
大家好,我是TiDB解决方案架构师杜振强。我今天给大家分享的主题是《TiDB数据库云上探索和应用》。
我们先看看第一部分,我们先从商业上看云的发展趋势。
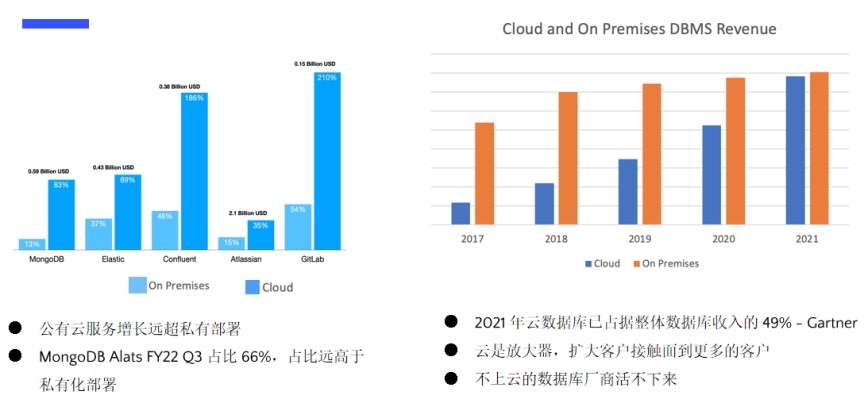
我们先看左边这个图,我们以几个典型的产品为例,比如MorgoDB Alats,他们云上的收入是云下收入普通3倍以上。其实在2022年前三季度,其云下收入已经占了整体收入的2/3,是远高于私有化部署的。从MorgoDB视角来看,它的云上已经是它的绝对的中心,占比占2/3,增速又是云下的56倍。这样就能看到云上面的发展趋势。
我们再看关于数据库,右边的图,我们能看到云上收入增速是非常快的,据统计来看,它是云下增速的2倍以上, 2021年几乎达到私有化部署收入的额度,在95%左右。预计2022年会超过私有化部署,这是全球的情况。国内发展趋势也是一样的,云上增速也是云下增速的两倍。预计国内在2025年左右,云上、云下收入应该会持平。
云对数据库厂商来说是一个放大器,是触达用户最短的并且最高效的路径,是直接沟通的一个平台,可以实现快速交付、反馈和迭代。从趋势和效率上来看,数据库厂商不上云很难活下来的。
2022年对于PingCAP的TiDB数据库来说,是一个大力投入云服务的一年,是TiDB云的元年。PingCAP在今年开始,已经在云上为用户提供正式数据库服务。
在2015年的时候,基本上没有提云原生数据库。但2019年的时候,最主要的议题就是云原生数据库。当然也包括数据分析决策,这也是云原生数据库排在第一位的需求,所占篇幅最大。
首先看看云原生是什么?
按照云原生计算基金会(CNCF)的定义,云原生就是“云计算+自动化管理+微服务”,但是对数据库来说,就不是那么好理解了。PingCAP认为云原生最主要的就是实现资源的池化,实现数据计算、存储、内存的池化,可以实现动态扩展、弹性扩展这些。
路径是什么?
我们认为它是利用云生的服务进行架构的设计,达到私有化部署无法达到的优势。如果说一个数据库设计的时候是基于私有环境进行设计的,它只是放到云上面,那它就不是一个云原生数据库。
我们再从用户的视角看看什么是云原生数据库?
