
摘要:随着数据量的倍数增长,无处不计算的概念正在普及,现有的以计算为中心的架构需要将数据传输到中央计算内存单元进行数据挖掘与分析。随着数据时代的到来,新形态的以数据为中心的计算存储架构和技术正在快速发展,在数据存储端直接进行数据处理将成为风潮,不仅可以提高云数据中心的数据处理能力和效率,并预计可为物联网、机器学习、边缘计算等领域创造更多商务价值。
数据量的产出正在呈现爆发式的增长。根据分析调研机构IDC的报告指出,被创建、获取或复制的数据量将从2018年的33 ZB增加到2025年的175 ZB。为了让这些数据实现其价值,我们必须将其分析处理成有意义的见解,而数据分析的速度和效率依赖于数据处理系统的架构。以计算为中心的架构需要将数据传输到中央计算内存单元进行数据挖掘与分析,更加适用于数据量小、计算密度大的应用负载,但在数据量激增的情况下很显然地有些远水不解近渴,难以继续扩展。现在IT行业里更多的关注点是如何将计算能力分布到存储设备附近,就地对大量数据进行分析处理,从中获取洞察力。这种趋势推动了以数据为中心的计算存储的快速发展。
今天,有越来越多的数据存储在各种形态的存储盘上,但数据的存储和计算处理总在不同的地方进行,因此我们常见大量数据(目前一般盘的容量通常为16 TB,并不断增加)在存储和计算设备之间移动,但由于网络带宽和计算单元内存容量的限制这种方法无法扩展,导致大量具附加价值、有潜力为服务及运营带来指导性洞察力的数据不能发挥他们应有的威力。
在传统的存储模型中,数据一般存储在硬盘和固态硬盘上,在需要进行数据分析的时候,将其传输到外部的计算设备,通常是服务器。计算存储能在数据所在的存储盘上进行数据计算处理,进而直接从数据中生成洞察力和价值,以释放更多数据的潜能。
什么是计算存储,它为什么重要?
所谓的“计算存储”就是让存储设备更加智能,可以直接在存储数据的地方进行数据处理。这种方法减少了大量数据向外部处理设备的传输,同时带来了无数个的好处,包括减少时延和带宽使用、提高安全性和节能。换句话说,数据处理的工作负载将直接在存储控制器本身上进行。
对于许多机器学习或分析应用程序、以及物联网和边缘计算的其他用例来说,计算存储的应用对于它们在实现实时处理方面的要求至关重要。以物联网的用例来看,随着物联网设备部署数量的加速,这些设备也迅速产生大量原始且非结构化的数据。由于物联网设备部署遍布世界各个角落,传感器日趋复杂,将所有数据传输到云数据中心进行存储和处理不仅非常昂贵,而且是一种浪费,因为并非所有获取的数据都会能带来价值。
举个例子,一个大型停车场的监控摄像头系统记录了每辆汽车的车牌号和进出时间,以便对停车时间进行计费,同时也确保安全。这个案例里面重要的信息之一是车牌号码,而无论汽车是否进入或离开停车场,将所有大图像或视频流传输到远端服务器进行图像处理是非常低效的做法。
应用了计算存储之后,每个摄像头都将视频或图片传输到本地的存储盘内,然后盘内自带的计算功能就能直接识别出车牌号码。通过在存储盘上直接进行机器学习和图像识别,并且只将从原始数据中提取的有价值信息——车牌号码和进出场时间,传输给远端服务器,计算存储极大地提高了信息处理的效率,减少网络带宽的浪费。此外,如果停车场中有多个摄像头,每个摄像头都有多个存储盘,那么摄像头越多,存储盘就越多,因地制宜的计算也就越多。如此一来,整个信息处理系统就变得更高效且可扩展性更高。
计算存储还能在其他应用场景也施展威力,例如:
数据库加速:直接在数据上执行操作
卸载:直接在数据上进行压缩/加密/编码/重复数据删除等
内容分发网络(CDN):轻松实现非常本地化的内容分发
人工智能/机器学习:直接从海量数据中生成洞察
边缘计算:一个运行Linux的计算存储盘(Computational Storage Drive, CSD),自身就是一个独立的小型服务器
图像分类:直接在数据存储的位置进行元标记
视频:对大型图像、视频、多媒体文件进行本地处理分析,以提取有价值的信息
运输/车载:直接处理交通工具中存储的遥测数据
传统的存储盘内的数据必须从设备端传输到服务器,才能借助服务器内的计算单元进行数据处理分析,这样的做法不仅需要额外的时间、精力、带宽和时延,同时增加了数据泄露的风险——在数据传输的过程中可能发生未经授权的访问。
同时,如果这些系统与服务器连接的回程线路,其带宽有限或价格昂贵,那么计算存储更能进一步显着降低总拥有成本(TCO)。额外的好处包括:
——更快的响应时间和更低的时延:将智能性移动至所需之处,可实现近乎实时的结果交付。数据不再需要通过协议封装,然后通过路由器和交换机移动和复制,在服务器上解包后才能进行处理
——节省带宽,降低能耗:减少数据传输意味着节省宝贵的带宽资源,防止网络拥塞,并且降低设备能耗和热能产生
——安全与隐私:原始数据留在本地存储盘上,不再向外传输,而只是将数据分析的结论返回,降低数据泄露的风险
——扩展性:由于计算直接在存储盘上进行,增添更多的存储盘也同时增加了对本地数据进行处理分析的能力。
计算存储是如何工作?
