近日,CVPR 2022官方公布了接收论文列表,来自腾讯优图实验室共计30篇论文被CVPR收录,论文涵盖包括场景文本语义识别、3D人脸重建、人体姿态估计 (HPE)、目标检测、图像风格转换和视频插帧等研究领域。
CVPR全称IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition),该会议始于1983年,是计算机视觉和模式识别领域的顶级会议。根据谷歌学术公布的2021年最新学术期刊和会议影响力排名,CVPR在所有学术刊物中位居第4,仅次于Nature,NEJM和Science。
以下为腾讯优图实验室部分入选论文介绍:
1.面向评估的深度人脸识别知识蒸馏方法(Evaluation-oriented Knowledge Distillation for Deep Face Recognition)
知识蒸馏(KD)是一种常用的提升人脸识别小模型性能的方法。之前的KD 方法通常希望学生模型完全模仿教师模型在特征空间的行为,但是这样的一对一对应约束往往不利于知识从教师模型到小模型的迁移。
针对这一问题,我们提出了面向评估的人脸识别知识蒸馏方法,通过在训练过程中计算常用的人脸识别评估指标TPR和FPR,直接约束教师模型和小模型之间的指标差异,从而提升小模型的识别性能。
在常用的人脸识别测试集中的结果证明了我们方法的有效性。
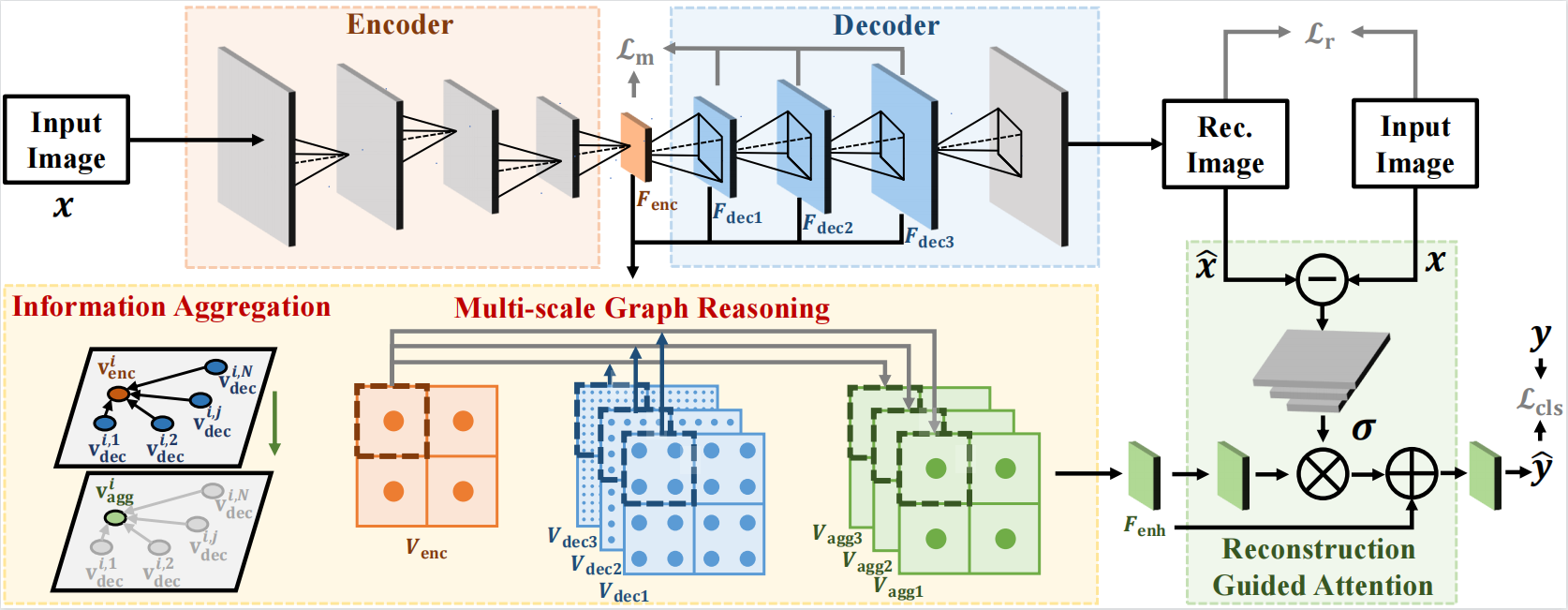
2.基于重建—分类学习的伪造人脸检测方法(End-to-End Reconstruction-Classification Learning for Face Forgery Detection)
