
全球人工智能领域的顶级学术会议AAAI 2021将于2月2日-9日在线上召开。论文录用结果显示,华为云的7篇AI科研成果被收录。论文内容涉及联邦学习、深度学习、机器学习、自然语言处理、迁移学习、知识计算等技术领域,充分展现了华为云在人工智能领域的基础研究实力。技术创新和应用落地是这些论文的亮点,相关技术目前已在油气勘探、药物研发、AI开发、智能交通等业务场景下规模化落地,加速行业智能升级。
AAAI每年评审并收录来自全球最顶尖的人工智能领域学术论文,代表全球AI技术的趋势和未来。
以下是华为云此次入选7篇论文介绍:
论文一:业界首创自分组个性化联邦学习框架,并已落地华为云ModelArts
论文标题:《非独立同分布下的自分组个性化联邦学习》(Personalized Cross-Silo Federated Learning on Non-IID Data)
论文地址:https://arxiv.org/abs/2007.03797
联邦学习机制以其独有的隐私保护机制受到很多拥有高质数据的大客户青睐。但是,各大客户的数据分布非常不一致,对模型的需求也不尽相同,这些在很大程度上制约了传统联邦学习方法的性能和应用范围。华为云自研FedAMP联邦学习框架使用独特的自适应分组学习机制(如图一)让拥有相似数据分布的客户进行更多合作,并对每个客户的模型进行个性化定制,从而有效处理普遍存在的数据分布不一致问题,并大幅度提高联邦学习性能。通过与中国科学院上海药物所在AI药物联邦学习上的合作,FedAMP优质的性能获得了蒋华良院士的高度认可,并在中国医药创新与投资大会上吸引了众多医疗制药厂商洽谈合作。

图1 FedAMP联邦学习框架
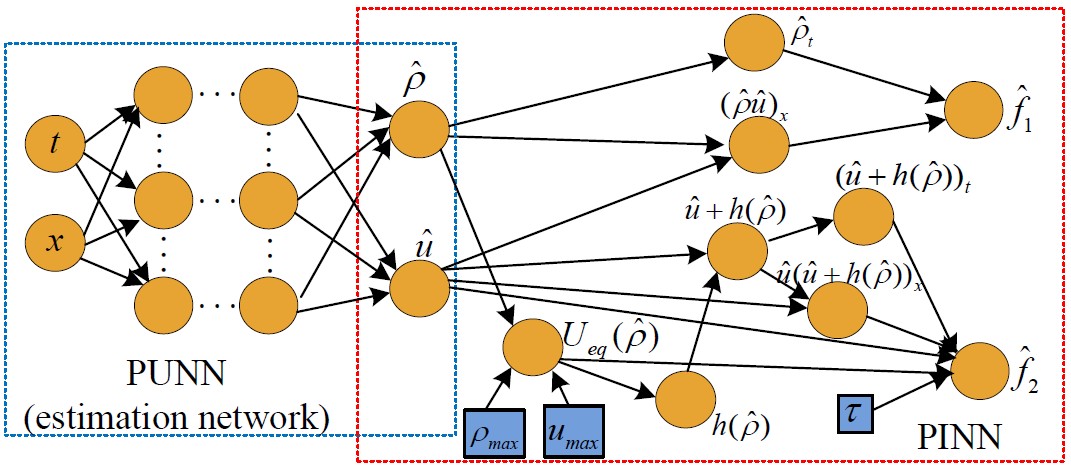
论文二: 首次提出利用物理信息深度学习的框架将二阶交通理论模型融合到神经网络中,以高效解决交通态的估值的问题:(Physics-Informed Deep Learning for Traffic State Estimation: A Hybrid Paradigm Informed By Second-Order Traffic Models)
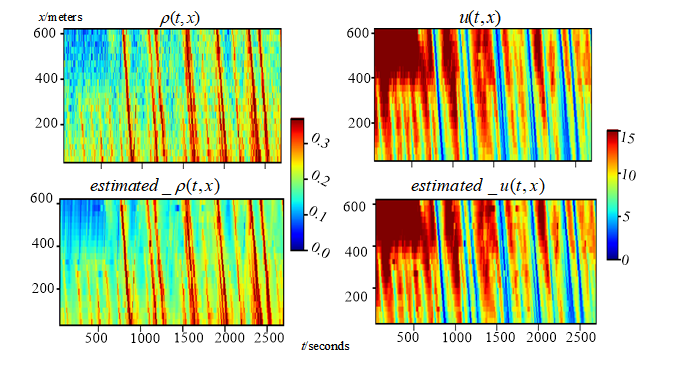
