我曾经思考这样一个问题,人们为什么喜欢用水来形容数据呢?显而易见的是有许多共通之处,海洋里有无穷尽的水,它象征着汹涌而来的数据洪流,如果没有应对之道则很容易深陷其中而迷失。
2021年六月底,在聆听亚马逊云科技大中华区云服务产品部总经理顾凡介绍智能湖仓架构后,更进一步感受到了数据与水的相似之处。亚马逊云科技丰富且具体的方案与使用场景一一对应,亚马逊云科技的智能湖仓架构清晰且更具备可落地性。
正如古希腊哲学家赫拉克利特所说,“人不能两次踏进同一条河流”。我们也会发现,人也不可能见到一成不变的数据,数据从诞生的那一刻起,它的生命周期就开始了,它具有自己的特征,它具有种种属性,它可以不停的流转,在现代化的数据技术加持之下,不同阶段的数据有各种富有价值的妙用。
亚马逊云科技智能湖仓是什么
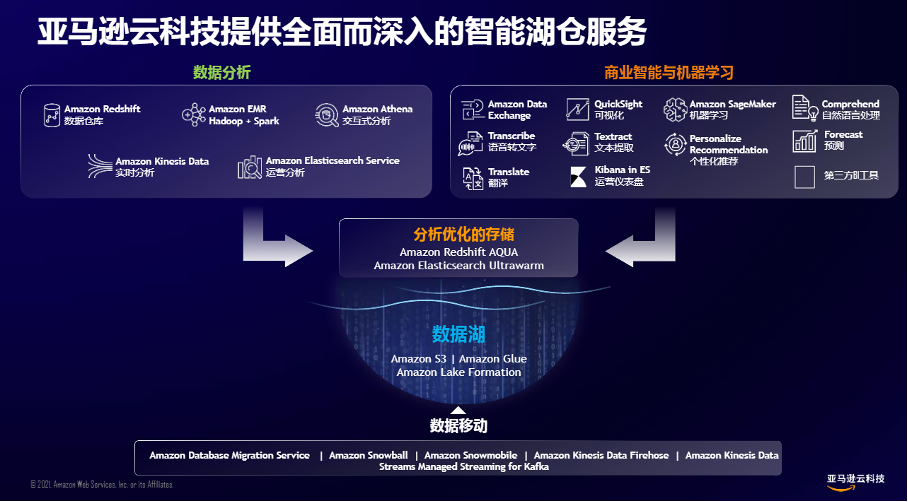
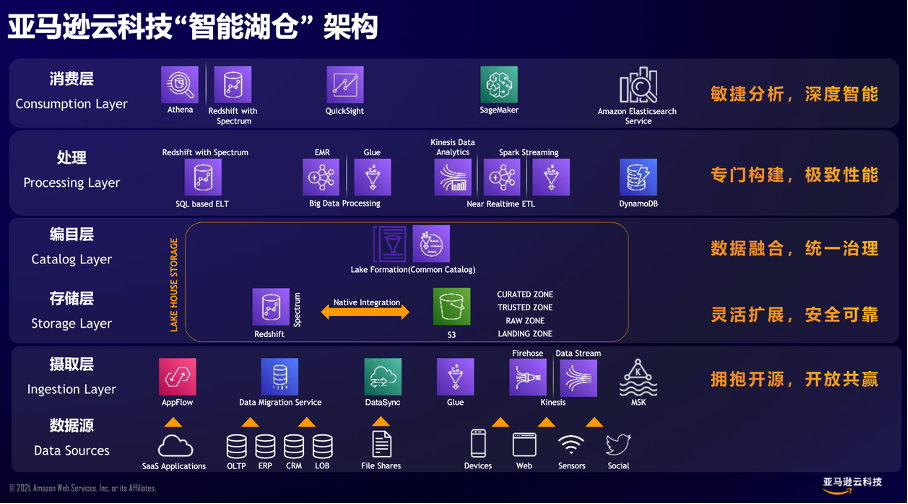
上面这张图就涵盖了亚马逊云科技所说的智能湖仓的全部内容,说它简单是因为看起来很简单,顾名思义,它包括数据仓库和数据湖,说它复杂,因为它包含的东西不只是数据仓库和数据湖。
首先要知道,亚马逊云科技所说的智能湖仓不是一个具体的技术,它是一系列技术产品组合在一起的技术架构,大体上包括三部分:
第一部分,主要指的是数据存储系统。这里主要指的是大名鼎鼎的,能存放各种类型、各种规模数据的Amazon S3对象存储。配套的还有数据预处理的配套工具Amazon Glue,还有快速构建数据湖的工具Amazon Lake Formation。
第二部分,利用数据、消费数据的各种服务。比如有用于大数据分析的Amazon EMR,用于日志分析的Amazon ElasticSearch,用于商业智能的专业工具Amazon QuickInsight,用于实时分析的Amazon Kinesis Data,以及作为机器学习的专业工具的Amazon SageMaker等。
第三部分指的是用于收集和迁移数据的各种方案,指的是能把数据从各种环境(包括有网环境、没网环境以及网络环境不大好的地方),从各种数据源头(各种关系型和菲关系型数据库,数据流)汇聚到数据湖里的各种工具。
亚马逊云科技智能湖仓有什么技术产品?
