
10月21日,网易数字+大会在杭州钱塘江畔召开,网易数帆旗下网易有数在会上发布了全链路数据生产力平台2.0,推出了DataOps、逻辑数据湖在内的最新技术实践,进一步完善数字治理能力,促进企业数智化转型升级。
网易有数产品总经理余利华表示,迈入数据生产力平台2.0阶段,更应该夯实自身技术服务能力,从大数据底座、到数据中台、再到数据应用,每个链路都需要更好的打磨才能服务好客户,达成实际业务中“人人用数据、时时用数据”的目标,真正发挥数据生产力。

过去一年,全链路数据生产力1.0的提出,以数据中台、数据应用为两大节点,让企业大数据决策水平提升实现正向闭环,将数据价值从业务系统中释放。在1.0的实践中,网易数帆发现,全链路数据生产力的闭环仍然存在一些阻滞,其中数据中台的节点,各个系统数据的物理聚合成本越来越高,数据开发的低效拖慢交付应用,同时中台对于实时数据的处理要求日趋增多;在数据应用的节点,非结构化数据的理解需要更多的手段支撑。
作为今年的重要看点,网易数帆是如何解决上述问题,实现全链路数据生产力从1.0到2.0的跃迁?这其中又有哪些创新技术的推出?
提升数据开发效率,试试有数DataOps
大会当天,网易数帆推出了今年数据中台的重磅升级——有数DataOps,旨在帮助企业解决数据开发过程中的效率和质量问题,可以说是将DevOps的理念应用于数据开发领域,以缩短洞察周期,推动项目持续集成(CI)和持续部署(CD)。
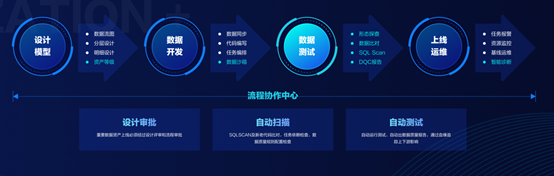
DataOps全流程
大会现场,余利华还展示了网易云音乐使用DataOps成功实践。通过设置独立的开发环境、自动测试流程,云音乐可以有效排查上线前代码中存在的风险,实现自动运行测试。从效果上看,在使用有数DataOps产品后,因代码提交产生的数据质量问题下降了接近90%,平均需求交付周期从5天下降到2.5天,效率直接提升100%。
逻辑数据湖:从“Collect”到“Connect”
企业建设数据中台不应该是把所有的数据全部收集(Collect)到一个载体后再开始应用,随着数据的不断涌入,用一种连接(Connect)的方式重复利用数据,成为了当下技术领先厂商们思考的手段。
余利华指出,数据中台建设之初,往往误以为只要把数据集中到一起,就能让数据充分被利用。但在这些年与客户交流后发现,企业想要构建一个物理上集中的数据中台非常困难。那么能否通过一种方式,在不要求数据迁移的前提下,将数据纳入数据中台管理?
大会现场,网易数帆发布了首创的,基于逻辑数据湖的数据中台。作为一种构建物理分散,逻辑统一的数据中台,其核心价值就是统一源数据信息、数据标准和数据源,同时兼容遗留系统,支持Oracle/MySQL/Vertica等7类系统,实现数据的统一开发和统一治理。
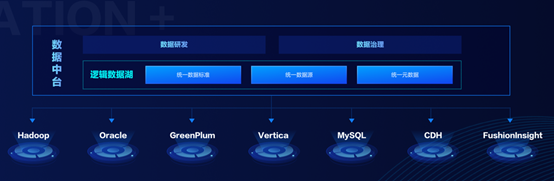
有数逻辑数据湖
迈入实时中台时代,Arctic引擎驱动力
面对日益增长的数据规模以及越来越低时延的数据处理要求,流处理正在成为大数据厂商亟待精进的业务能力之一。企业对于实时数据的管理需求日益显著,特别是对于像广告、风控、促销、物流等业务场景,只有依赖强大的流计算引擎才能支持实时动态的数据结果。
为了解决这些问题,网易数帆推出了有数实时数据湖引擎Arctic,不仅实现了流批一体存储,还支持无缝对接数据中台数据治理体系,可以说是极大地增强了数据摄取性能,特别是对于海量日志、事件等变更频繁、实时性高的数据加工等业务场景,有着十分广阔的技术实践空间。
此外,搭载数据湖引擎Arctic,网易数帆“有数实时数据中台”更是成功入选多个国家级大数据标杆示范项目评选,包括像今年中国大数据产业博览会“十佳大数据案例”,工信部试点示范项目等等。
有数机器学习平台:AI深化数据应用
随着物联网和移动设备的发展,产生的数据越来越多,种类也包括图片、文本、视频等非结构化数据,这使得机器学习模型可以获得越来越多的数据。在全链路的数据应用节点上,网易数帆也分享了自己多年的实战经验,推出了有数机器学习平台,去帮助企业理解及处理非结构化数据。
本次推出的网易有数机器学习平台,经过网易多年内部业务验证,能够大幅提升机器学习迭代效率。在机器学习的各个阶段都能提供有效支持,通过无缝对接数据中台,使得数据访问变得非常简单。同时还提供Notebook和可视化建模两种方式,支持TensorFlow,PyTorch主流算法框架,一键部署等等。
除了以上技术亮点,大会还发布了有数BI数据准备,针对缺乏专业人员的小微企业来说,可以借助有数BI数据准备,建立自助式ETL实现轻量级湖仓。
本次全链路数据生产力平台2.0的发布,标志着网易数帆数据能力的全面提升,最终目的还是通过技术手段去解决企业实际业务中暴露的难点,提升数据价值的有效利用。






