日前,火山引擎ByteHouse 联合InfoQ 发布白皮书《从ClickHouse到ByteHouse》,解读字节跳动万台节点ClickHouse背后的技术实现。
ClickHouse 开源于 2016 年,凭借性能方面的突出优势,在分析型数据库领域发展可谓风生水起。目前,国内外许多头部大厂都在深度使用 ClickHouse 技术。
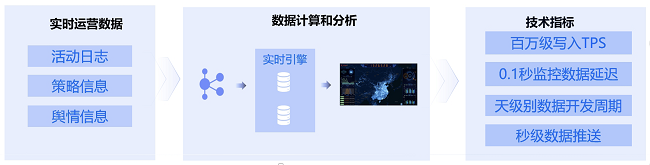
作为 ClickHouse 深度用户,字节跳动拥有国内规模最大的 ClickHouse 集群。目前,字节跳动数据节点总数超过1.8万个,管理总数据量超过 700PB,最大的单个集群部署规模约为2400余个节点。
《从ClickHouse到ByteHouse》白皮书客观分析了当前 ClickHouse 作为一款优秀的开源 OLAP 数据库所展示出来的技术性能特点与其典型的应用场景。
但是将 ClickHouse 引入企业级生产环境中,仍然存在许多实际问题。这也是火山引擎ByteHouse团队撰写《从ClickHouse到ByteHouse》白皮书核心出发点:深度还原字节跳动在大规模引入 ClickHouse 于业务实际生产环境所遇到的问题与解法,希望能给企业用户带来一些参考与启发。
白皮书显示,当字节跳动内部有越来越多的场景逐步深入使用ClickHouse之后,字节跳动也遇到了集群稳定性、应用场景使用限制等问题。因此,字节跳动对ClickHouse做了大量的深度优化与自研改造的工作,慢慢沉淀出了ByteHouse。
《从ClickHouse到ByteHouse》白皮书重点介绍了, ByteHouse 在 ClickHouse 上所做的三个重要方面优化与升级:自研表引擎、查询优化器、弹性可扩展。

在自研表引擎模块,尽管ClickHouse 提供 MergeTree Family、Memory、File、Interface 等几十种不同的表引擎,但是在字节内部实际使用中,还是明显感觉到了一些表引擎不足以满足业务的使用需求,于是进行了相应的优化。白皮书则重点介绍 HaMergeTree 、HaUniqueMergeTree、HaKafka 三种表引擎。
在查询优化器模块,ByteHouse对Optimizer进行了一年多的改造投入,全面升级产品能力。白皮书详细列举了ByteHouse在查询优化器上的改造与优化功能。
为了追求极致性能,ClickHouse 采用的是计算和存储节点强耦合的架构,不能根据各自实际需求分开扩容, 而且在节点扩展后数据无法自动重新分布的问题给ClickHouse扩展带来很多运维的麻烦。ByteHouse 在改进与优化ClickHouse的过程中,也重点基于该架构进行了调整。白皮书重点介绍了,ByteHouse 在存储和计算上的拆解解耦,实现弹性可扩展的技术优化方案。
与此同时,《从ClickHouse到ByteHouse》白皮书还重点列举在广告、金融、工业互联网三大行业的实践案例,这些都属于 OLAP 的典型应用行业,并从技术与企业落地等角度给出了当下企业在OLAP数据引擎选型的三个核心关注点。
目前,ByteHouse已通过火山引擎提供商业化服务,为客户带来极致性能、架构领先的企业级分析型数据库服务与技术支持。