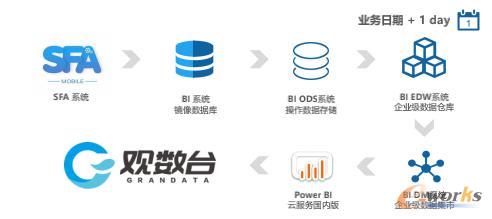
商业智能的成功很大程度上依赖于数据展现和分析工具即前端工具。如果最终用户不能通过前端工具方便地回答关键的业务问题,那么无论数据仓库设计得多么梢巧,也不能称为成功。如今越来越多的衫呐已开始着手建立独立于业务系统之外的、面向分析应用的数据集市或更大规模的数据仓库,负责建立数据集市或数据仓库的小组通常要同时负责确定商业用户使用的查询、报表和分析技术。但是在建立过程中并不是所有的需求都是明确的,某些需求直到用户使用数据仓库时才会了解,而另外一些需求可能要到很久以后当其他一些数据集市建立起来时才可能提出。
针对这类问题,选择合适的前端工具将会带来明显的短期和长期效益。一个好的前端工具应具有以下特点:①易于使用和灵活设置;②聚合感知;③贯通主题领域;④克服sQL的限制;⑤访问并使用多种不同的数据源;⑥集成的分析功能。
1 前端工具在查询方面的特性
1.1 易于使用
借助先进的前端工具,设计员可以设置一个查询环境,其中包括一系列的对象,每一个对象通过一些SQL语句和数据库中的某些属性相连。这些SQL语句可以是表中的字段名称,也可以是一些SQL聚合函数。借助这些对象,用户可以很容易的建立自己的查询。
前端工具应该非常容易使用。因为所有的元数据对商业用户都是屏蔽的,最终用户建立一个查询的过程仅仅是简单地将需要的对象挑拣出来。工具使用这些对象的元数据自动生成一个SQL语句,发送到数据库中,并将查询结果取回并生成报表。
1.2 炙活性
前端工具应该能灵活地将数据仓库的数据展现到用户面前。业务用户会被度最表和维表围绕的星型结构弄糊涂,前端工具要能够帮助他们简化使用这些数据库,例如隐藏主键和外键。如果在组中的有些维并不对应物理上的表,前端工具可以将这些维简化或微观化;如果数据库中没有一些业务对象的相应字段,前端工具应该可以生成。
先进的前端工具通过使用语义层技术适应这些需要:用于将简单的面向业务的对象确译成SQL语言的元数据称为语义层,它存储在一个关系型的资料库中,资料库中还存储表之间的连接信息、为多路径查询建立的表的别名信息以及聚合表的信息。
语义层将数据库的物理设计翻译成最终用户熟悉的商业术语,同时允许将特性按照最终用户的逻辑需要重新定位组织起来。例如,很多星型结构将维特性存储在主表中,而不是维表。简化维时,维特性被放置在主表中,在它们自己的维表中没有其它的维特性可以伴随。开发者因为功能或易于调用数据的需要,通常将一个维划分为尺度上更加微观的维。利用前瑞工具,这些微观维可以聚集为一个维对象组。
2 前端工具的聚合导航功能
当定义一个查询和报表工具时,仅仅简单地从数据仓库中获得数据是不够的,还应使查询数据需要的时间在要求的范围内。尽管定义的工作盆不大,但实际数据仓库却可能非常大,具有上百万甚至上千万条记录的主表是常见的。因为主表很大(通常会越来越大),查询的性能将自然地降低。加强性能的典型办法是从硬件和软件解决问题,更换数据库厂商,增加或侧除索引,收效最大的方案是聚合导航。
使用小量的元数据,聚合导航可以使用合适的聚合表查询数据自动重写查询。用户可以不必理睬采用何种聚合表,这个工作由聚合导航在后台处理。从用户的角度来看,聚合导航可以决定从最佳位置读取数据。
在以后的几年里,聚合导航功能可能会成为关系数据库的功能,但就目前而言,基于关系数据库的聚合导航尚未实现。所以数据仓库小组要么设计、建造和维护他们自己的聚合导航,要么选择使用具有聚合导航功能的前端工具。比如用户按照季度访问"销售额"对象时,具有聚合导航功能的前端工具所产生的SQL语句将直接从已有的聚合表中提取数据;而当用户又增加了销售定单维时,前端工具可以直接到主表中查找数据,用户只须知道他要访问销售额,而无须自己去选择访问数据的方法。
