9月18日,在2020云栖大会上,达摩院公布了语音AI技术的最新突破:端上语音识别和语音合成能力首次达到媲美云端的水平,这意味着未来个人用户在移动终端即可轻松体验逼近真人的语音技术。据介绍,达摩院最新的语音技术已在淘宝直播、钉钉会议、高德导航等场景大规模应用,正全面对外开放。
语音AI的核心是让机器听懂人话、并能开口说话,语音合成和语音识别技术是实现这些目标的基础。但由于过去几年业界在语音模型上未能有突破性创新,高精度的语音交互任务长期依赖云端算力,造成了语音指令处理不可避免的延时等问题。
此次达摩院率先在算法模型上实现创新,推出E2E-ASR端到端语音识别技术及全新的端上KAN-TTS语音合成技术,首次在移动终端上实现接近云端的语音识别与合成效果。
据介绍,在语音识别方面,达摩院提出SAN-M网络结构及基于SCAMA的流式端到端语音识别框架,提升计算效率的同时,还将高难度场景中的语音识别错误率降低近三成。达摩院研发的语音识别系统,可纯离线、低成本部署在手机端,原型系统不到40MB,识别效果媲美超过100GB的达摩院上一代DFSMN-CTC云端系统。
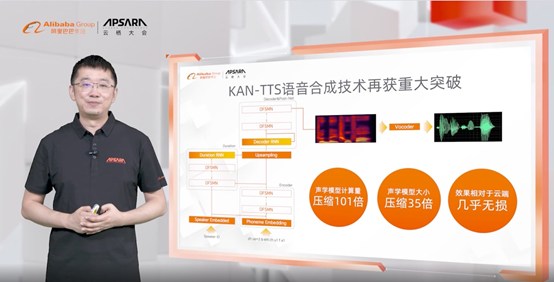
继去年发布仿真率可达97%的自研KAN-TTS语音合成模型后,达摩院此次在移动端实现了对语音模型的“大瘦身”,相比云端,端上模型大小压缩了101倍,计算量压缩35倍,通过终端算力即可快速复现逼近真人的语音。例如,高德地图近期发布了利用达摩院全新语音技术合成的李佳琦、林志玲、小团团等明星导航语音包,语音效果较之前更自然,断网状态下语音导航也不会中断。
达摩院语音实验室负责人鄢志杰表示,“在终端处理语音任务一直是学术界和工业界的难题,达摩院最新的语音技术有效释放了终端设备的能力,让终端也能轻松处理语音任务,我们相信,在终端算力和云端算力的协同支撑下,未来语音交互将无处不在。”
过去几年,阿里语音AI取得了一系列突破。2019年,阿里语音AI入选《麻省理工评论》“全球十大突破性技术”,是唯一上榜的中国科技公司;今年7月IDC发布的《中国AI云服务市场半年度研究报告》显示,阿里语音AI以44%的市场份额,在云上语音AI市场中位居第一。