2020年12月16日,在OpenShift TV上,先智数据(ProphetStor)CEO,Eric Chen和产品副总裁Ming Sheu接受了红帽高级首席产品营销官,Mike Waite的采访,畅谈先智数据的发展愿景与使命。

先智数据长期致力于基于AI的主动管理来解决混合多云环境中的复杂性并为客户带来创新价值。Ming还展示了Federator.ai与Datadog Monitoring Services集成的相关产品演示。
先智数据是家怎样的公司?
先智数据团队由一群在IT管理,基础架构和云运营,数据科学和AI技术方面具有专业知识的业内资深人士组成。我们的共同愿景是,IT基础架构和云服务的目标是确保可以满足应用需求,并且必须积极主动、预先部署以避免事后才反思。如果我们能够了解工作负载行为并在适当的时间用适当数量的资源来匹配需求,则可以使操作的复杂性最小化,节省成本以及优化性能。
这样做的理由是什么?
管理现有IT基础设施和云运营都是非常被动的任务,需要很多人的创造力。当我们引入容器化的应用,DevOps操作和新的多云范例时,情况变得更糟。此外,工作负载大多是动态的。跟踪,管理和优化具有挑战性,必须进行巨大的更改。
这里先智数据(ProphetStor)CEO,Eric Chen还分享了一个小故事:
多年前,我在一家联合创办的公司工作,那时我们派了一组工程师在远程客户站点上部署软件定义存储解决方案,花了两周时间完成,也赢得了要求严苛的客户称赞,是公司又一个新的成功案例。
一周后,我去拜访了一同处理这位客户案例的SI合作伙伴,没有料想的庆功宴,那家公司CEO告诉我,Eric,这个项目很棒,你的技术团队很厉害,客户很满意,我们赚了很多钱。但是,我想立即终止我们的分销商合同。
我很震惊。得到的回答是,“我的团队与您的技术团队一起工作,他们要精疲力竭地了解配置的细节,需要在每个步骤中都非常小心,连接电缆,获取正确的尺寸信息,密切关注应用的行为,而且很多时候,他们需要猜测满足SLA所需的资源。存储管理只和空间/容量有关,而与性能无关,无法解决我在操作中看到的主要问题,用你的产品机会成本太高了,必须有一种更自动化和智能的方法才行。”
多年后,当我离开以前的公司后,遇到了麻省理工学院教授同时也是企业家的Sunny Siu。开始谈论将应用意识引入存储管理,然后再引入IT和云。2012年,AI仍处于休眠状态。我们决定建立一家公司来引入AI/机器学习技术管理应用和资源,Sunny也成为投资者和公司总裁。我们的工作就是——借助AI技术以及Kubernetes,尤其是OpenShift中的主动管理方式以及如何在多云环境中进行性能和成本优化。
如你所见,我们专注于Kubernetes/OpenShift平台的次日运营( Day 2 Operation,算是新概念。简单来说就是当你完成初期的设施搭建,配置,测试并实现运行后,再对平台进行绝对优化,监视利用率,确保其可用性和成本优化),因为我们着眼于运营自动化和效率。我们认为,这些会是为了让大众广泛接受这个平台所需解决的主要问题。