上文提到顾凡的介绍让我联想到了数据与水的相似之处,最直接的联想来自这样一张图。
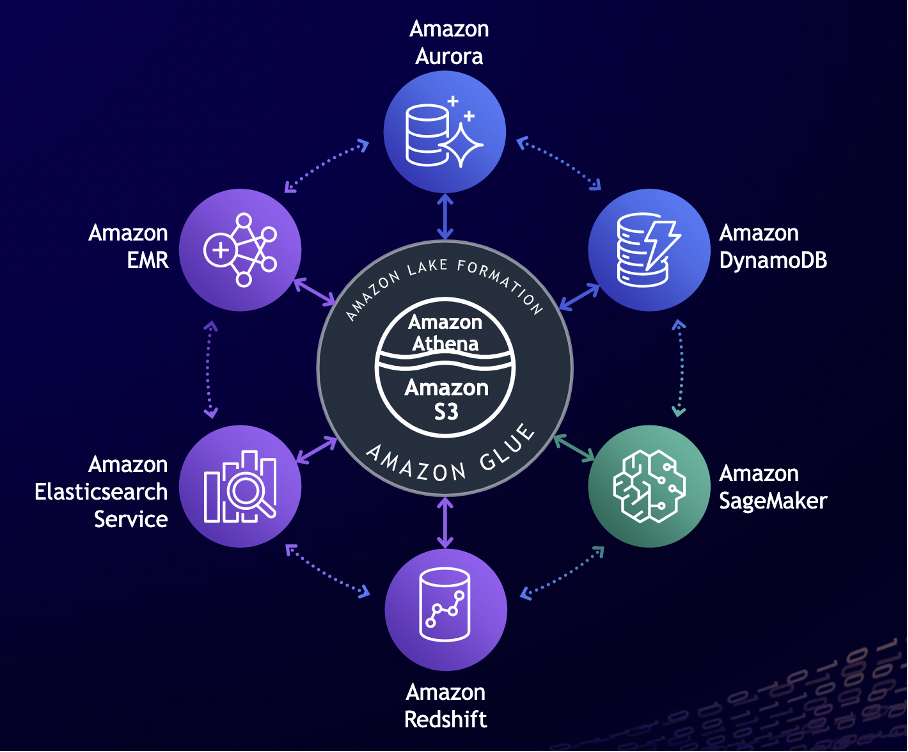
图的中间是数据湖,它是存放数据的地方,除了有S3对象存储,还有可直接对数据进行交互式查询的Amazon Athena。
以中间部分的数据湖为中心,外围有六大数据服务,包括:关系型数据库Amazon Aurora,非关系型数据库Amazon DynamoDB,机器学习服务Amazon SageMaker,数据仓库Amazon Redshift,日志服务Amazon Elasticsearch,大数据服务Amazon EMR。
数据能在外围流转,也都能与中间部分的数据湖进行数据交换,相互之间是贯通的。如同许多生态系统中,动植物相互间有直接或者间接的关联,以某种形式相互交换信息,而处于不同形态的数据之间也是相互有联系的。
比如,当数据仓库中完成了一次查询,查询的结果会存入到数据湖中,存入的数据被机器学习调用后又会生成机器学习模型,从而开展更有价值的业务。又比如,当实时数据流服务把用户在网页的交互数据传到数据湖之后,用数据仓库进行分析会得到一份用户活跃情况报告。
这种不同系统间的相互联系,不同系统中数据的无缝迁移正是亚马逊云科技智能湖仓所追求的终极目标,是一件听起来很简单但做起来很复杂的事。
亚马逊云科技智能湖仓架构的五大特点
亚马逊云科技智能湖仓架构其实并不难想象,难的是具体的实现,在具体实现中,亚马逊云科技的智能湖仓架构构建了这五大优势:
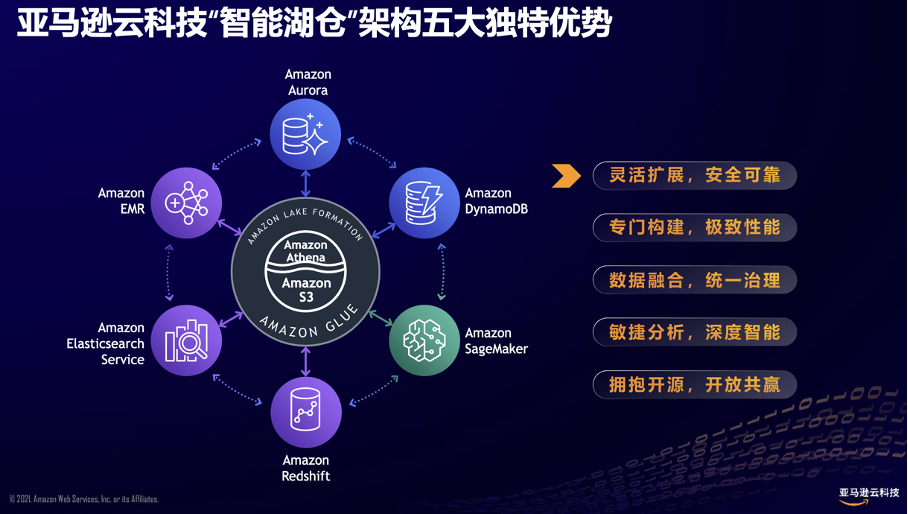
第一,灵活扩展、安全可靠。这一特点描述的都是亚马逊云科技的基础服务的特点,具体指的就是Amazon S3对象存储,作为亚马逊云科技的第一个云服务,S3各方面都非常成熟,是业内最好的标杆,在可靠性、安全性、合规性、成本优化等多个方面一直引领行业。
第二,专门构建、极致性能。亚马逊云科技喜欢强调专门构建,强调是为某个场景构建最适合的工具,它往往不是单个工具,而是成体系的一个工具,都是以组合拳的形式出现,各产品间职责划分明确,定位清晰,用户选择的时候不迷惑,用的时候能更顺手。
第三,数据融合、统一治理。这一点可以说是智能湖仓架构的灵魂了,包括数据在各点移动和转化工作,比如提取转换加载(ETL)之类的操作,比如为数据可视化、为机器学习做准备的各种操作,以及还有数据复制之类的操作等等。
