
作者:Vlad Ilyushchenko,QuestDB的CTO
在QuestDB (https://questdb.io/, https://github.com/questdb/questdb),我们已经建立了一个专注于性能的开源时间序列数据库。我们创建QuestDB初衷是为了将我们在超低延迟交易方面的经验以及我们在该领域开发的技术方法带到各种实时数据处理用途中。
QuestDB的旅程始于2013年的原型设计,我们在去年HackerNews发布会期间(https://news.ycombinator.com/item?id=23975807)发表的一篇文章中描述了2013年之后所发生的变化。我们的用户在金融服务、物联网、应用监控和机器学习领域都部署了QuestDB,使时间序列分析变得快速、高效和便捷。
什么是存储时间序列数据的最佳方式?
在项目的早期阶段,我们受到了基于矢量的append-only系统(如kdb+)的启发,因为这种模型带来了速度和简洁代码路径的优势。QuestDB的数据模型使用了我们称之为基于时间的数组,这是一种线性数据结构。这允许QuestDB在数据获取过程中把数据切成小块,并以并行方式处理所有数据。以错误的时间顺序到达的数据在被持久化到磁盘之前会在内存中进行处理和重新排序。因此,数据在到达数据库中之前已经按时间排序。因此,QuestDB不依赖计算密集的索引来为任何时间序列的查询重新排序数据。
这种liner模型与其他开源数据库(如InfluxDB或TimescaleDB)中的LSM树或基于B树的存储引擎不同。
除了更好的数据获取能力,QuestDB的数据布局使CPU能够更快地访问数据。我们的代码库利用最新CPU架构的SIMD指令,对多个数据元素并行处理同类操作。我们将数据存储在列中,并按时间进行分区,以在查询时从磁盘中提取最小的数据量。
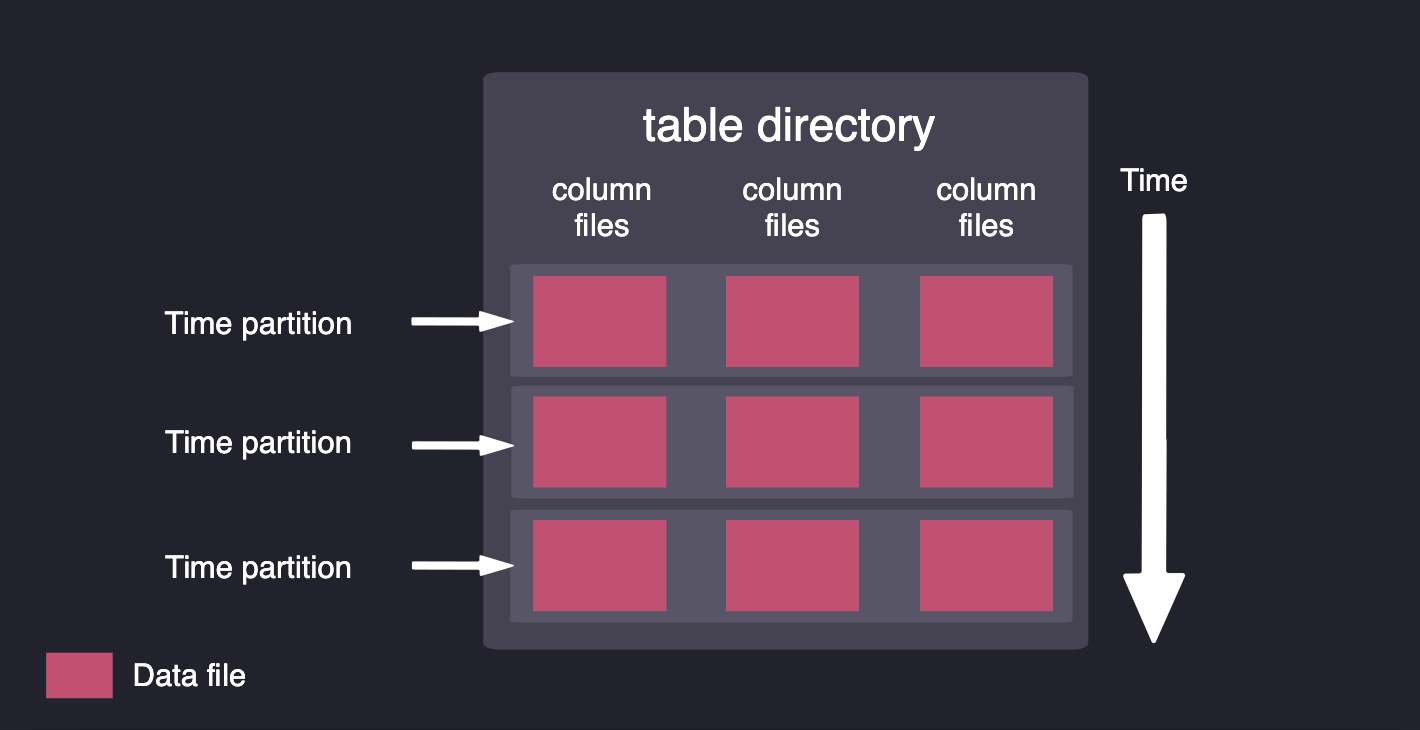
数据被存储在列中,并按时间进行分区
QuestDB与ClickHouse、InfluxDB和TimescaleDB相比如何?