交通态的估值需要解决如何使用稀疏的传感器(如传感线圈,浮动车)数据将整条道路的交通态(如速度,流量,密度)完整地估计出来。这对算法的数据效率有着非常高的要求,而传统的纯交通模型和纯机器学习的解决方案的效果均不理想。针对这些问题,本论文提出了基于物理信息深度学习框架,通过对激励函数和连接权重的特殊设计,将复杂的二阶交通模型编码到神经网络中去(图二-a),让神经网络在高阶交通理论的约束下进行训练。具体方法是,使用传统神经网络进行交通态的估值,然后将估值进一步输入到物理信息神经网络中去,计算出该估值的理论余量来量化偏移交通理论的程度。这个理论余量为估值网络的训练提供了重要的正则化信息,大大提高了估值模型的训练效率和估值精度。如图(图二-b)所示,本方法可以基于很少的观测数据获得更高的估值准确度。
本文是华为员工在哥伦比亚大学深造期间完成的工作。
(a)
(b)
图2 编码了二阶交通理论模型的物理信息神经网络与交通态估值结果
论文三:使用图卷积网络拟合权值共享神经结构搜索的搜索空间,提升神经结构搜索鲁棒性。(Fitting the Search Space of Weight-sharing NAS with Graph Convolutional Networks)
论文地址:https://arxiv.org/pdf/2004.08423.pdf
权值共享的神经结构搜索通过训练一个包含所有分支的超网络来复用不同操作上的计算量,以子网络采样的方式评估网络结构,大幅度提高了搜索速度。然而,这种子网络采样的方式并不能保证子网络的评估性能准确反映其真实属性。本文认为产生这一现象的原因是使用共享权值构建子网络的过程中产生了权值失配,使得评估性能中混入了一个随机噪声项。本论文提出使用一个图卷积网络来拟合采样子网络的评估性能,从而将这个随机噪声的影响降至最低。实验结果表明,使用本方案后,子网络的拟合性能与真实性能间的排序相关性得到有效提高,最终搜索得到的网络结构性能也更加优异。此外,本方案通过图卷积网络拟合了整个搜索空间中子网络的评估性能,因此可以很方便地选取符合不同硬件约束的网络结构。
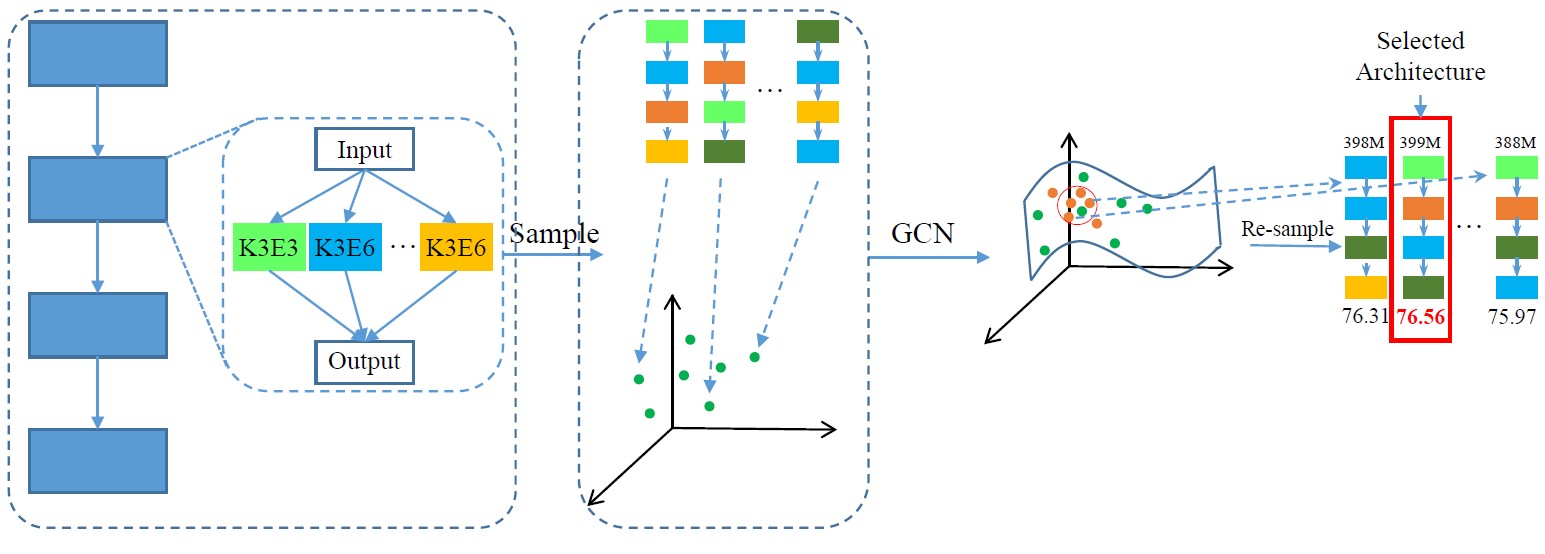
图3 总体框架示意图
论文四:首次提出基于多轮阅读理解的框架解决实体链接问题
