Graphcore(拟未)正式发布其参与MLPerf测试的最新结果。本次提交中,Graphcore使用新发布的Bow系统分别在图像分类模型ResNet-50和自然语言处理模型BERT上实现了和上次提交相比高达31%和37%的性能提升。此外,Graphcore还新增了语音转录模型RNN-T的提交。
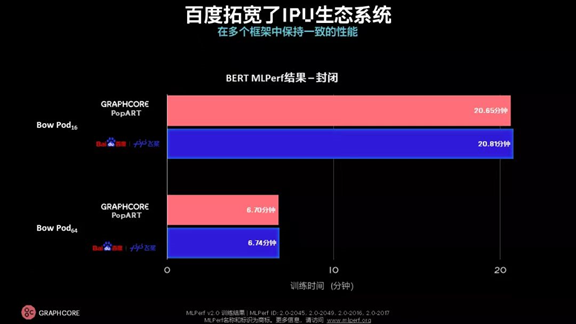
本次MLPerf提交中,首次有第三方使用了Graphcore的系统。百度飞桨使用Graphcore系统进行了BERT的提交,并展现出和Graphcore的BERT提交几乎一致的性能,证明了Graphcore的IPU所提供的性能可以有效地跨框架复现,以及IPU生态进一步繁荣的潜力。
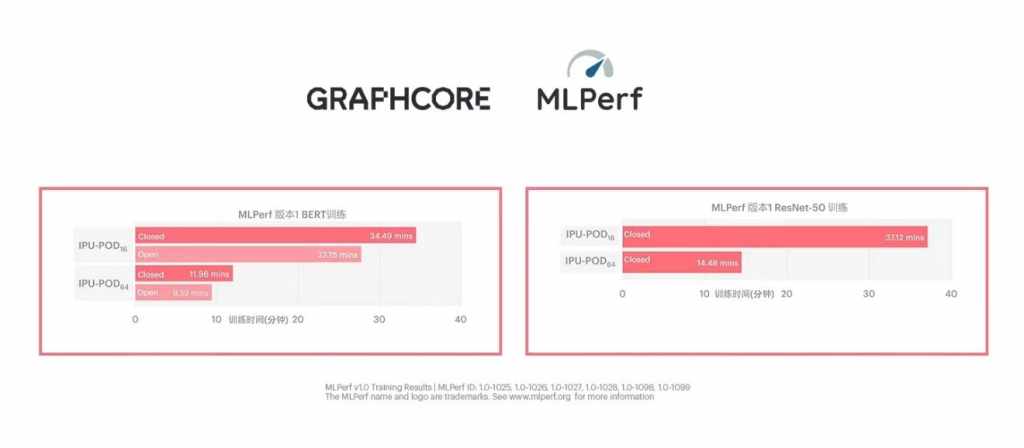
Graphcore此次在封闭分区面向ResNet-50和BERT两个模型提交了以3D WoW处理器Bow IPU为核心的Bow系统,包括Bow Pod16、Bow Pod64、Bow Pod128和Bow Pod256。和前代产品相比,Bow系统在提供更优性能的同时价格保持不变,进一步提升了Graphcore系统的性价比优势。结果显示,与上次提交相比,ResNet-50的训练时间提升高达31%,BERT的训练时间提升高达37%。
在GPU占据优势的模型ResNet-50上,Bow Pod16仅耗时19.6分钟,表现优于NVIDIA的旗舰产品DGX-A100 640GB所需的28.7分钟,再一次体现了Bow系统的性价比优势。

除此之外,Graphcore还提交了RNN-T在开放分区中的结果。RNN-T是一种进行高度准确的语音识别的精密方式,在移动设备上被广泛使用。在Bow Pod64上,RNN-T的训练时间可以从原本的几周缩短到几天。
Graphcore中国工程副总裁、AI算法科学家金琛表示:“对于本次MLPerf取得的出色成绩,我们感到非常自豪,这与Graphcore始终坚持创新密不可分。我们也非常高兴能够与百度飞桨联合进行提交,通过与百度飞桨的合作加速IPU生态系统的扩展,为产业赋能,推动各领域产业AI化转型和升级。未来,我们也将继续创新,应对不断增长的AI计算挑战,助力AI计算的演进。”
在本次MLPerf Training 2.0的提交中,百度飞桨使用Bow Pod16和Bow Pod64进行了BERT在封闭分区的提交,结果与Graphcore使用PopART进行提交的结果几乎一致。这充分证明了Graphcore IPU性能的跨框架复现能力。这一能力的实现得益于Graphcore灵活的硬件系统、持续优化的软件、强大的本地支持和合作伙伴的支持。正如此次提交,百度将Graphcore的Poplar®与飞桨软件框架相结合,实现了出色的性能结果。
百度飞桨产品团队负责人赵乔表示:“百度飞桨与Graphcore的合作,在本次MLPerf上获得了十分优秀的成果。Graphcore的IPU系统在合作中展现了出色的性能,在许多应用场景都展现出了巨大的应用潜力。我们期待进一步加深与Graphcore在硬件生态共创计划中的合作,以创新的技术加速AI产业落地,推动AI产业变革。”
百度飞桨已经实现了对于IPU的全面支持。Graphcore是百度飞桨硬件生态圈的创始成员,并在2022年5月正式加入了百度飞桨发起的硬件生态共创计划。未来,双方还将进一步展开合作,为开发者提供更多创新工具,推动AI生态繁荣,从而赋能产业中AI的应用和AI的商业化。产业中AI的应用落地,也必将反哺AI的发展和AI生态的进一步繁荣。