
近年来,自监督学习和Transformer在视觉领域大放异彩。图像自监督预训练极大降低了图像任务繁重的标注工作,节省大量人力成本,而transormer技术在NLP领域的巨大成功也为CV模型效果进一步提升提供了非常大的想象空间。为推进自监督学习和视觉Transformer在阿里集团、阿里云上的落地,阿里云机器学习平台PAI 打造了 EasyCV all-in-one视觉建模工具,搭建了丰富完善的自监督算法体系,提供了效果SOTA的视觉Transformer预训练模型,modelzoo覆盖图像自监督训练、图像分类、度量学习、物体检测、关键点检测等领域,并且面向开发者提供开箱即用的训练、推理能力,同时在训练/推理效率上也做了深度优化。此外,EasyCV对阿里灵杰系统做了全面兼容,用户可以非常方便的在阿里云环境下使用EasyCV的全部功能。
在经过阿里内部业务充分打磨以后,我们希望把EasyCV框架推向社区,进一步服务广大的CV算法开发者以及爱好者们,使其能够非常快速方便的体验最新的图像自监督以及transformer技术,并落地到自己的业务生产当中。
EasyCV背后的算法框架如何设计?开发者可以怎么使用?未来有哪些规划?今天一起来深入了解。
二 什么是EasyCV
EasyCV是阿里巴巴开源的基于Pytorch,以自监督学习和Transformer技术为核心的 all-in-one 视觉算法建模工具。EasyCV在阿里巴巴集团内支撑了搜索、淘系、优酷、飞猪等多个BU业务,同时也在阿里云上服务了若干企业客户,通过平台化组件的形式,满足客户自定定制化模型、解决业务问题的需求。
项目开源地址:https://github.com/alibaba/EasyCV
1 项目背景

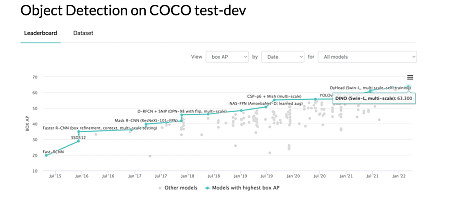
近两年,基于无标注训练数据的图像自监督预训练技术发展迅猛,在各个视觉任务的效果上已经媲美甚至超过需大量标注的有监督训练的效果;另一方面,在NLP领域大获成功的Transformer技术在各个图像任务上进一步刷新SOTA效果,其应用呈现出井喷式的爆发。作为二者的结合,自监督视觉Transformer的预训练也应运而生。
业界自监督学习和视觉Transformer算法技术更新迭代非常快,同时也给CV算法开发者带来了诸多困扰,比如相关开源代码零散,实现方式和风格参差不齐导致学习和复现成本过高,训练、推理性能低下等等。阿里云PAI团队通过搭建灵活易用的算法框架EasyCV,体系化地沉淀SOTA的自监督算法和Transformer预训练模型,封装统一、简洁易用的接口,针对自监督大数据训练方面进行性能优化,方便用户尝试最新的自监督预训练技术和Transformer模型,推动在业务上的应用和落地。
此外,基于PAI团队多年积累的深度学习训练、推理加速技术,在EasyCV中也集成了IO优化,模型训练加速、量化裁剪等功能,在性能上具备自己的优势。基于阿里云的PAI产品生态,用户可以方便地进行模型管理、在线服务部署、大规模离线推理任务。
2 主要特性