现有伪造人脸检测方法大多聚焦于输入图像中特定的伪造模式(如,噪声特性、局部纹理、频域统计)来辨别伪造人脸。然而,过度关注特定的伪造模式会导致模型过拟合于训练集所呈现的伪造特征,而无法泛化到具有全新伪造模式的伪造样本上。
基于此,本研究从一个新的视角来探索伪造人脸检测任务。我们设计了一个重建—分类学习框架,通过重建真实人脸图像来学习真实人脸的共性表征,并通过分类任务来挖掘真实人脸与伪造人脸的本质差异。我们提出了一种度量损失以约束真实人脸在特征空间中的距离,同时增强真实与伪造人脸的差异信息。此外,多尺度图推理模块(Multi-scale Graph Reasoning Module)将重建网络编码器输出与解码器特征建模为偶图并对伪造线索进行推理;重建引导注意力模块(Reconstruction Guided Attention Module)将重建差异作为注意力掩码施加于分类特征映射上,使网络关注于潜在的伪造区域。
在伪造人脸检测基准数据集如FaceForensics++、WildDeepfake和DFDC上的大量实验结果表明,该方法具有良好的同源测试性能和泛化性能。
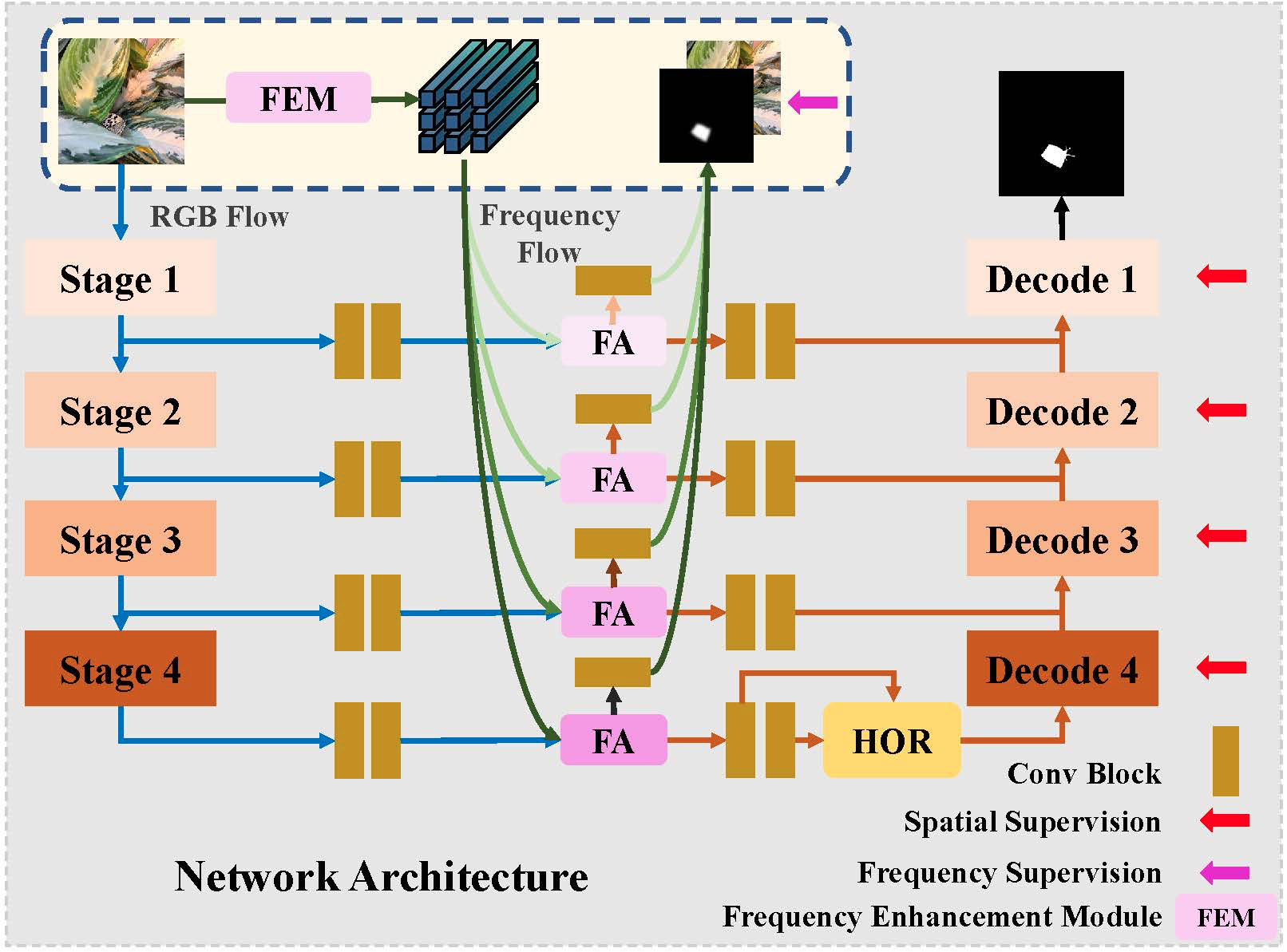
3.基于频域信息的伪装对象检测方法(Thinking Camouflaged Object Detection in Frequency)
伪装物体检测旨在识别隐藏在环境中的物体,这在医学、艺术和农业等领域中有各种下游应用。然而,以人眼的感知能力发现伪装的物体是一项极具挑战性的任务。因此,我们认为COD任务的目标不仅仅是模仿人类在单一RGB域的视觉能力,而是要超越人类的生物视觉。因此我们引入频域作为额外的线索,以更好地从背景中检测出伪装的物体。为了很好地将频率线索引入CNN模型,我们提出了一个具有两个特殊组件的网络。 