近日,英特尔宣布Habana Gaudi2深度学习处理器在MLPerf行业测试中表现优于英伟达A100提交的AI训练时间,结果突显了Gaudi2处理器在视觉(ResNet-50)和语言(BERT)模型上的优势。
Habana Gaudi2处理器在缩短训练时间(TTT)方面相较第一代Gaudi有了显著提升。Habana Labs于2022年5月提交的Gaudi2处理器在视觉和语言模型训练时间上已超越英伟达A100-80G的MLPerf测试结果。
其中,针对视觉模型ResNet-50,Gaudi2处理器的TTT结果相较英伟达A100-80GB缩短了36%,相较戴尔提交的同样针对ResNet-50和BERT模型、采用8个加速器的A100-40GB服务器,Gaudi2的TTT测试结果则缩短了45%。
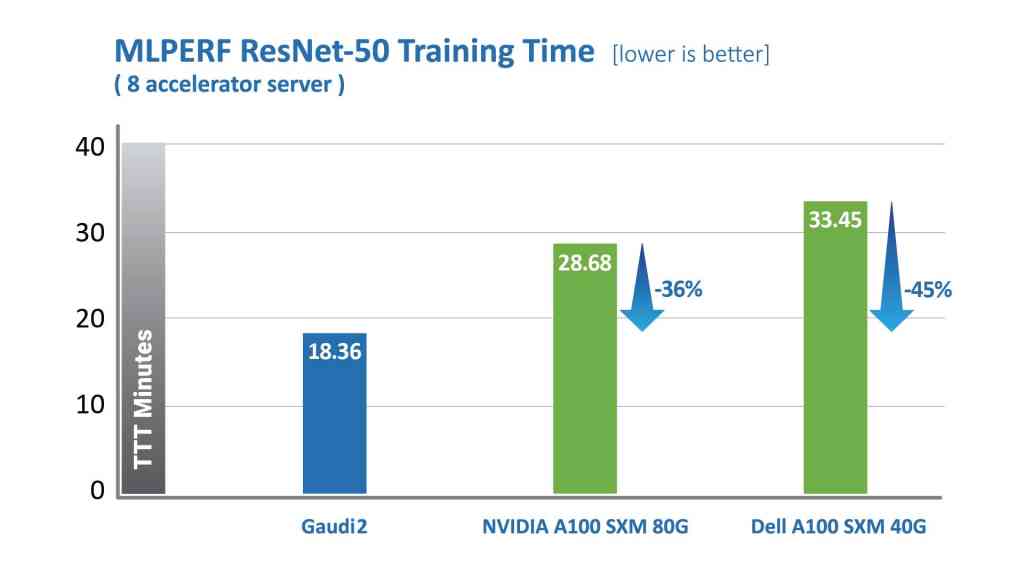
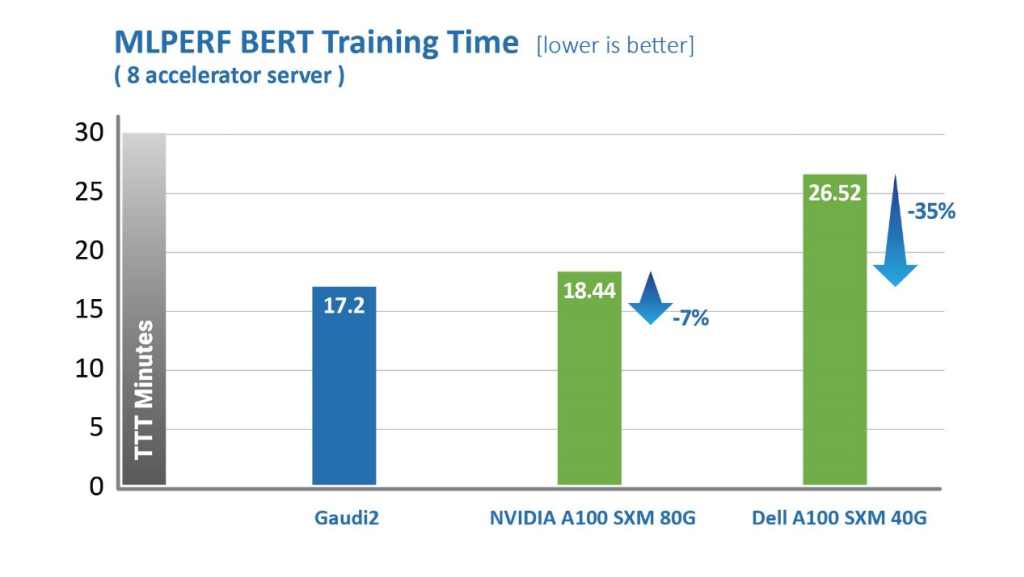
MLCommons发布的数据,2022年6月。https://mlcommons.org/en/training-normal-20/