●丰富完善的自监督算法体系:囊括业界有代表性的图像自监督算法SimCLR, MoCO, Swav, Moby, DINO等,以及基于mask图像预训练方法MAE,同时提供了详细的benchmark工具及复现结果。
●
●丰富的预训练模型库:提供丰富的预训练模型,在以transformer模型为主的基础上,也包含了主流的CNN 模型, 支持ImageNet预训练和自监督预训练。兼容PytorchImageModels支持更为丰富的视觉Transformer backbone。
● 易用性和可扩展性 :支持配置方式、API调用方式进行训练、评估、模型导出;框架采用主流的模块化设计,灵活可扩展。
●高性能 :支持多机多卡训练和评估,fp16训练加速。针对自监督场景数据量大的特点,利用DALI和TFRecord文件进行IO方面的加速。对接阿里云机器学习PAI平台训练加速、模型推理优化。
三 主要技术特点
1 技术架构
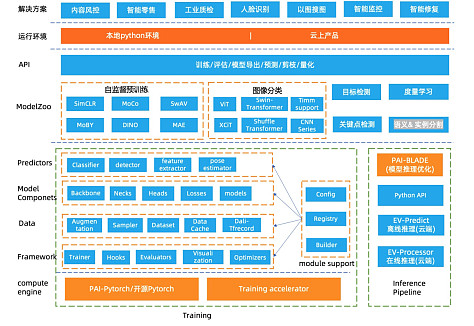
EasyCV 架构图
EasyCV 底层引擎基于Pytorch,接入Pytorch训练加速器进行训练加速。算法框架部分主要分为如下几层:
· 框架层:框架层复用目前开源领域使用较为广泛的openmmlab/mmcv 接口,通过Trainer控制训练的主要流程,自定义Hooks进行学习率控制、日志打印、梯度更新、模型保存、评估等操作,支持分布式训练、评估。Evaluators模块提供了不同任务的评估指标,支持多数据集评估,最优ckpt保存,同时支持用户自定义评估指标。可视化支持预测结果可视化、输入图像可视化。
· 数据层:提供了不同数据源(data_source)的抽象,支持多种开源数据集例如Cifar、ImageNet、CoCo等,支持raw图片文件格式和TFrecord格式,TFrecord格式数据支持使用DALI进行数据处理加速,raw格式图片支持通过缓存机制加速数据读取。数据预处理(数据增强)过程抽象成若干个独立的pipeline,支持配置文件方式灵活配置不同的预处理流程。
· 模型层:模型层分为模块和算法,模块提供基础的backbone,常用的loss,neck和各种下游任务的head,模型ModelZoo涵盖了自监督学习算法、图像分类、度量学习、目标检测和关键点检测算法,后续会继续扩充支持更多的high-level算法。
· 推理:EasyCV提供了端到端的推理API接口,支持PAI-Blade进行推理优化,并在云上产品支持离在线推理。
· API层:提供了统一的训练、评估、模型导出、预测的API。
EasyCV支持在本地环境方便的运行和调试,同时,如果用户想跑大规模生产任务,我们也支持在aliyun PAI产品中方便的进行部署。
2 完善的自监督算法体系
自监督学习无需数据标注,对比学习的引入使其效果逐步逼近监督学习,成为近年来学术界和工业界关注的重点之一。EasyCV囊括了主流的基于对比学习的自监督算法,包括SimCLR、MoCo v1/v2、Swav, Moby, DINO。也复现了基于mask image modeling的MAE算法。此外,我们提供了完善的benchmark工具,进行自监督预训练模型在ImageNet上效果的评估。