我们看到时间序列基准测试套件(TSBS https://github.com/timescale/tsbs)经常出现在关于数据库性能的讨论,因此我们决定提供对QuestDB和其他系统进行基准测试的能力。TSBS是一个Go程序集,用于生成数据集,然后对读写性能进行基准测试。该套件是可扩展的,因此可以包括不同的用例和查询类型,并在不同系统之间进行比较。
以下是我们在AWS EC2 m5.8xlarge实例上使用多达14个worker的纯cpu用例的基准测试结果,该实例有16个内核。
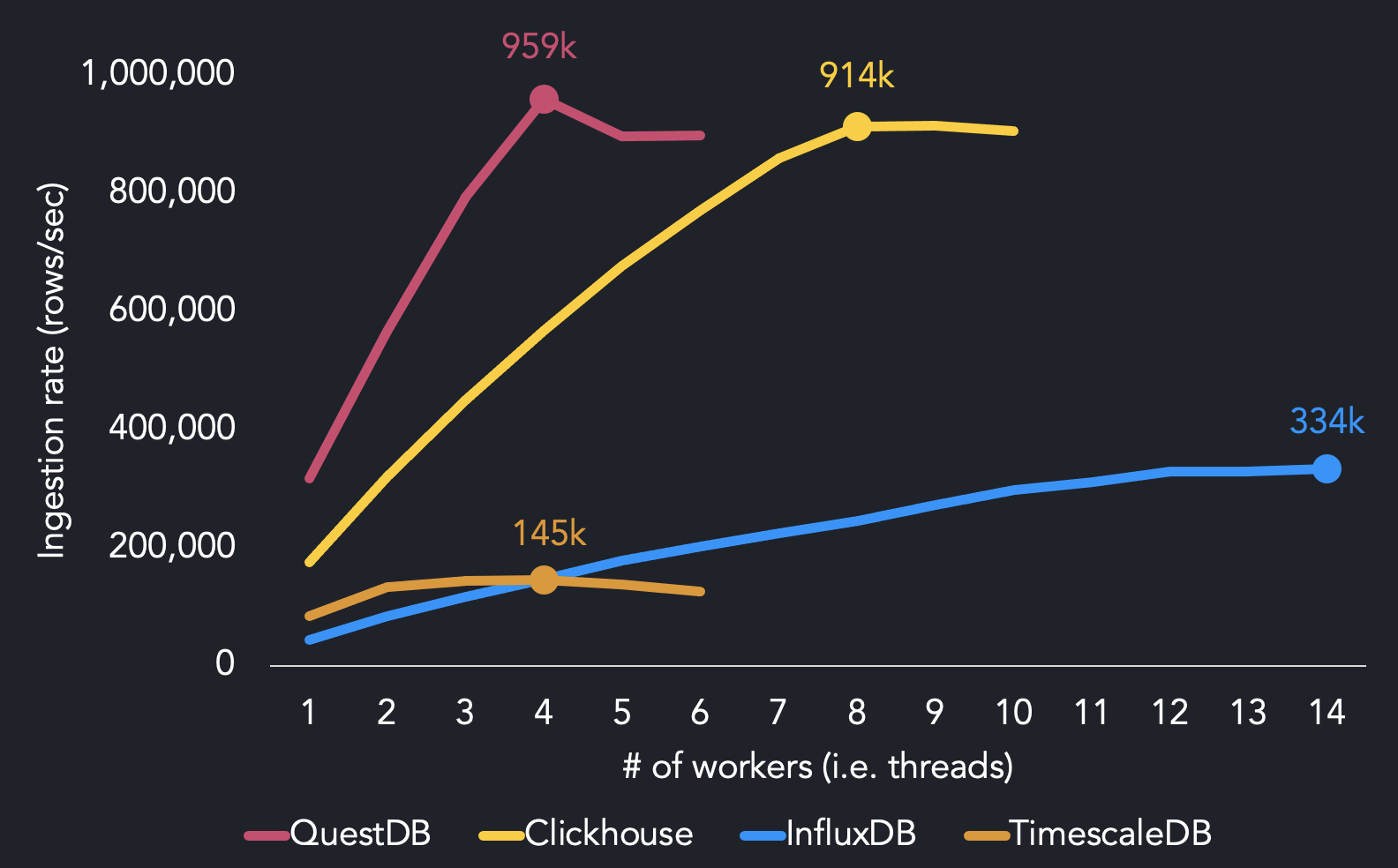