我们首先设计了一个新颖的频率增强模块来挖掘频域中伪装物体的线索。它包含离线的离散余弦变换和可学习的增强方式。随后我们使用特征对齐来融合RGB域和频域的特征。此外,为了进一步充分利用频率信息,我们利用特征中的高阶关系来处理丰富的融合特征。在三个广泛使用的COD数据集上的综合实验表明,所提出的方法在很大程度上超过了其他先进的方法。
4.基于人脸伪造检测的频域对抗攻击算法(Exploring Frequency Adversarial Attacks for Face Forgery Detection)
近些年,人脸伪造技术在人脸信息安全方面带来了巨大的挑战,同时也在道德层面引起了较大的争议。尽管现有的伪造人脸检测方法实现了较好的检测性能,但这些方法容易受到对抗扰动的干扰。在输入人脸图像上添加微弱的人为设计扰动,就会使得伪造人脸检测器做出错误的判断,带来严重的安全隐患。在本研究中,针对伪造人脸检测器利用频率的信息进行鉴别真伪人脸的特点,提出了一种针对伪造人脸检测器的频率对抗攻击方法。通过对输入人脸图像应用离散余弦变换 (DCT),在频域中引入适应性的对抗噪声。与空间域中现有的对抗攻击方法(例如 FGSM、PGD)相比,我们的方法更不易被人眼察觉,而且不会降低原始人脸图像的视觉质量。此外,受元学习思想的启发,我们还提出了一种融合空间域和频域的对抗攻击方法。实验结果表明,该方法不仅可以有效地欺骗基于空间域特性的检测器,还可以有效地欺骗基于频域特征的检测器。此外,该方法作为黑盒攻击具有了较好的跨伪造人脸检测模型的攻击迁移性。

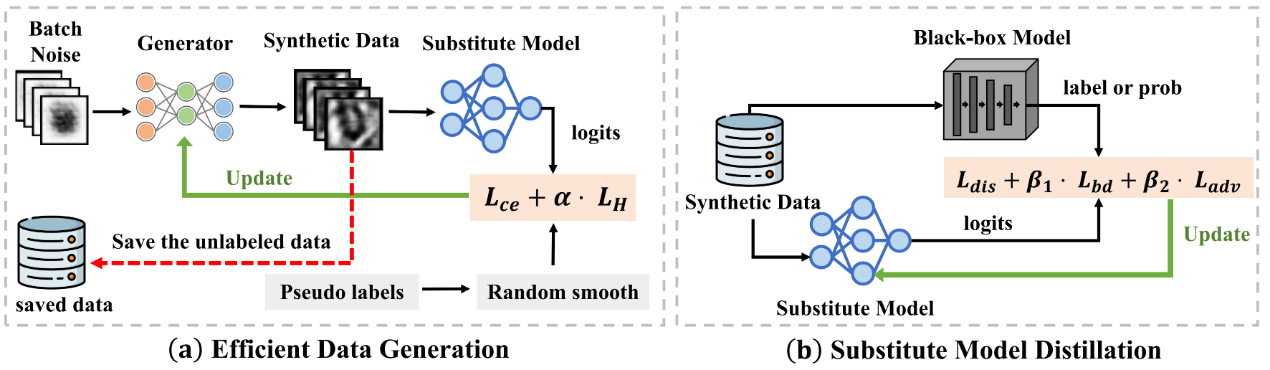