PingCAP认为最主要的是弹性伸缩。用户按照自己的需求,计算不足的时候扩计算,自动的进行缩容。根据用户的实际需要扩展计算和存储,实现弹性伸缩的能力。再有就是高性价比,云上总体的成本要低于云下部署的成本,最好能实现按需付费。
最后是安全合规,因为数据库存储的数据是公司的核心数据,如果安全合规做不到,那一切都是空谈。
还有运维托管和点击即用。在云上要提供非常便利的平台,支持用户各种自助操作,其实就是我们说DevOps以及AIOps,提升用户运维管理的效率,在云上的时候,不需要预先准备资源。相反在云下,就需要先申请,还要走采购流程,走审批采购资源,这整个链路是非常长的。资源到位之后,也需要进行装机、部署、上线、交付,这些都是以“天”作为维度,最快可能也就是几个小时。但是在云上,可能就是点击一下,可能秒级就实现了,用户体验会非常好。
前面我们介绍了云原生数据库。下面我们介绍一下TiDB的云上托管平台。
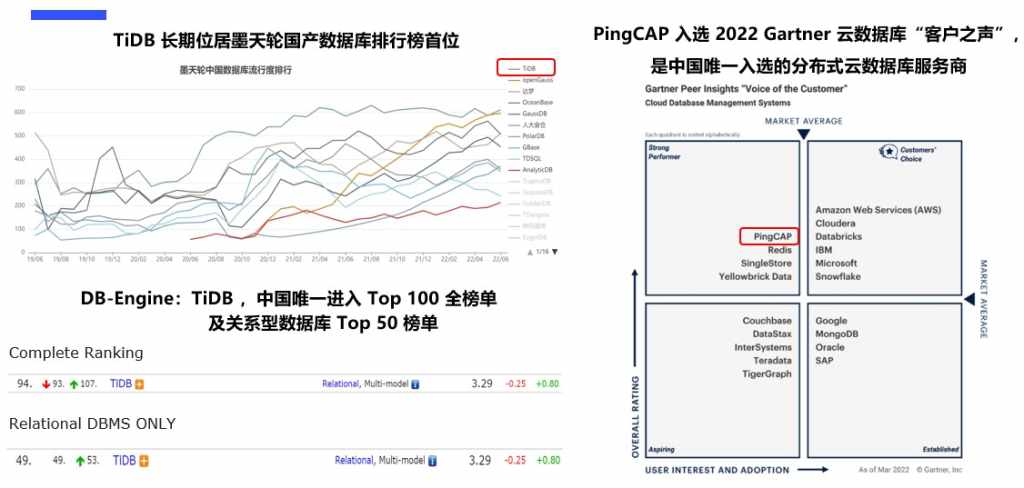
我们先介绍TiDB,TiDB长期在国内和全球获得了认可,长期位于国内摩天轮数据库排行榜的首位。在国际的DB-Engine排名里面,是中国唯一进入Top 100以及关键数据库Top 50的榜单。并且我们在Ping CAP入选2022 Gartner云数据库“客户之声”的奖项,获得了用户的认可,这是中国唯一入选的分布式运数据库服务商。
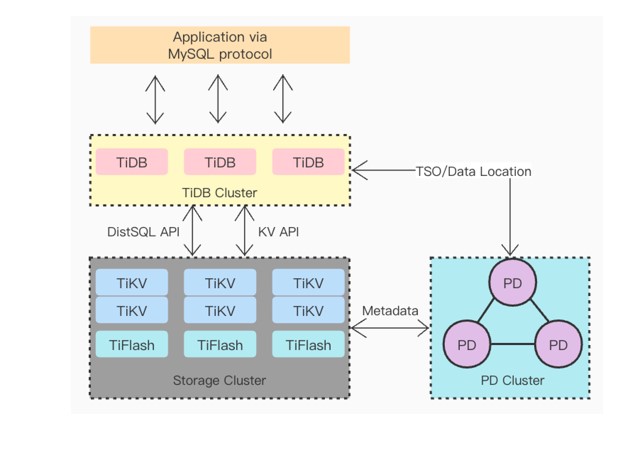
TiDB分三块。第一块是计算集群,它是一个无状态的,可实现弹性水平伸缩能力的组件,主要用来接收用户请求,然后解析,然后下发到存储层,给用户进行反馈。
下面的TiKV和TiFlash是我们的存储层。TiKV是行存,TiFlash是内存。两者之间在物理上是隔离的,互不影响。TiKV用来实现线上高频交易,也就是OLTP的负载,TiFlash主要用来做OLAP类查询,这就是TiDB数据库的主要能力。
右边PD节点是用来管理我们的云数据的。简单理解,它主要有两个功能,一个是管理我们的数据,我们会把它的水平拆分成一个最小的管理节点。PD里面就是存储这些信息,可以理解为它是一个路由信息,给TiDB提供路由的服务,TiDB就知道我的记录会存储在哪个里面,从而到相应的存储里面去进行相关的操作。
从这个架构来看,它其实就是一个存储、计算、分离的架构。可以实现水平扩展,并且是一个分布式HTAP数据库。数据可以实现一致性,因为TiKV之间一般是3复本或者5复本这种一致性,可以实现数据的一致性,保证数据写入之后,这个数据一定是不会丢失的,并且是兼容MySQL协议,降低用户接入的成本。本质上就是一个云原生分布式数据库。
下面我们再介绍一下TiDB的云上托管平台,我们叫做TiDB Cloud。
它是云上的托管平台,支持一键部署,扩容和缩容,以及相应的管理。并且它是一个多云池,是一个云中立的产品。在国外支持AWS,国内支持阿里云、京东云等。