TSBS结果比较了QuestDB、InfluxDB、ClickHouse和TimescaleDB的最大获取吞吐量
我们使用4个worker达到最大的摄取性能,而其他系统需要更多的CPU资源来达到最大的吞吐量。QuestDB用4个线程达到了95.9万行/秒。我们发现InfluxDB需要14个线程才能达到最大的摄取率(334k行/秒),而TimescaleDB用4个线程达到145k行/秒。ClickHouse以两倍于QuestDB的线程达到914k行/秒。
当在4个线程上运行时,QuestDB比ClickHouse快1.7倍,比InfluxDB快6.5倍,比TimescaleDB快6.6倍。
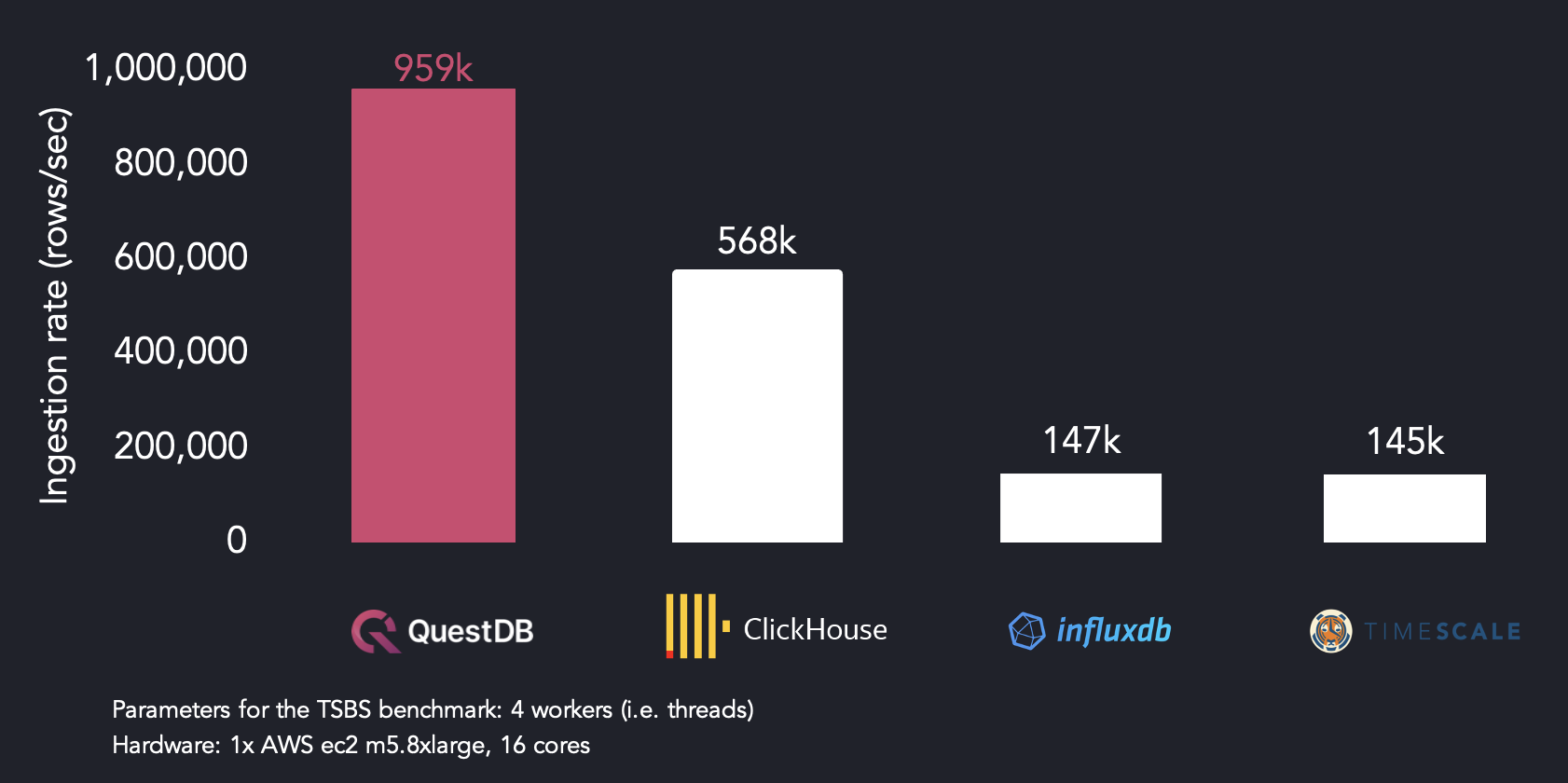
使用4个线程的TSBS基准测试结果:QuestDB、InfluxDB、ClickHouse和TimescaleDB每秒获取的行数
当我们使用AMD Ryzen5处理器再次运行该套件时,我们发现,我们能够使用5个线程达到每秒143万行的最大吞吐量。与我们在AWS上的参考基准m5.8xlarge实例所使用的英特尔至强Platinum相比:
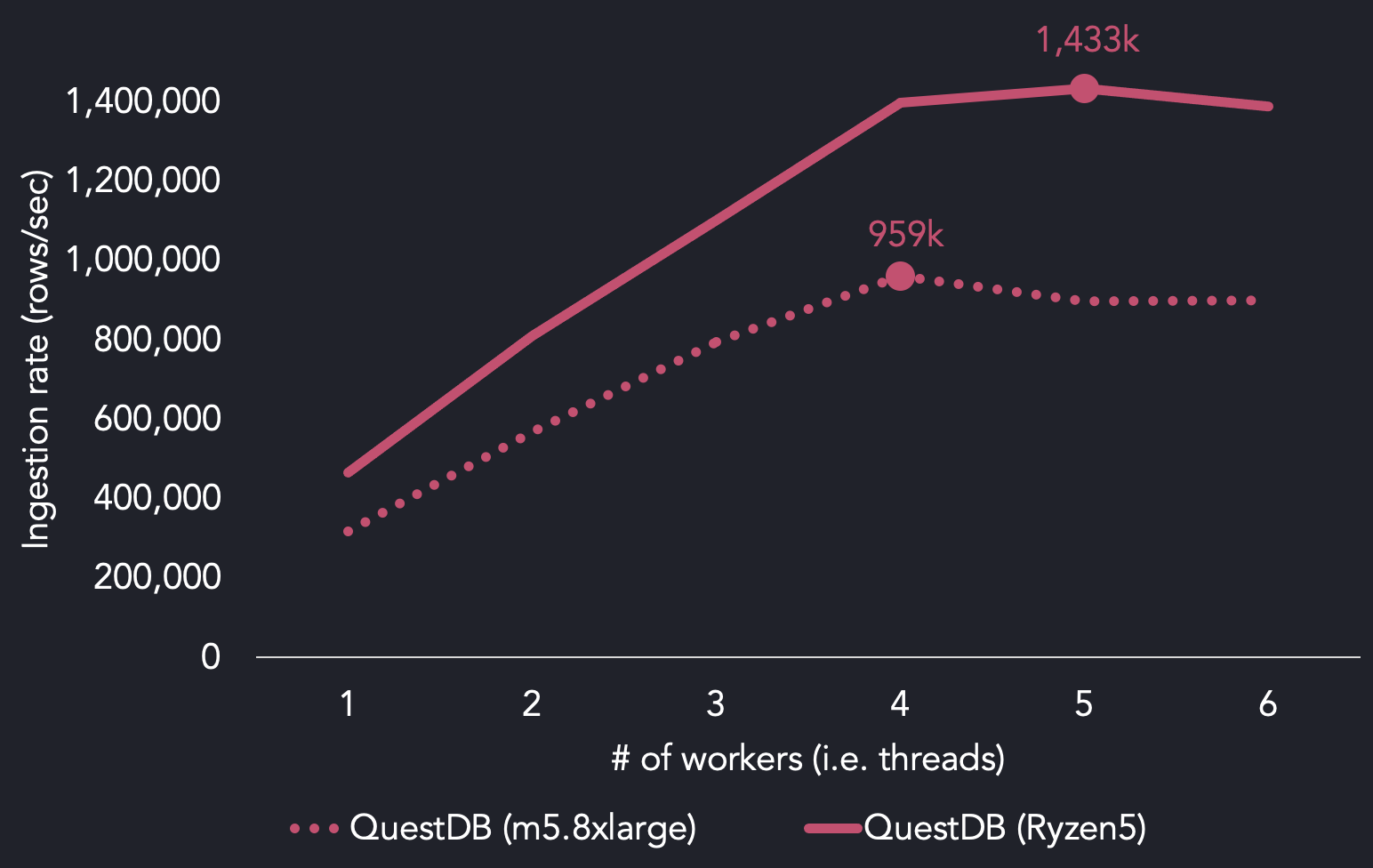
比较QuestDB TSBS在AWS EC2与AMD Ryzen5上的负载结果
你应该如何存储乱序的时间序列数据?