5.针对黑盒对抗攻击的高效无数据模型窃取方法(Efficent Data-free Model Stealing for Black-box Adversarial Attacks)
基于对抗样本具有迁移性的性质,训练替代模型来进行迁移攻击同样是一种有效的攻击方式。 通常,这些替代模型的训练往往依赖于原模型的真实训练数据。 然而在现实场景中, 由于个人信息保护,原始的训练数据很难合法合规的获取。考虑到这些数据限制,最近一些研究提出在零样本场景中来训练替代模型。 然而这些方法依赖于对抗性地训练生成器和替代模型,这种训练模式往往收敛困难,甚至可能导致模型崩塌, 在整个训练过程中,需要反复地访问黑盒模型,导致实际效率非常低下。在本文中,通过重新思考生成器和替代模型之间的合作关系,我们设计了一个更加高效且强大的零样本黑盒迁移攻击框架。该方法能在少量的查询次数中,大幅地增加迁移成功率。通过在多个数据集上的进行的大量实验,我们证明了该方法的有效性。
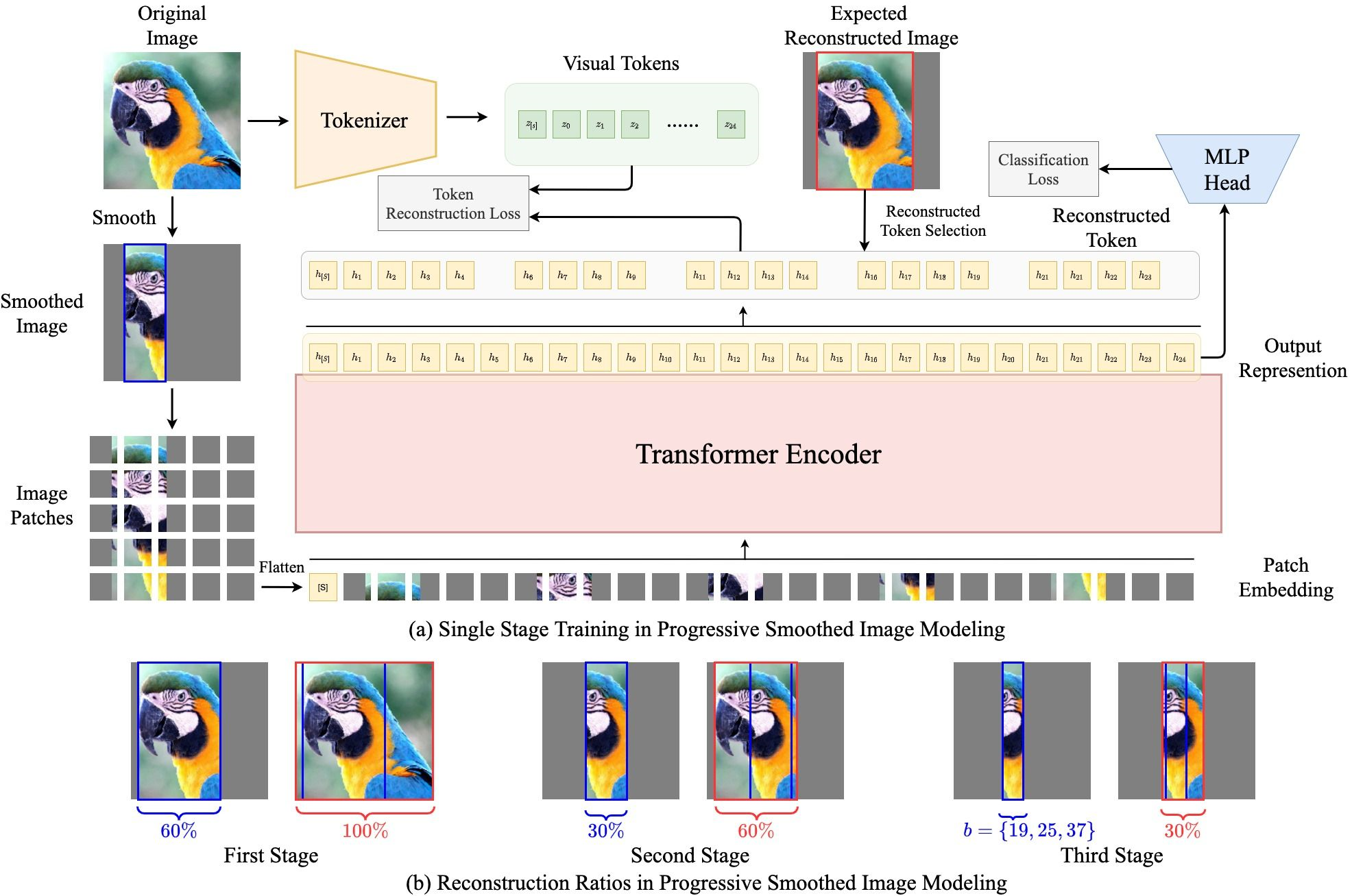
6.基于Vit的可信性图块对抗攻击防御方法(Towards Practical Certifiable Patch Defense with Vision Transformer)
图块攻击是对抗性实例中最具威胁性的物理攻击形式之一,它可以通过在连续区域内任意修改像素而导致网络诱发错误分类。可信的图块防御可以保证分类器不受图块攻击影响的鲁棒性。现有的可信图块防御系统牺牲了分类器的精度,在小数据集上只能获得较低的可信精度。此外,这些方法的纯净和可信精度仍然大大低于正常分类网络的精度,这限制了它们在实践中的应用。为了迈向实用的可信的图块防御,我们将视觉变换器(ViT)引入去随机化平滑(DS)的框架中。