3 前端工具的透明交叉查询特性
考虑下面的业务需求?一个财务计划人员问"我们1月份的预算和实际柑比,情况怎样"?与其它重要的业务需求一样,这个问题不能通过查询一个星型结构来实现,而会牵扯到两个独立的星型结构,一个代表预算,而另一个代表实际花费。这个查询将在两个分开的星型结构中进行,它们和其它的公共维表相连接,这类查询通常称为交叉查询。将这个问题翻译成SQL查询是比较困难的。不幸的是很多前端工具生成了SQL语句。这种查询即使能够返回数据,也会产生不正确的查询结果。没有使用外连接,可能丢失数据;一个不必要的表引入了查询;查询可能得不到结果,因为数据库无法优化对这两个数据量极大的表的查询。正确的方法是通过两个SQL查询,两个查询结果在客户端通过它们的公共因素连接到一起。这个业务问题代表了选择前端工具的两个问题:①前端工具必须能够识别何时使用多个SQL查询;②前端工具必须能够将多个SQL查询结果融合到一起,不是使用union方式,而是使用本地外连接。
好的前端工具必须检测当前的环境以便决定是否需要两个或多个SQL查询,并分别独立地执行这些查询,将结果集结合起来,自动生成结果,不需要最终用户了解更多的知识。比如针对上面的业务需求,前端工具将自动产生两个查询SQL来访问"预算"和"实际花费"两个星型结构。执行了这个查询并分析了结果之后,连接到一起,输出了报表。业务用户完全不用关心所有的其它工作,他们也不需要看到生成的SQL。
4 克服SOL的限制
不能通过SQL语言回答的一类问题是"交叉查询",这个问题要求多条SQL查询和一些后处理,通过先进的前端工具可以解决这个问题。在对查询结果做名次排列、计算累计汇总或做多级聚合时,SQL也暴露出了短处。例如要求BI业务人员按照季度对销售作累计,并且每年从零开始累计,这是一个常见的、用SQL语言很难实现的例子。
先进的前端工具可以提供丰富的计算功能,用于处理SQL语言所不能完成的工作。通过工具条按钮和像电子表格软件那样的公式条,前端工具在SQL查询结束后对文档中数据作丰富的计算。例如上述的问题可以使用前端工具中累计汇总公式功能解决,在按照月和年显示的简单报表中应用这个公式将可以直接地回答一些业务问题。
5 融合多数据源
好的前端工具不将用户限制到只能以单次查询的返回数据为基础创建报表,同时也允许在一个文档中使用不同类型的数据源。用户可以将诸如以下的访问方式混合使用:
(1)利用语义层和简单查询技术访问一个数据集市中的数据,甚至可以查询存储在两个宪全不同数据库中的不同的数据集市,并将查询结果合并到文档中。例如销售数据在R司brick数据库中,而发货数据在oracle数据库中,用户可以将数据集成到一起,无须投资使用网关技术。
(2)用户使用他们自己编写的SQL程序,并将结果连接到文档中的其它的数据源结果中。
(3)使用存储过程提取数据。
(4)用户可以将他们在Ecxel或Lotsu中的数据调进前端工具文档中。
(5)如果已经投资建立了一个oLAP引擎,前端工具可以直接使用它,并能将数据集成到自己的文档中。
6 集成的分析
一个好的前端工具要提供分析能力,而不需要开发商的持续支持。即允许用户采用旋转、切片和钻取等手段分析数据,而不用受预先定义好的分析层次的限制。比如说用户可能观察在二维表中所显示的销售额时,发现有一个机构的销售额较高。他们只需要将光标移动到需要观察的机构上,就会出现一个"工具提示"指示如何钻取到机构级别的其它层次的数据。使用同样的方法,用户可以在一个交叉表或统计图中使用钻取。