事实证明,在摄取过程中对 “乱序”(O3)的数据进行重新排序特别具有挑战性。这是一个新的方法,我们想在这篇文章中详细介绍一下。我们对如何处理失序摄取的想法是增加一个三阶段的方法。
保持追加模式,直到记录不按顺序到达为止
在内存中对暂存区的未提交的记录进行排序
在提交时对分类的无序数据和持久化的数据进行核对和合并
前两个步骤很直接,也很容易实现,依然只是处理追加的数据,这一点没变。只有在暂存区有数据的时候,昂贵的失序提交才会启动。这种设计的好处是,输出是向量,这意味着我们基于向量的阅读器仍然是兼容的。
这种预提交的排序和合并方式给数据获取增加了一个额外的处理阶段,同时也带来了性能上的损失。不过,我们还是决定探索这种方法,看看我们能在多大程度上通过优化失序提交来减少性能损耗。
我们如何分类、合并和提交无序的时间序列数据
处理一个暂存区给了我们一个独特的机会来全面分析数据,在这里我们可以完全避免物理合并,并通过快速和直接的memcpy或类似的数据移动方法来替代。由于我们的基于列的存储,这种方法可以被并行化。我们可以采用SIMD和非时序数据访问,这对我们来说是很重要的。
我们通过优化版本的radix排序对来自暂存区的时间戳列进行排序,所产生的索引被用于并行对暂存区的其余列进行排序。
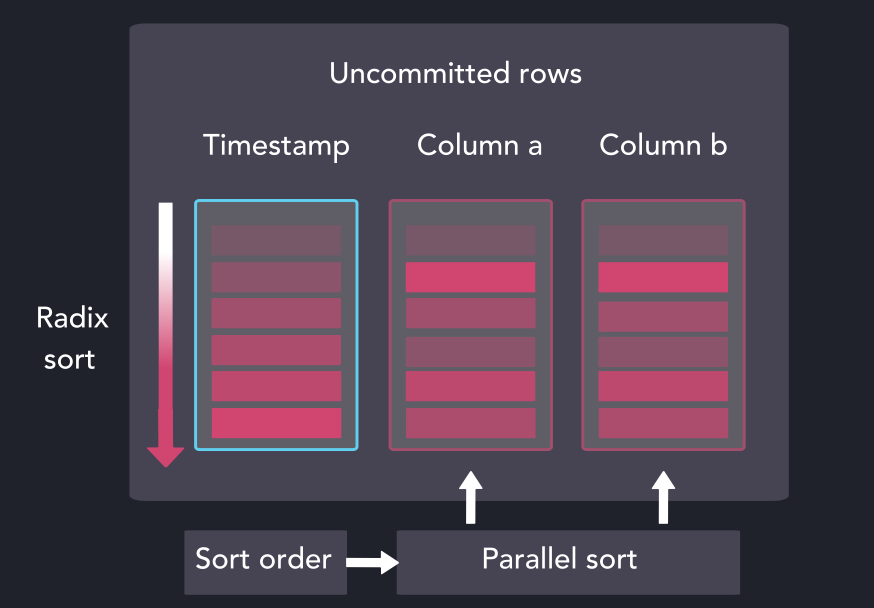
并行得将列进行排序
现在排序的暂存区是相对于现有分区数据进行映射的。从一开始可能并不明显,但我们正试图为以下三种类型的每一种建立所需的操作和维度。
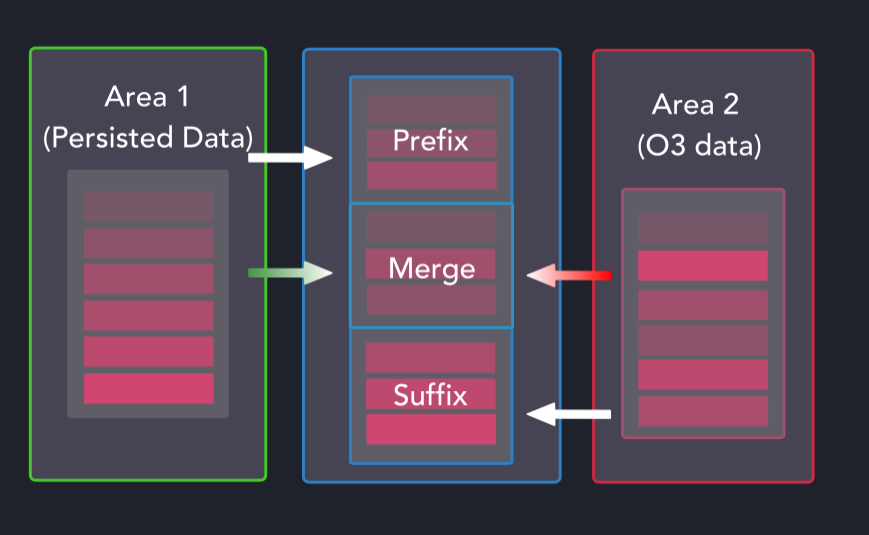
失序(O3)排序和合并方案
当以这种方式合并数据集时,前缀和后缀组可以是持续的数据、失序的数据,或者没有数据。合并组(Merge Group)是最繁忙的,因为它可以被持久化的数据、失序的数据、失序的数据和持久化的数据占据,或者没有数据。
当明确了如何分组和处理暂存区的数据时,一个工人池就会执行所需的操作,在少量的情况下调用memcpy,其他都转向SIMD优化的代码。通过前缀、合并和后缀拆分,提交的最大活度(增加CPU容量的易感性)可以通过partition_affected x number_of_columns x 3得到。
时间序列数据应该多久进行一次排序和合并?