计算存储盘(CSD)是一种提供持久数据存储和计算服务的存储设备。它通过计算和存储功能的耦合,在本地数据上运行应用程序,减少远程服务器上所需的处理工作负载以及数据的传输。为此,CSD的处理器是专用于直接处理CSD上的数据,从而让远程主机的处理器得以处理其他任务。
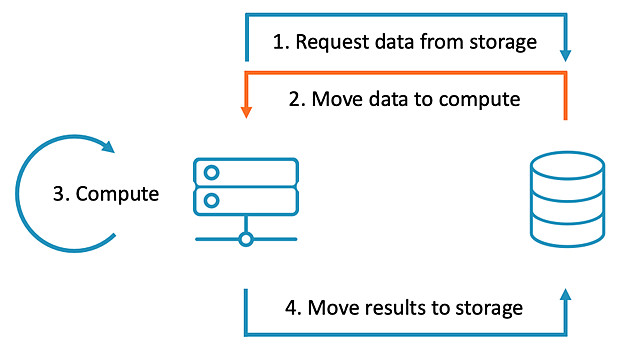
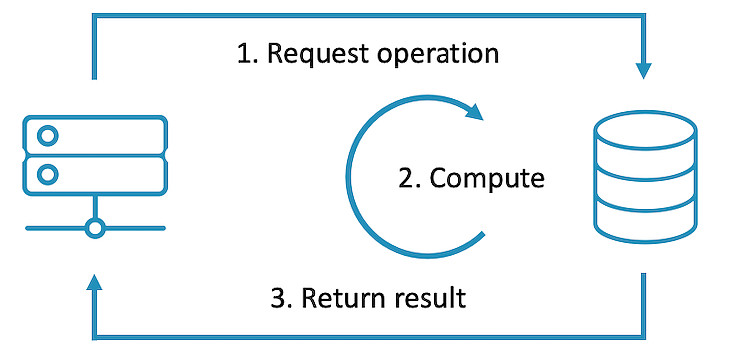
以下是传统的存储系统与采用计算存储系统的不同数据计算处理流程。
在传统的存储系统中,当我们想对数据进行计算处理时:计算方对存储方发送数据请求,数据被传输到计算方,进行计算处理,将处理后的结果传输返回存储方
在计算存储系统中,当我们想对数据进行计算处理时,计算方对存储方发送操作请求,存储方接受请求,直接进行计算处理将处理后的结果传输至计算方
特定领域架构(Domain-Specific Architecture, DSA)、异构计算(Heterogeneous Computing)和计算存储
实现计算存储的方法有很多种,但关键的要求是在存储控制器中嵌入处理的能力。说到数据处理以及计算能力,CPU处理器自然是首当其冲。CPU作为通用处理器,是个名副其实的“通才”,擅长执行指令运算和数值运算。CPU适用于各种工作负载,尤其是那些对延迟或每核性能很重要的工作负载。作为一个强大的执行引擎,CPU将其较少数量的内核集中在单个任务和快速完成任务上。这使得它非常适合从串行计算到运行数据库的工作。另外,CPU编程容易、生态成熟、拥有丰富的工具链和广泛的开发者支持,尤其是在计算存储方兴未艾,跑在CSD上的应用负载还不明确和成熟的情况下,CPU可以给予计算存储系统更多的灵活性。
特殊领域的加速器是计算和数据处理领域的“专才”,对于特定领域的应用和负载能提供显著的性能和效率的提升。在选择特殊领域的加速器的时候,需要特别注意两点:一是实际部署或者计划部署在CSD上的应用负载与加速器适合的负载匹配;二是编程的便利性,是否能够赋能广大的软件开发人员来利用加速器所带来的收益。
Linux促进计算存储的实现
实现计算存储的方法有很多种,但关键的要求是在存储控制器中嵌入处理的能力,使其可以运行功能丰富的操作系统,例如Linux和软件组件。如此一来,可以带来以下这些好处:
——拥有庞大Linux开发者社区的开源软件。具有庞大Linux开发者社区和行业广泛使用的标准工具的开源软件能让开发体验更加轻松。通过创建工作负载,开发者可以使用驾轻就熟的开发方式来构建遵循SNIA的标准的软件程序,并采用基于Linux的标准系统将其部署到存储设备,这不仅简化了系统,并且让软件开发更为轻松便捷。
——易用的工具。感谢Linux开源生态的的丰富资源,开发者获取广大的工具、文档和支持易如反掌,从而可以更顺畅地开发、部署以及管理计算存储工作负载。如此一来,开发者能快速将当前模式下运行在计算节点上的功能模块迁移至计算存储盘上。
——启动智能存储。在标准的NVMe盘中,由于存储控制器并不理解所处理的数据的内容和属性,而是纯粹把数据块当作黑盒来处理,所以难以实现数据的智能管理。在当前模式下,存储控制器对接收到的数据块进行拆分,然后将它们存储在NAND晶粒中的页面。当服务器发送数据块的请求时,存储控制器会从NAND取出数据,将它们重新组装成数据块,再传输送回服务器。由于存储控制器不了解文件系统,所以它对这些数据块的构成也一无所知,不管是JPEG图像,还是Word文档,还是可执行文件,处理方式都一视同仁。而运行Linux的存储盘可以挂载标准文件系统,使智能存储成为可能,同时CSD的应用程序能了解数据块实际代表哪些文件,并可根据文件类型和属性直接在数据上执行相应操作。