实体链接是将文本中提到的实体链接到知识库中对应实体的任务,目的是解决实体存在的歧义性问题,但由于名称的变化和实体的模糊性,此任务十分具有挑战性,尤其是短文本的实体链接,由于句子长度短,在链接过程中,每个待消歧的实体能利用的上下文信息非常有限。针对这个任务,本论文提出了一个多项选择阅读理解的框架,为句子中每个待消歧的实体分别生成一个问题,并将知识库中的候选实体转换成候选答案集,通过这样一个设计,实体链接转换为了一个阅读理解的问题(图1 Local部分)。在选择正确答案的过程中,待消歧实体的上下文信息与知识库中的候选实体之间获得了充分的交互,同时多个候选实体间的区别也得到了潜在地考虑。为了进一步捕捉句子内待消歧实体间的主题一致性来提高链接的准确率,本文采用了多轮阅读理解的方式以序列去处理多个待消歧的实体(图1 Global部分),为句子内多个实体的消歧提供了更丰富的信息。另外,为了解决短文本中常见的不可链接问题(即知识库中没有对应的实体),本文额外设计了一个两阶段的验证机制来判断实体是否可被链接。本论文提出的方法在多个中英文数据集上均取得了目前最优的实体链接效果。
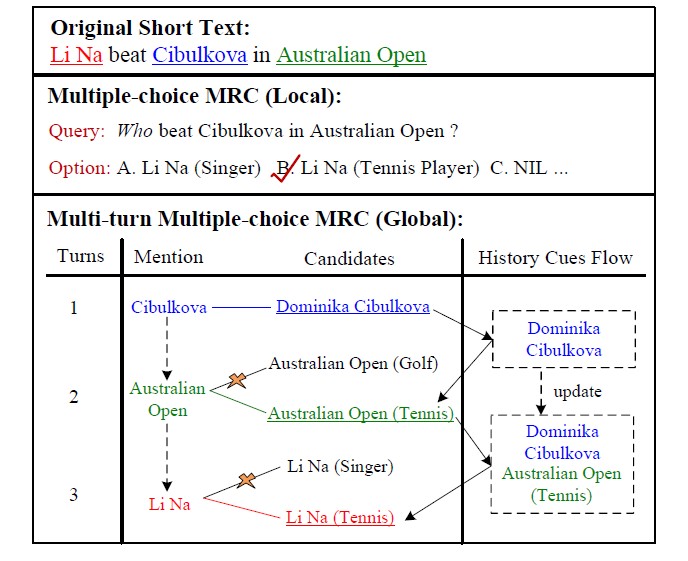
图4 基于多轮阅读理解的实体链接框架
论文五:首次提出基于多尺度地质知识迁移的跨区块油气储集层分类算法,利用迁移学习提升跨区块油气储集层分类效果。(Cross-Oilfield Reservoir Classification via Multi-Scale Sensor Knowledge Transfer)
油气储集层分类是油气勘探中的一个关键步骤(如图一所示),自动准确的油气储集层分类方法不仅可以降低油气行业专家的工作负担,也可以帮助油气勘探公司做出最优的开采决策。当前已有的油气储集层分类主要关注在单一区块上的分类效果,但是在新区块上应用效果却不尽如人意。因此,如何迁移地层特征从而实现跨区块也能准确分类是一个富有挑战的任务。本论文首次提出了一种多尺度传感器抽取方法从多元测井记录中抽取地质特征的多尺度表示,然后设计了一种encoder-decoder模块来充分利用目标和源区块的特有特征,最后通过一个知识迁移模块来学习特征不变性表示,从而将地质知识从源区块迁移到目标区块。真实油气数据上的实验结果表明本论文精心设计的迁移学习方法,可以提升分类模型在新区块上的分类表现,相较于基线算法可以有%6.1的效果提升。

图5 油气勘探工作流
论文六:首次提供基于超几何分布的概率模型,用于解决远程监督命名实体识别中的去噪问题。(Denoising Distantly Supervised Named Entity Recognition via
a Hypergeometric Probabilistic Model)