具体来说,我们提出了一个渐进式平滑图像建模任务来训练视觉转换器,它可以在保留全局语义信息的同时,捕捉到图像的更多可识别的局部背景。为了在现实世界中进行有效的推理和部署,我们创新性地将原始ViT的全局自我注意结构重建为孤立的带状单元自我注意。在ImageNet上,在2%的区域图块攻击下,我们的方法实现了41.70%的可信准确率,比之前的最佳方法(26.00%)增加了近1倍。同时,我们的方法实现了78.58%的纯净精度,这与正常的ResNet-101的精度相当接近。广泛的实验表明,我们的方法在CIFAR-10和ImageNet上的推断效率高,获得了最先进的纯净和可信精度。
7.基于物理引导解耦的隐式渲染和3D人脸重建(Physically-guided Disentangled Implicit Rendering for 3D Face Modeling)
本文提出了一种新的基于物理引导解耦的隐式渲染框架PhyDIR,用于高质量的3D人脸重建。方法动机来源于两方面:常用的图形学渲染器依赖过度的近似过程,阻碍了逼真的成像效果;神经渲染方法能够获得更好的纹理,但其耦合的过程难以感知3D操作。因此,我们通过显式的物理引导,学习对于隐式渲染的解耦方法,同时保证了渲染过程中的两点性质,即3D的处理和感知能力,以及高质量的成像。对于前者,PhyDIR显式地将3D光影和光栅化模型用于对渲染器的控制,对光照,脸型和视角进行解耦。特别地,PhyDIR提出了一种新的多图光影策略以补足单目图像的限制,使得光照变化能够被神经渲染器理解。对于后者,PhyDIR学习了基于人脸集合的隐式纹理,避免了病态的本征分解问题,并且利用一系列的一致性损失约束渲染过程。基于提出的方法,3D人脸重建能够受益于这两种渲染策略。在公开数据集上的大量实验表明PhyDIR能够在纹理和几何重建上获得当前最优的结果。