——存储盘就等于一台迷你服务器。运行Linux的存储盘能通过现有的标准开源系统进行硬盘的管理、工作负载的开发以及新工作负载的下载。它用最低的成本将存储盘变成了一个迷你服务器。
现在您可能不禁想着:难道Linux真的能在计算存储中被采用吗?这个问题的答案是肯定的。这样的操作系统不会过大吗?这个问题的答案是否定的。
当今的存储盘已经拥有数个GB的RAM和数个TB的存储空间,并具备处理进出存储盘的大量数据移动的高性能计算的能力。一般提到Linux,大家可能会联想到在大型服务器中安装的大型软件,并不适用于嵌入式设备端的存储、安装和运行,但相比于大型服务器,在存储设备上,我们对Linux的要求要低得多,其软件大小也能有显着的缩减。
存储设备上运行的Linux不再需要显示驱动程序,其他部分功能也不适用,可以将之简化并根据存储控制器的需求进行定制,例如,Debian 9只需要512 MB的RAM和2 GB的存储空间。
通过利用现在在复杂系统中使用的标准开源工具,我们可以进行CSD管理,例如利用Kubernetes、Docker或经过扩展的Berkeley Packet Filter(BPF)等常用工具,我们可以安全地下载和管理工作负载,以安全的方式执行应用程序或脚本。
具计算能力的实时处理器
从处理器的角度思考,实现计算型存储有几种方式,最为常见的就是将Arm Cortex-A应用处理器嵌入固态硬盘控制器的芯片中,这样的话,存储处理器就可以直接支持Linux的运行,这是一个不错的选择。但是存储设备对处理器的一个刚需是提供具有高确定性的实时行为,以保证数据搬运的速度和效率。为了顾全计算存储设备所应该具备的实时响应与计算能力,Arm在实时处理器Cortex-R系列开发出支持64位与Linux支持能力的Cortex-R82,与过去应用于存储设备的其他Cortex-R系列产品相比,最高可达到2倍的性能提升。Cortex-R82还可以加载Arm Neon技术,使存储应用较低的时延运行包括机器学习等新的工作负载,并提供额外的加速。此外,Cortex-R82本身为64位架构,最高可以存取1 TB的DRAM,在数据量激增和存储容量显著提高的未来供存储应用进行先进的数据处理。
存储控制器传统上是通过裸机/RTOS工作负载的运行,作为数据的存储及存取;而Cortex-R82提供可选用的内存管理单元(Memory Management Unit, MMU),让功能丰富的操作系统在存储控制器上直接运行,支撑起计算存储的实现基石。
计算存储的未来就在眼前
目前已有多家合作伙伴提供基于Arm 处理器的存储设备,同时整个产业也在致力于让所有存储开发者和厂商能一致采用一种通用的实现方式。Arm 正积极地参与 SNIA 计算存储技术工作小组,并携手 45 家公司和 202 名成员合作定义标准。这项标准将消除碎片化和缺乏兼容性的风险,进一步加速计算存储的发展与创新。
【本文作者马健,Arm物联网兼嵌入式事业部业务拓展副总裁】