业务的联线是通过自动备份、多可用区复制来实现的自动备份是数据库基本的功能。多可用区复制,TiDB作为一个分布式的数据库,既然就是高可用的,自带高可用,自动的实现容灾。比如说在3个机房部署,在任何一个机房宕机都不会造成影响。
安全合规是云厂商的必修课,如果说安全合规做不到,客户就不会放心把自己最核心的资产去使用的。如果数据泄露就会非常麻烦。TiDB获得了多个国际的安全认证。
技术支持这块,我们提供多种方式的支持,快速、高效的支撑体系。计费是最基本的要求,我们可以实现用户按需使用,按需付费。
TiDB Cloud总体的架构大概是这样子的,主要是基于云厂商提供的AWS服务,有统一的管控面。内部我们会提供单独的VBC然后进行部署,然后通过Pooling的方式和用户的应用进行打通,然后来进行数据库服务的接入。
上云之后,可能只是开始。云原生是要基于云上基础设施,然后来去不断的优化、迭代架构。所以下一步就有必要对云上服务商进行共生适配,来解决云下无法解决的一些痛点。
在云下,PingCAP已经是一个存算分离的架构了。云原生,我们认为不管是实现资源池化,其实最重要的一点就是要实现存算分离,这个基本上是许多云上优势的前提。如果实现了存算分离,就可以实现更灵活的资源伸缩、弹性缩容,并且实现Serverless,这是一个基础。
所以不管我们做成什么程度的Serverless,其实都是需要不断的优化的,就TiDB自身来看,它已经是一个存储计算分离的架构。Tikv作为存储,TiDB作为计算,两者都是一个集群模式,可以单独的进行扩展。
在云下,我们的数据是拆分在不同的TiKV。
如果说TiKV,比如这个机器宕机了 ,那可能就要扩容一个机器,比如说3个复本,丢了1个复本,我们就要把另外1个复本补齐,这个成本其实相对来说是比较高的。在云上,比如说基于云上的云盘,比如EBS这种高性能的云盘。云上的话就不需要搬,可以省略这个过程了。就是因为机器宕机之后,EBS还是可用的。这样的话我们申请另外一个机器,直接把EBS盘放上去就可以了,避免了云下需要补数据的过程,降低对用户的影响,并且也降低宕机缺失复本的一个状态。
当然这些够了吗?其实也不够,因为云上还有更多的存储的服务,比如说S3,它非常的廉价。后续我会介绍一下怎么和S3进行结合,来实现更彻底的存算分离。
TiFlash这个组件其实是存在耦合的,现在为了实现OLAP的实时性,也实现了MPP(并行处理)的能力。其实大量的计算都是在TiFlash上进行计算的,它就包括了数据的存储,又包括数据计算,实际是一个存算耦合的状态。这其实在云上,它不是一个非常理想的状态,没法按照需求,比如计算扩容或者存储扩容。所以下一步我们要基于云上的EBS+S3对于TiFlash进行存算耦合。
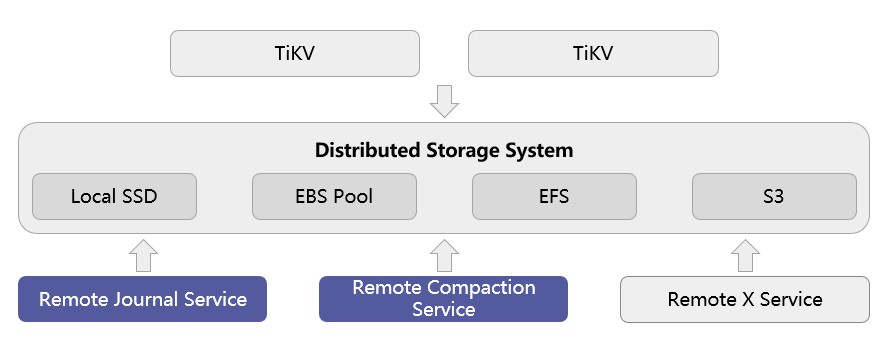
TiKV进一步存算分离,下一步主要是想利用S3。简单概括来说就是,将所有的全量数据全部下到S3。作为TiKV服务,如果在OLTP上面,它是低延时、高吞吐的附载,不适合放在S3上面,因为S3的延迟非常高,延迟可能是200~300毫秒以上了,并且没法应对大并发,和OLTP服务看起来是完全不相干的,完全无法支持。
那么怎么解决呢?