用户角色担当
由于我们正在开发一种解决效率和成本问题的产品,因此用户角色是运营经理,CIO,CFO和CEO。 Kubernetes具有敏捷,高性能和灵活性。但管理也非常复杂。尽管如此,平台用途大于复杂性,因此,流行性迅速上升。
不过,简化部署至关重要,是第一阶段采用产品的重点。对我而言,Kubernetes和容器范例的最大好处是它向管理层提供的开放性和透明性。现在,我们能够观察到操作的详细信息,从应用到容器级别,再到基础架构,云操作,硬件组件,甚至CPU内核和DMA功能。
另一方面,对IT系统(如数据库,MongoDB,Postgress)和虚拟化平台(如Kubernetes),操作系统RHEL和硬件比如Intel或AMD CPU)都在提供产品方面表现出色,但都对水平层级施加了自我限制。结果,超出该特定层的任何内容,他们都选择不查看或优化。
也就是说,它们倾向于启发式和通用型。在Kubernetes/OpenShift平台中,自我限制是对创新的真正浪费。我们应该利用整个系统的透明度,从应用到系统,再到资源。然后引入一个好的编排器来匹配从应用到资源供应的需求。这就是为什么我们要做Federator.ai。
Kubernets/多云/OpenShift的市场格局
在最近的市场发展中,可以看到提供监控服务或解决方案的供应商变得非常受欢迎。工具包括Datadog,Dynatrace,Sysdig,Instana,SignalFX等。它们有助于解决Kubernetes和云平台中的“可视性”问题。几年前,容器监控解决方案还不够成熟。而且当你迁移数据到云时,除非订阅了监控服务,否则就没有在云上运行的应用和系统的可见性。因此,我们认为监控市场在不久的将来仍将有很高的需求。一个辅助证明是几周前,IBM刚刚收购了Instana。
接下来要解决的问题是安全性。我们可以在这类市场中看到一些活跃的供应商,例如Sysdig。
我们认为,下一个大趋势是涉及Day 2 Operation的第2阶段采用。在将工作负载部署到云之后,管理员将在性能和成本方面面临下一个运营效率问题。
很多经理在收到云账单时大为震惊。我本人就是受害者。我认为,如果没有良好的计划和对云计算的操作模型以及如何收费的正确理解,应用的性能以及在云上运行工作负载的成本可能不会达到预期。此外,多云环境还带来了另一种复杂性——选择最佳的定价计划来满足工作负载的SLA。现在,你还可以拥有多个云服务提供商。除此之外,一个服务提供商的每个数据中心都可能针对同一实例提供非常不同的定价。
因此,我们相信先智数据通过提供针对自动化,性能和运营成本的基于AI的主动管理解决方案可以为社区做出贡献。我们的解决方案与其他厂商的主要区别在于我们考虑了全栈式操作。
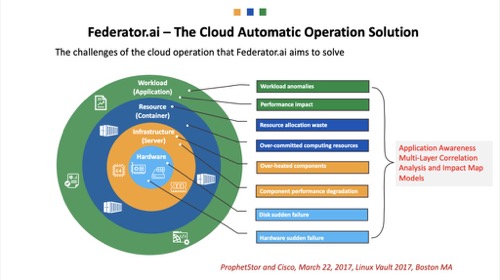