8.基于开放的退化图像学习人脸3D重建(Learning to Restore 3D Face from In-the-Wild Degraded Images)
开放场景的3D人脸重建是一个有挑战性的问题,因为其受制于有限的人脸先验和线索,尤其在输入图像质量退化的情况下。为了处理这个问题,我们提出了一种新的Learning to Restore (L2R)框架,无监督地从退化图像中获得高质量的人脸重建结果。相比于直接修复2D的图像表观,L2R通过提取生成式人脸先验以恢复3D细节。具体地,L2R提出了一个新的反射率修复网络以重建高质量的3D人脸纹理,其中利用了预训练的生成网络对缺失的人脸线索进行弥补。基于恢复的3D纹理中的细节,L2R学习建模位移图来增强面部结构和几何。这两个过程通过一个新的3D对抗损失进行相互优化,进一步提升效果并降低学习过程中的不确定性。在公开数据集上的大量实验表明,L2R在低质量图像为输入的情况下,可以获得当前的重建结果。
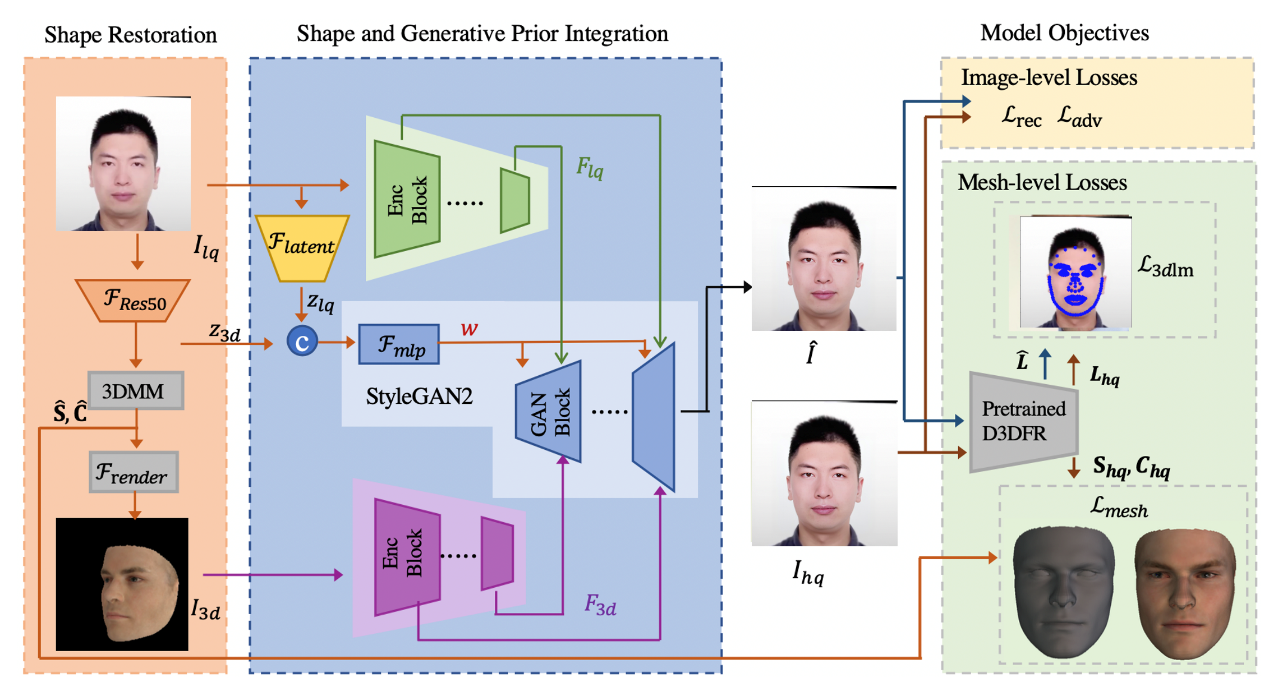
9.基于脸型先验和高清生成器的高清人像修复算法(Blind Face Restoration via Integrating Face Shape and Generative Priors)
高清人像修复是从低质量图中恢复出高清人像。虽然现有方法在生成高质量图像方面取得了重大进展,但它们通常无法从严重退化的输入中恢复自然的面部形状和高保真面部细节。在这项工作中,我们整合形状和生成先验来指导人像恢复。首先,我们建立了一个形状恢复模块,通过 3D 重建技术恢复合理的面部几何形状。其次,采用预训练的人像生成器作为我们的解码器,以生成逼真的高分辨率图像。