第四,敏捷分析、深度智能。这里提到的是两个融合,一个是Amazon SageMaker和数据仓库融合,SageMaker从Amazon Redshift或Amazon S3里直接调取数据,服务于机器学习专家。一个是让数据仓库与Amazon SageMaker集成,让不会机器学习的数据库工程师和分析师也能训练机器学习模型。
第五,拥抱开源、开放共赢。与许多云厂商一样,亚马逊云科技托管了许多开源项目,同时也反哺开源社区,产品方面遵循开源标准,以标准化API保持与开源生态的联系,避免锁定用户,降低用户迁移的代价。
亚马逊云科技智能湖仓的落地
亚马逊云科技有丰富全面的工具,过去的半年里,亚马逊云科技与光环新网和西云数据合作发布了近40项数据分析相关服务和特性,包括Amazon Glue 2.0,Amazon Athena 2.0,Amazon Lake formation以及Amazon SageMaker相关的功能特性。
除了产品技术,亚马逊云科技的专业服务在用户侧落地环节中也至关重要,赋能团队帮助许多中国企业完成数据从想法到原型到生产系统的实现过程,市场观察者Frost Rader认可亚马逊云科技在中国数据管理解决方案综合市场中的表现,将其评为2020中国数据管理解决方案市场领导者。
丰田互联基于亚马逊云科技搭建灵活可扩展数据湖。丰田车联网服务把经授权数据通过Amazon Kinesis Data Stream传到丰田互联构建的一个超大的数据湖,通过Amazon EMR对整个的数据做ETL的处理后,对数据湖里面的数据做分析,根据驾驶员的使用习惯提供一些安全用车建议,根据驾驶员的驾驶习惯来决定是否在保险费用上作出调整。
亚马逊云科技助力TCL消除数据孤岛并构建数据融合。TCL先是把多个部门的多种不同数据统一汇聚到基于Amazon S3的数据湖里,消除了数据孤岛。同时,使用大数据服务Amazon EMR对整个湖里的数据做ETL处理和分析后,把数据加载到数据仓库Amazon Redshift里来生成报表和分析报告。
亚马逊云科技帮助德比软件构建了一套缓存系统。德比软件一方面收集房客点击流数据获知房客期望的房屋概况,一方面获知酒店房型的状态,将数据注入到数据湖后,由Amazon EMR完成ETL,然后交给Amazon SageMaker来训练可以预测房屋情况的模型。德比软件的系统在预测的基础上结合实时查询,从而实现性能和成本的最佳平衡,帮助德比软件实现降本增效。
结语
在听顾凡介绍之前,笔者总是感觉数据湖的说法并不陌生,但许多时候并不落地。但从一番介绍中能看到,无论是数据湖还是数据仓库,又或者是机器学习和商业智能,亚马逊云科技几乎都提供有具体的方案,使得落地的路径变得清晰可见。