图1:Federator.ai –云自动化运行解决方案
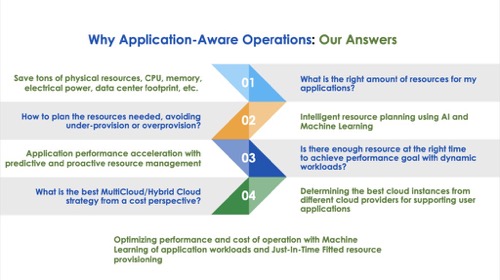
图2:为什么需要应用感知操作:我们的答案
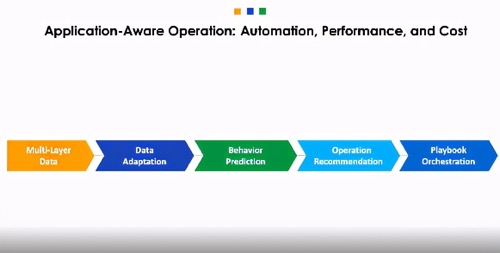
图3:感知应用的操作:自动化,性能和成本
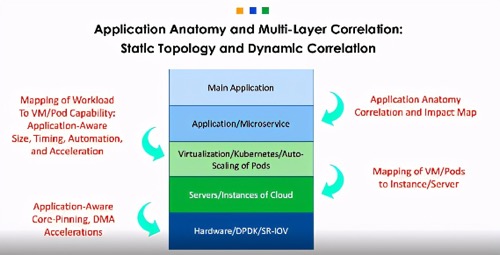
图4:应用剖析结构和多层关联:静态拓扑和动态关联
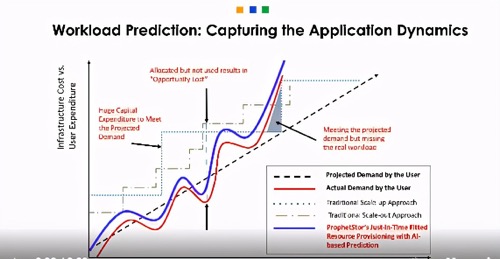
图5:工作负载预测:捕获应用动态
了解工作负载变化能帮助我们进行良好的资源规划。
Federator.ai允许用户观察Kubernetes或OpenShift集群中应用/资源在不同层级的工作负载预测。
通过对不同资源层使用不同的预测粒度和预测结果,用户可以更好地进行资源规划,以优化其性能和资源利用率。
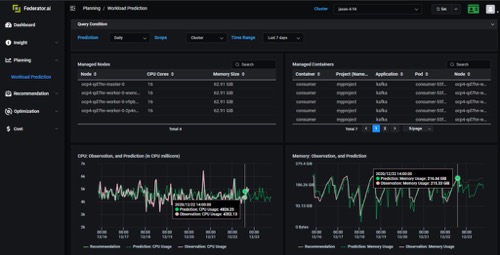
图6:工作负载预测现场演示
在大多数情况下,CPU或内存使用情况并不是衡量实际工作负载的良好指标。以Kafka分布式日志系统为例;你有很多Kafka生产者在一天内不同时间以不同的价格向Kafka代理商发送消息。代理商要确保自己有足够的Kafka用户的同时,还要及时接收和处理这些消息,不会造成大的延迟。 Kafka使用者的CPU使用率并不是最好的工作负载指标。在这种情况下,来自生产者消息的生产率是正确的工作负载指标。借助Federator.ai预测适当工作负载的能力,我们可以动态扩展Kafka使用人数,以便在适当的时间为适当数量的使用者提供服务。
当我们可以预测到动态工作负载时就是能提供操作的绝佳示例。
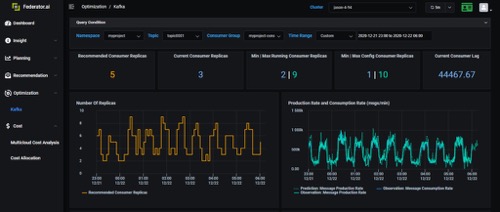
图7:感知应用的工作负载预测和自动扩展或收缩的实时演示
当我们完全了解未来工作负载并将其用于适当资源时,我们将获得更多的收益。比如你可能正在考虑将当前的本地集群迁移到公有云。了解未来的工作负载能帮助你选择最经济高效的正确实例,并同时处理集群的工作负载。
如果你已经是AWS的客户,仍然可以用Federator.ai的分析来获取建议,说明哪些地区的实例类型可以降低成本。Federator.ai为您提供基于按需,保留甚至SPOT实例的成本估算的不同方法。
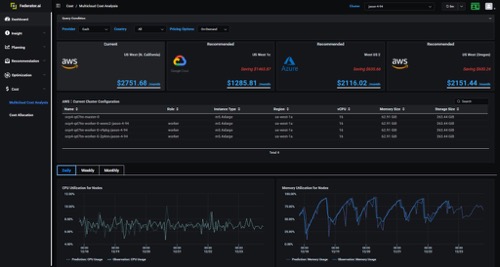
图8:多云成本分析实时演示
Federator.ai可以进一步分析应用的使用情况和预测,以在下一个级别了解不同应用上的费用。
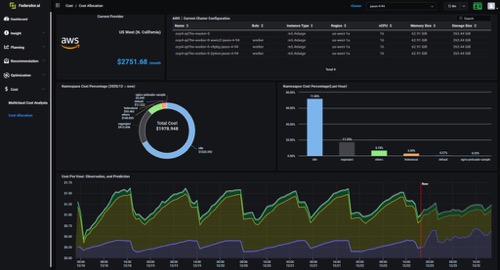
在此示例中,你可以看到集群超额配置时,系统在空闲状态上浪费了多少。 Federator.ai为你提供有关哪些实例类型和集群大小的建议,这些实例可以通过工作负载预测来优化成本。