
近日,阿里云机器学习平台PAI与香港大学吴川教授团队合作的论文”Efficient Pipeline Planning for Expedited Distributed DNN Training”入选INFOCOM(IEEE International Conference on Computer Communications) 2022,论文提出了一个支持任意网络拓扑的同步流水线并行训练算法,有效减少大规模神经网络的训练时间。
作为分布式机器学习的一种主流训练方式,流水线并行通过同时进行神经网络计算与中间数据通信,减少训练时间。一个典型的同步流水线并行方案包含模型切分设备部署与微批量(micro-batch)执行调度两个部分。
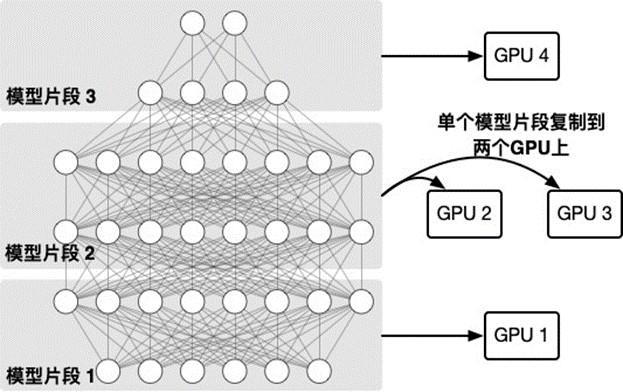
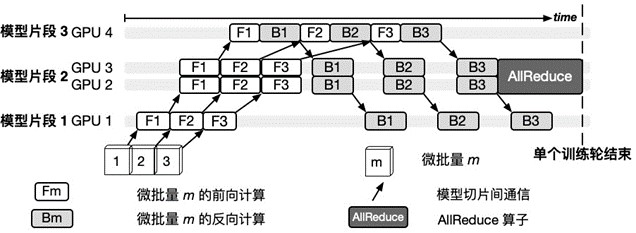
以下的两个图给出了一个6层神经网络模型在4块GPU上进行同步流水线并行训练的示例。由图表1所示,模型被切分成三个片段,其中第二个片段由于其计算量较大,被复制到两个GPU上通过数据并行的方式训练。图表2表示模型的三个微批量的具体训练过程,其中,由于第二个片段以数据并行方法在GPU2和GPU3上训练,在全部微批量训练完成后通过AllReduce算子同步模型片段参数。
然而,设计高效的流水线并行算法方案仍然存在诸多挑战,例如深度学习模型各异,每层的训练时间也不相同,因此难以找到最优的模型切分部署方案;当前的流水线并行算法局限于同质化的GPU间网络拓扑,而现实机器学习集群具有复杂的混合GPU间网络拓扑(例如,单个机器上的GPU可以通过PCIe或者NVLink连接,跨机通信可以基于TCP或者RDMA),导致现有方案无法使用等,以上问题导致实际训练中的GPU使用效率低。
针对以上难点,团队提出了一个近似最优的同步流水线并行训练算法。算法由三个主要模块构成:
1) 一个基于递归最小割的GPU排序算法,通过分析GPU间网络拓扑确定GPU的模型部署顺序,保证最大化利用GPU间带宽;
2) 一个基于动态规划的模型切分部署算法,高效率找到最优的模型分割与部署方案,平衡模型在每个GPU上的运算时间与模型切片间的通信时间;
3) 一个近似最优的列表排序算法,决策每个微批量在各个GPU上的执行顺序,最小化模型的训练时间。
从理论上对算法做出详尽分析,给出了算法的最坏情况保证。同时,在测试集群中实验证明团队的算法相对PipeDream,可以取得最高157%的训练加速比。
INFOCOM是计算机网络三大顶级国际会议之一,涉及计算机网络领域的各个方面,在国际上享有盛誉且有广泛的学术影响力。此次入选意味着阿里云机器学习平台PAI在分布式深度学习模型训练优化领域的工作获得国际学界的广泛认可,进一步彰显了中国在分布式机器学习系统领域有着核心竞争力。
阿里云机器学习PAI是面向企业及开发者,提供轻量化、高性价比的云原生机器学习平台,一站式的机器学习解决方案,全面提升机器学习工程效率。