能够快速复制数据是一个不错的选择,但我们认为在大多数时间序列获取场景中可以避免大量的数据复制。假设大多数实时失序的情况是由传递机制和硬件抖动造成的,我们可以推断出时间戳分布将在一定区间范围。
例如,如果任何新的时间戳值有很大概率落在先前收到的值的10秒内,那么边界就是10秒,我们称这个为滞后边界。
当时间戳值遵循这种模式时,推迟提交可以使失序提交成为正常的追加操作。失序系统可以处理任何种类的延迟,但如果延迟的数据在指定的滞后边界内到达,它将被优先快速处理。
如何比较时间序列数据库的性能
我们已经在TimescaleDB的TSBS GitHub仓库中开启了一个合并请求(Questdb基准支持 https://github.com/timescale/tsbs/issues/157),增加了针对QuestDB运行基准测试的能力。同时,用户可以克隆我们的基准测试fork(https://github.com/questdb/tsbs),并运行该套件以查看自己的结果。
tsbs_generate_data –use-case=”cpu-only” –seed=123 –scale=4000 `。
–timestamp-start=”2016-01-01T00:00:00Z” –timestamp-end=”2016-01-02T00:00:00Z” \
–log-interval=”10s” –format=”influx” > /tmp/bigcpu
tsbs_load_questdb –file /tmp/bigcpu –workers 4
构建具有授权许可的开源数据库
在进一步推动数据库性能的同时,使开发人员能够轻松地开始使用我们的产品,这一点每天都激励着我们。这就是为什么我们专注于建立一个坚实的开发者社区,他们可以通过我们的开源分销模式参与并改进产品。
除了使QuestDB易于使用之外,我们还希望使其易于审计、审查,提交代码或其他的项目贡献。QuestDB的所有源代码都在GitHub(https://github.com/questdb/questdb)上以Apache 2.0许可证提供,我们欢迎对此产品的各种贡献,包括在GitHub上创建issue或者提交代码。
© 2021年QuestDB。由Slab提供






