;
(2)商品的学习成本比较低,支持多品类SKU售卖。
动态视觉方案仅依据消费者开门后拿取商品的视频来进行识别,非常容易受到外界干扰,如果遇到消费者故意遮挡商品信息、快速拿取商品导致画面模糊、有意遮挡摄像头无法正常拍摄等情况,便无法正确识别商品。因此目前市场上已投放运营的动态视觉智能柜均为100%人工识别,通过人工审查视频来完成消费结算,在运营中存在诸多局限性:
(1)视频上传流量费用高,带宽成本远高于其他方案;
(2)依赖于人工,使得消费结算时间非常不稳定,短则几秒钟,长则一天,严重影响购物体验;
(3)识别准确率较低。以上图为例,视频定格画面十分模糊,难以准确判断商品信息;
(4)仅针对消费过程进行变量记录,无法对柜内货品进行精确盘存,货损率比较高。
2.3 静态视觉识别
该方案同样是基于计算机视觉算法,但实现原理与动态方案有着本质的区别。静态视觉柜每层货架的顶端都安装有摄像头,在消费者开门前、后,摄像头均会对柜内物体进行拍照并上传系统,系统后台的算法模型会对所有图片进行检测识别,并生成开门前、后柜内商品的库存明细,通过计算商品库存量差值来判断消费者实际拿取的商品。

经过大量的实例验证,静态视觉方案有诸多优势:
(1)以人工智能算法完全取代人力审核,结算速度快,识别稳定;
(2)识别准确率高,同时也可通过实际运营中采集的数据持续优化算法,现识别准确率基本可达到99%-99.9%;
(3)可实现实时远程库存管理,商品货损率极低;
(4)更适合大密度投放,获得规模运营效益。
同样,相比其他的技术方案,静态视觉方案也存在局限性:
(1)空间利用率低,柜内商品不能叠放,否则会在镜头前形成遮挡,影响识别准确率;
(2)需要对商品进行学习,数据采集及数据标注等流程较为繁琐,通常至少需要3-7天的时间完成。
2.4 重力+动态视觉
为进一步提高识别准确率,市场上还出现了重力感应+动态视觉的组合方案。经笔者调研了解到,该方案在实际的运营过程中,依旧以重力感应技术为主,视频监控仅在大单消费等极特殊情况下才会启用,本文将不再做详细介绍。
三、图像识别原理
目前应用比较广泛的智能柜大多以视觉识别方案为主。在上文分析过,视觉识别技术方案尤其是静态视觉方案已非常成熟,可以基于人工智能算法实现闭环式无人零售。下面笔者将继续剖析图像识别的实现原理。
3.1 图像识别原理
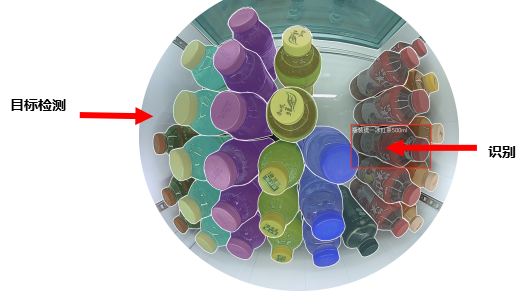
图像识别主要由两个步骤组成,首先是目标检测,其次是商品识别。
目标检测就是在照片中确定商品的位置,找到每个商品的像素区域。简单来讲,就是确定每个商品的边缘轮廓并进行标注,如图中所示,在每个商品的边缘画上白框即目标检测过程。
商品识别通过基于深度学习的算法来实现。深度学习就是采用卷积神经网络提取目标特征,再根据相同商品表现出来的共性总结出一定的识别经验值。将上图每个白框标注出来的待检测目标放入算法模型中,提取并比对商品特征点后,即可确定商品名称。
3.2 目标检测实现难点
理解了图像识别原理,笔者再以实例讲解技术应用难点。由于商品外形包装千变万化,消费者行为又难以控制,诸多因素都给技术落地造成了不小的障碍:

商品密集摆放
上图是静态视觉智能柜拍摄到的真实画面,鱼眼摄像头会造成图像畸变,尤其是当商品密集摆放或商品位于边缘区域时,将给目标检测、特征提取等造成障碍。

软包装商品难以精确检测商品边缘
与瓶装、盒装商品不同的是,软包装商品外形没有那么规则,很难清晰地区分单个商品的边缘轮廓,尤其是遇到上图所示的透明包装商品,在竖立摆放的情况下,很容易造成目标检测不准确,从而导致识别出错。
以上是几个较为直观的案例,可见单靠图像识别算法很难解决这类实际运营难题,此外还需要其他技术辅助,以一个更加全局观的视角分析并解决问题,方可提升智能货柜的稳定性。
四、智能柜产品测评
笔者走遍上海,对支付宝、深兰科技、海深科技、智购猫、嗨便利这五家智能货柜进行了实地调研,从结算时间、复杂场景识别稳定性等多个维度对智能货柜进行评估,结果如下:
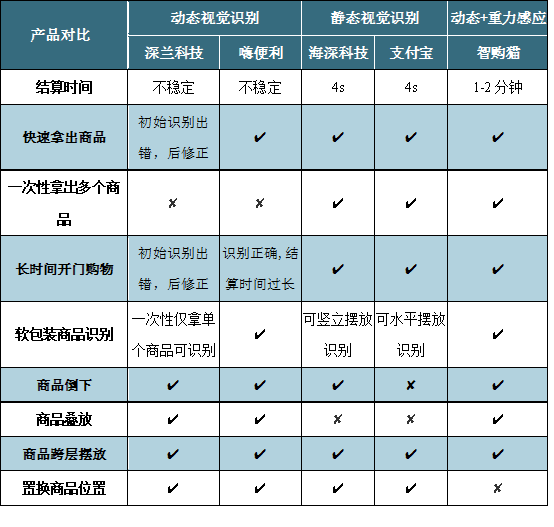
没有100%完美的技术方案,但针对不同的运营场景,必然有最具比较优势的解决方案。本文从智能柜实际运营的角度出发,分析了不同技术方案的应用特性,希望能帮助智能柜运营团队做出最适合自己的选择,为无人零售行业的智能化升级贡献一份力量。
感兴趣者可参考下方具体的产品测评视频:
https://www.bilibili.com/video/BV1Bz4y1D77u?from=search&seid=2895542164485255315
https://v.qq.com/x/page/e3113xwfgz7.html
或者在腾讯视频、哔哩哔哩搜索“智能货柜超全测评”关键词,获取更多详细信息!