相比于第一代Gaudi处理器,Gaudi2在ResNet-50模型的训练吞吐量提高了3倍,BERT模型的训练吞吐量提高了4.7倍。这些归因于制程工艺从16纳米提升至7纳米、Tensor处理器内核数量增加了三倍、增加GEMM引擎算力、封装的高带宽存储容量提升了三倍、SRAM带宽提升以及容量增加一倍。对于视觉处理模型的训练,Gaudi2处理器集成了媒体处理引擎,能够独立完成包括AI训练所需的数据增强和压缩图像的预处理。
两代Gaudi处理器的性能都是在没有特殊软件操作的情况下通过Habana客户开箱即用的商业软件栈实现的。
通过商用软件所提供的开箱即用性能,在Habana 8个GPU服务器与HLS-Gaudi2参考服务器上进行测试比对。其中,训练吞吐量来自于NGC和Habana公共库的TensorFlow docker,采用双方推荐的最佳性能参数在混合精度训练模式下进行测量。值得注意的是,吞吐量是影响最终训练时间收敛的关键因素。
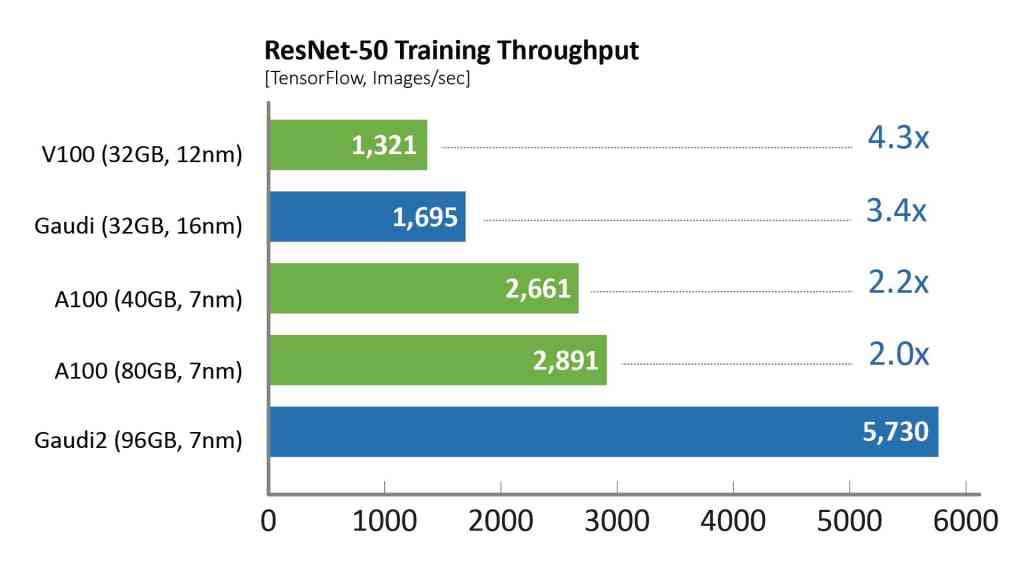
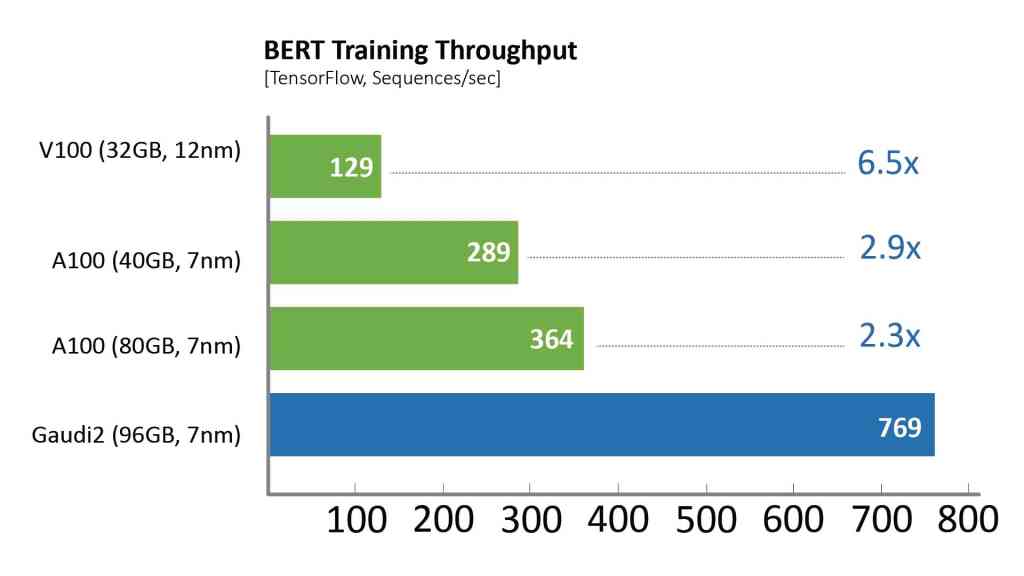
除了Gaudi2在MLPerf测试中的卓越表现,第一代Gaudi在128个加速器和256个加速器的ResNet基准测试中展现了强大的性能和令人印象深刻的近线性扩展,支持客户高效系统扩展。