基于体系化的自监督算法和benchmark工具,用户可以方便的进行模型改进,效果对比,进行模型创新。同时也可以基于自己的大量无标注的数据,训练适合自己业务领域的更好的预训练模型。
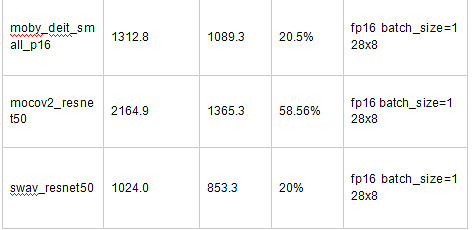
下表展示了已有自监督算法基于ImageNet数据预训练的速度和在ImageNet验证集上linear eval/finetune的效果。

3 丰富的预训练模型库
CNN作为主干网络,配合各种下游任务的head,是CV模型常用的结构。EasyCV提供了多种传统的CNN网络结构,包括resnet、resnext、hrNet、darknet、inception、mobilenet、genet、mnasnet等。随着视觉Transformer的发展,Transformer在越来越多的领域替代CNN,成为表达能力更强的主干网络。框架实现了常用的ViT、SwinTransformer等, 同时引入了PytorchImageModel(Timm) 用于支持更为全面的Transformer结构。
结合自监督算法,所有的模型支持自监督预训练和ImageNet数据监督训练,为用户提供了丰富的预训练backbone,用户可以在框架预置的下游任务中简单配置进行使用,同时也可以接入自定义的下游任务中。

4 易用性
1. 框架提供参数化方式和python api接口启动训练、评估、模型导出,并且提供了完备的预测接口支持端到端推理。
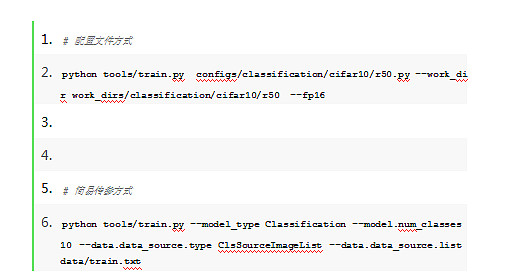
API方式
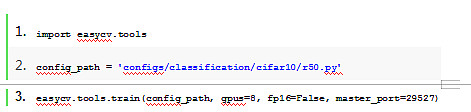
推理示例
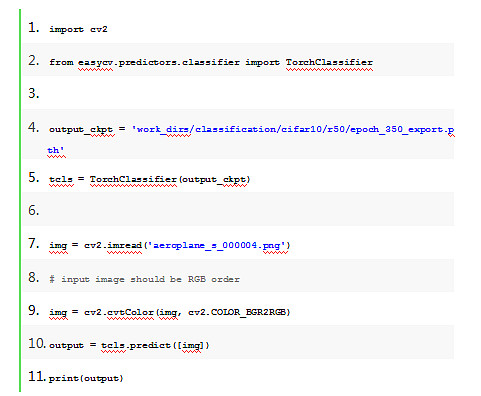
2. 框架目前focus在high-level视觉任务,针对分类检测分割三大任务,基于内容风控、智能零售、智能监控、同图匹配、商品类目预测、商品检测、商品属性识别、工业质检等应用场景,基于阿里巴巴内部的业务实践和服务阿里云外部客户的经验,筛选复现效果SOTA算法,提供预训练模型,打通训练、推理以及端侧部署流程, 方便用户进行各个场景应用的定制化开发。例如在检测领域,我们复现了YOLOX算法,集成了PAI-Blade的剪枝、量化等模型压缩功能,并能导出MNN模型进行端侧部署,详细可以参考模型压缩量化tutorial。
5 可扩展性
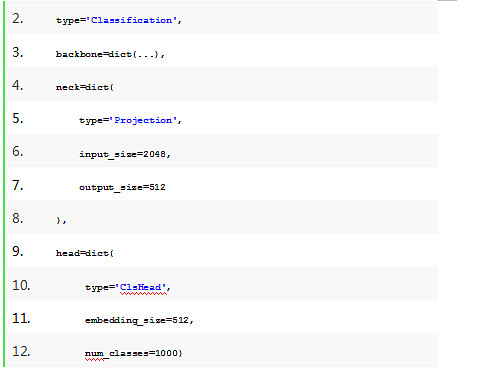
1、如技术架构图右侧所示,所有的模块都支持注册、通过配置文件配置使用Builder自动创建,这就使得各个模块可以通过配置进行灵活的组合、替换。下面以model和evaluator配置为例,用户可以简单的通过配置文件修改切换不同的backbone,不同的分类head进行模型结构调整。在评估方面支持用户指定多个数据集,使用不同evaluator进行多指标评估。

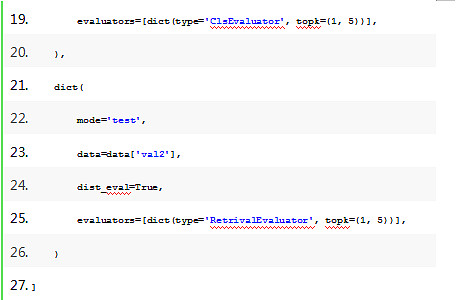
2、基于注册机制,用户可以自行编写定制化的neck、head、data pipeline, evaluator等模块,快速注册到框架内,通过配置文件指定type字段进行创建和调用。