为了确保高保真度,分别从低质量输入和渲染的 3D 图像中提取的分层空间特征插入到解码器中,提出了自适应特征融合块 (AFFB)。此外,我们引入了混合损失同时训练形状和生成先验,从而使这两个先验更好地适应我们的人像恢复任务。在合成数据集和真实世界数据集的实验结果表明,我们提出的 SGPN 优于其他SOTA 方法
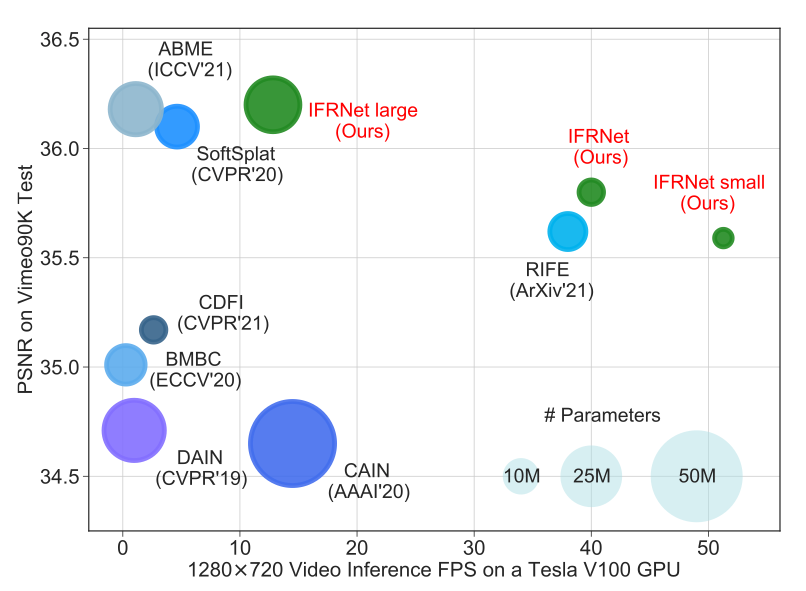
10.IFRNet:基于中间帧特征重建的高效插帧算法(IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation)
目前流行的视频插帧算法通常依赖于复杂的网络结构,其具有大量的模型参数与较高的推理延迟,这限制了它们在大量实时应用中的使用。在这篇论文中,我们新发明了一个高效的只包含一个encoder-decoder结构的视频插帧网络称为IFRNet,以实现快速的中间帧合成。它首先对输入的两帧图像提取特征金字塔,然后联合refine双向中间光流场和一个具有较强表示能力的中间特征,直到恢复到输入分辨率并得到想要的输出。这个逐渐refine的中间特征不仅能够促进中间光流估计,而且能够补偿缺失的纹理细节,使得所提出的IFRNet不需要额外的纹理合成网或refinement模块。为了充分释放它的潜能,我们进一步提出一个新颖的面向任务的光流蒸馏损失函数来使得网络集中注意力学习对插帧有益的运动信息。与此同时,一个新的几何一致性正则化项被施加到逐渐refine的中间特征来保持其较好的结构布局。在多个公认的视频插帧评测数据集实验中,所提出的IFRNet和相关优化算法展现出了state-of-the-art的插帧精度与可视化效果,同时具有极快的推理速度。