远程监督是一种常见的机器学习范式,可以降低对标注数据的依赖。但是远程监督往往会引入噪声,从而影响学习效果。对于基于远程监督的命名实体识别(NER)来说,如何有效去噪就是一个十分重要的问题。以往的去噪方法主要基于实例层次的统计结果,往往忽略了不同数据集不同实体类型之间噪声分布的差异性,从而导致这些方法何难适用于高噪声比例的设定。本论文提出了一种基于超几何分布的学习方法,同时考虑噪声分布和实例层次的置信度。具体而言,我们将每个训练batch里面噪声样本的数量建模成一个由噪声比例决定的超几何分布,这样一来每个实例都可以通过上一轮训练获得的置信度来决定是噪声还是正确样本。实验结果表明本论文提出的方法可以有效去除远程监督范式引入的噪声,显著提升NER的效果。

该工作由华为云团队与中科院软件所合作完成。
论文七:提出基于对抗学习与相似性增强的域泛化训练新框架,在域泛化行人再识别领域创下新纪录 (Dual Distribution Alignment Network for Generalizable Person Re-Identification)
域泛化是一种适用于现实应用场景的机器学习范式,对于行人再识别问题,域泛化是指在大规模多源数据上进行模型训练,期望模型在任意未知的场景中都能够直接适用。现实应用中,大规模训练数据往往难以收集,域泛化方法正是一个使得模型能够低成本快速部署的优秀方案。以往的方法对域间的巨大差异缺乏有效的处理手段,同时忽略了域间样本可能的相似性信息。在数据域层面,本论文提出了新的对抗学习方法,通过减少中心域与外围域的差异,实现了域间差异的有效消除;在样本层面,本论文通过增强来自不同域的相似样本之间的相似性,进一步对齐来自不同域的样本特征分布。在这两个方面的共同作用下,本论文的双重分布对齐网络实现了新的性能突破。实验表明,所提方法在公共测试基准数据集上取得了当前最好的结果。
该工作由华为云团队与厦门大学合作完成。
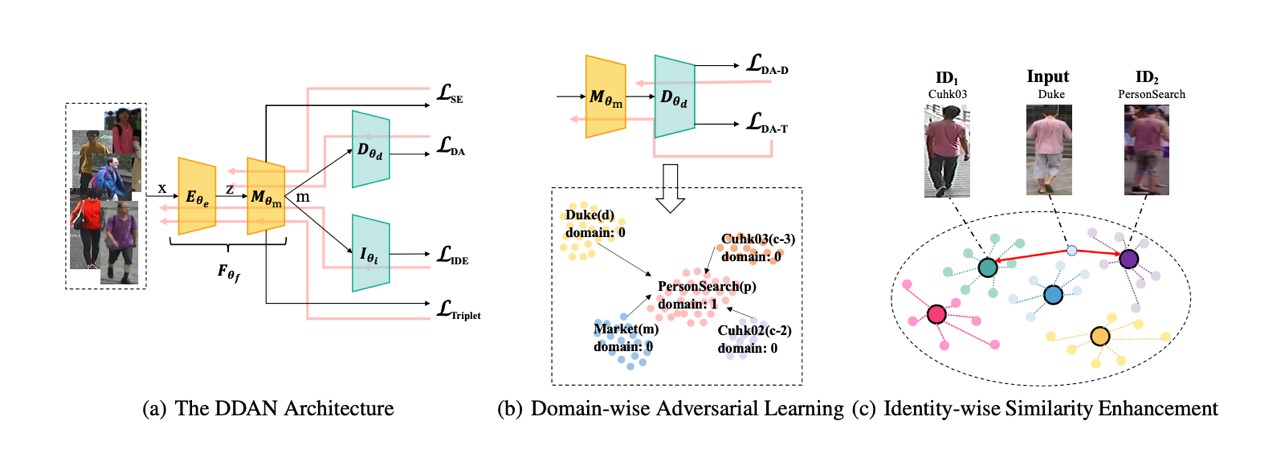
图7 针对域泛化行人再识别问题的双重分布对齐网络示意图
为了更好地赋能产业升级,华为云持续深耕AI基础研究和落地应用,打造更懂世界的AI。2020年以来,华为云EI研究团队已在图像分类、弱标注场景下的图像分类、图像检测,多模态数据处理、语音语义等领域取得多项世界第一。未来,华为云将持续把AI前沿算法产品化,并开放给各行业的AI开发者使用,通过技术创新驱动产业智能升级。