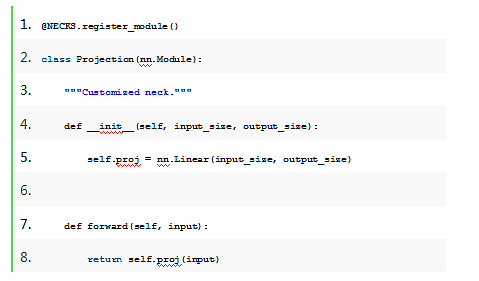
配置文件如下
6 高性能
训练方面,支持多机多卡、fp16加速训练、评估。
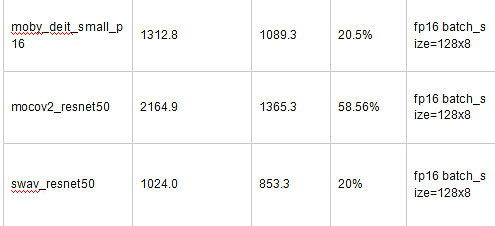
此外,针对特定任务,框架会做针对性优化,例如自监督训练需要使用大量小图片进行预训练,EasyCV使用tfrecord格式数据对小文件进行封装,使用DALI对预处理进行GPU加速,提升训练优化性能。下图是使用DALI+TFrecord格式进行训练,和原始图片训练的性能对比。

四 应用场景
如开篇所述,EasyCV支撑了阿里巴巴集团内10+BU20+业务,同时通过平台化组件的方式满足了云上客户定制化模型、解决业务问题的需求。
例如某BU使用业务图库100w图片进行自监督预训练, 在预训练模型基础上进行下游任务finetune,达到最佳效果,比baseline模型效果提升1%。多位BU的同学使用自监督预训练模型进行特征抽取,利用对比学习的特性,使用图像特征进行同图匹配的任务,与此同时,我们在公有云上也推出了相似图匹配的解决方案。
针对公有云用户,对于入门级用户,打通数据标注、模型训练、服务部署链路,打造顺滑的开箱即用的用户体验,涵盖图像分类、物体检测、实例分割、语义分割、关键点检测等领域的算法,用户只需要指定数据,简单调参即可完成模型训练,通过一键部署即可完成在线服务拉起。针对高级开发者,提供了notebook开发环境,云原生集群训练调度的支持,支持用户使用框架进行定制化算法开发,使用预置的预训练模型进行finetune。
· 公有云某客户利用物体检测组件定制化模型训练,完成其业务场景工人安装是否合格的智能审核。
· 某推荐用户使用自监督训练组件,使用其大量的无标注广告图片,训练图像表征模型,进而把图像特征接入推荐模型,结合推荐模型优化,ctr提升10+%。
· 某面板研发厂商基于EasyCV定制化瑕疵检测模型,完成云端训练、端侧部署推理。
五 Roadmap
后续我们计划每个月发布Release版本。近期的Roadmap如下:
· Transformer 分类任务训练性能优化 & benchmark
· 自监督学习增加检测&分割benchmark
· 开发更多基于Transformer的下游任务,检测 & 分割
· 常用图像任务数据集下载、训练访问接口支持
· 模型推理优化功能接入
· 更多领域模型的端侧部署支持
此外,在中长期,我们在下面几个探索性的方向上会持续投入精力,也欢迎各种维度的反馈和改进建议以及技术讨论,同时我们十分欢迎和期待对开源社区建设感兴趣的同行一起参与共建。
· 自监督技术和Transformer结合,探索更高效的预训练模型
· 轻量化Transformer,基于训练推理的联合优化,推动Transformer在实际业务场景落地
· 基于多模态预训练,探索统一的transformer在视觉high-level 多任务上的应用
项目开源地址:https://github.com/alibaba/EasyCV







