
Beta版BIOS的升级破坏了与ESX的兼容性,因此我们将对四核CPU AMD 8384系统所做的虚拟化测试进行推迟。
现在我们进行一个对45纳米Opteron、Xeon以及Core i7处理器的深度比较。在我们的测试指标中,著名的LINPACK描绘了一副美丽有趣的性能图画。因为我们仅仅拥有3GB的DDR-3内存在Core i7平台上,所以仅使用矩阵大小为18000的标准进行测试(需要2.5GB的RAM)。这在我们仅仅测试一个CPU时是一个巨大的问题。实际的正常情况下,针对每一个四核CPU来说,我们需要4GB的内存才可以达到更好的性能。
我们同样适用Intel的9.1版本的LINPACK,因为我们想在同样的平台上使用同样的二进制代码。正像我们前面所展示的那样,当矩阵很小时,这个版本的LINPACK在AMD和Intel的平台上都表现的很好。不幸地是,当前的LINPACK 10.1版本在AMD的CPU上还不能工作。
我们可以毫不掩饰的说,这种比较是相对公平的:Nehalem的平台使用没有缓冲的RAM,它会比起Xeon"Nehalem"有更低的延迟和更高的带宽。但是,我们必须要满足我们的好奇心:新的AMD Shanghai处理器和Nehalem比较的结果又如何呢?

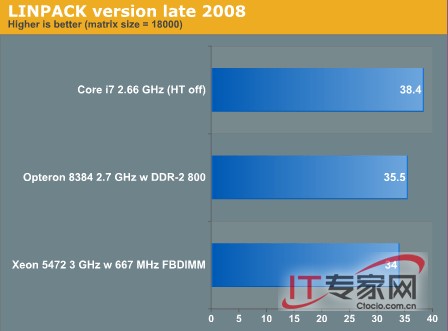
看一下结果吧!超线程(SMT)给予了Nehalem核心巨大的优势在多线程的应用程序中,但是在Linpack却并不是这样:它使得CPU的速度降低了10%。难道我们找到了第一个多线程应用程序,它通过Nehalem上的超线程反倒速度降低了?这并不会破坏Intel测试结果带给我们的乐趣,因为很多其它的HPC测试结果都表现出了突出的结果。AMD在市场方面确实领先了一部,基于Xeon的Nehalem几个月后发布。
同样,内存子系统的影响是有限的,就像50%内存方面的增加只会带来性能上6%的增长。而Math 内核库很好的被优化,使得内存速度的影响变得微乎其微。Nehalem三通道的DDR-3内存系统确实给了很好的补偿,这对于其它HPC应用来讲是一个很好的对比。
这里要澄清一下,本文并不是一篇导购文章,并不能说明处理器的优劣。Nehalem桌面系统和AMD Shanghai服务器是完全不同的机器,它们的对象也是针对完全不同的市场。正常情况下,我们应当等待Xeon 5500来跑这些测试,但是考虑到这是出于好奇心的提前比较,我们就做了这个测试。
我们并没有试图让这两种架构都获得最高可能的LINPACK分数。我们想使用同一个二进制代码,该代码对于AMD和Intel的CPU作了最好的优化。完全优化的二进制代码甚至不能在其它CPU上运行。我们唯一的目标就是得到一种想法:得到Nehalem和Shanghai架构运行一个 LINPACK二进制代码时的一个比较结果,而这部分代码也被优化可以运行在所有的机器上。AMD上的MKL?
使用Intel的Math内核库在AMD的CPU上运行是一个很好的方法来促使一些激励的争辩。但是,在某些例子中,当你的测试使用小矩阵模型时,老一些的MKL版本仍然在AMD的处理器上工作的很好,你当然不必把我的话放在心上。
把Intel Linpack 9.0(2007年中旬发布)和AMD在2007年底给出的二进制代码做一个对比。AMD只做出了一个K10版本,使用ACML版本4.0.0,并且使用 PGI 7.0.7编译器来编译Linpack(使用参数:pgcc -O3 -fast -tp=barcelona-64)。
以下所有的指标都在是带有4GB(AMD,Intel Xeon)或者3GB(Intel Core i7)内存的CPU上得到。SpeedStep、Powernow!以及Turbo模式都已经禁用。
LINPACK: Intel Nehalem VS AMD Shanghai
就像预计的那样,使用2007编译器得到的ACML二进制代码比起2007年编译的MKL 2007版本要慢一些。MKL版本可以运行在所有支持SSE-3 的CPU上,因此,它对于我们来讲也是一个非常有意思的测试。就像你从Xeon 5472(3GHz)分数中看到的那样,这部分代码并没有在使用SSE-4的最新的45纳米的Intel CPU中被优化。它是一个很好的但没有被优化的版本,可以被使用到Intel和AMD的CPU上。你可以很清楚地看到这一点,因为3GHz的Xeon 5472落后于AMD的Opteron 8384。如果Intel的二进制代码给AMD的CPU一个很差优化的代码时,得到这样的结果就是不可能的。
当我们来到2008时,就必须创建一个新的二进制代码,让AMD和Intel完全优化的Linpack版本不能够运行在其它竞争者的CPU上。 Intel发布了Linpack benchmark版本10.1,它并没有针对Nehalem架构进行完全地优化,但是对于45纳米的Harpertown一族却做了优化。
AMD已经创建了一个新的Linpack二进制代码,使用ACML 4.2和PGI 7.2-4编译器。以下,你就可以看到这两个CPU之间的一个比较:
底线就是这些LINPACK测试正在转向像SPEC CPU测试那样的目标,而编译器和所使用的库和CPU一样同等重要。当Xeon 5500实例化后,LINPACK的性能可能会更高,因为二进制代码是为Penryn/Harpertown一族CPU而建立。
对于高性能计算机的人们来说,哪一个CPU+编译器更能提供好的性能是非常有用的,但当你编译二进制代码,而这些代码还必须在当前所有的CPU上运行时,对于你能理解得到的性能结果也是非常有趣的。而如果你使用完全不同的二进制代码时,你就很难比较CPU的架构了。