我们也会把TiKV本地磁盘利用起来,会将TiKV上面的数据在本地缓存一份,这样的话我们可以利用本地磁盘实现高吞吐、低延迟的OLTP请求。然后我们写入,因为底层都分布的,如果需要合并的时候,只需要在TiKV主机端进行合并,合并完了之后通过S3发落到各个节点,然后实现这么一个过程。
可能有质疑会说:既然本地磁盘也存储了TiKV上面的缓存数据,那成本会不会比较高呢?这个担心也是有道理的,我们强调3复本,本地也会缓存数据。我们的考虑是,一是S3的成本非常低,它的成本可能是1/5~1/6。此前,3复本宕了1个复本之后,数据就要进行恢复和补齐,这个时间会非常长,如果这个过程中再宕1复本,将导致整个数据都不可用了。
但是基于S3的话,如果说宕了1个复本之后,它会快速的从S3里面把数据弄上来,这个时间可能补数据时间的1/10甚至几十分之一。也就是说我们弹性的能力提升了几十倍的增加,那我们可能不需要3个复本了,我们可能需要2个复本加一个S3的方式就可以了,这样的话整体上也会降低成本,也节约了用户的使用成本。
这就是TiKV进一步的存算分离。
下面我们也会把TiDB的各种服务进行拆分,只有充分的进行拆分,才能对各个功能进行扩展,然后选用合适的资源来承载,降低用户的使用成本。
TiFlash存算分离,它的思路有些类似。后面更多服务解耦,不管是TiDB上面的DDL,DDL服务是一个非常重的服务,有可能会影响所在的TiDB节点的稳定性。我们拆出来之后,根据需要来扩展它的能力。比如说Lock服务,以及授时服务、调度服务,我们都可以把它拆出来放在在云上。
最后是云端生态集成。我们在上游要和各个RDS、SQL Server兼容。在下游的话我们需要和大数据这一套结合,这些我们都在做的,以及和云厂商不断的进行兼容,这一块也是持续建设的一个过程。
下面我们看看典型的用户案例。
第一个是日本某头部移动支付公司的案例。他们是2018年成立的,之后因为用户的快速扩展,用户从1500万增长到4000多万的过程中,整个架构之前是基于java、Springboot架构来实现的。写入这块会出现明显的瓶颈。并且如果要记录的话只能分库分表。这样对用户的业务上来说,快速发展,首先时间不允许,其次对业务的冲击会比较大。业务需要进行分库分表的改造,这个周期会非常长,投入大,产出其实也是比较有限的,严重阻碍了用户的发展。所以用户进行选型选到了PingCAP,服务主要是钱包服务业务,所有的线上服务都会通过钱包来服务。实现了60TB,高吞吐量,提升了5倍以上,满足了用户扩展性的需求。并且提供低延迟,整个延时比Aurofa要低30%,高吞吐。

对于用户来说还有一个比较意外的收获是,之前是基于高可用性,之前东京出现异常,当时TiDB什么也没有做,在秒钟内进行了恢复。之前用Aurofa用户受影响就比较大,用户有数据的丢失。但是TiDB只影响了15条信息的失败,确保了跟用户的粘性,这个对用户来说体验非常好,当时给我们这边反馈说是一个非常意外的收获。
第二个案例是网易游戏用户画像,主要是处理网易100多款游戏登陆支付数据。根据登陆日志统计用户的活跃度,用户画像的服务。有各种指标,根据这些数据输出实时的信息,比如总消费、时长、曲线、用户的VIP等级等等。有这些数据之后就可以交给市场和营销部门来进行精准的广告推送,并且也会给用户提供针对性的充值优惠,以及推送各种新游戏。这样的话将整个游戏的运营水平提升上来。用户画像其实是一个游戏运营中最核心的系统,他们之前是在MySQL上做的,之前可能一款游戏就是一套,之间都是割离的数据孤岛,并且也无法满足实时的查询。

最后通过使用一套TiDB集群,将整个100多套游戏的数据全部存储起来,然后为一线提供服务。主要是将多元数据进行汇聚,然后进行实时的查询,实时的数据分析。同时为用户画像、报表监控以及运营整个提供数据服务,整个是超过万级别的。
并且也会提供计算层的,和大数据进行连通。这样的话可以打通在线和大数据这块,打破不同的技术战的壁垒,为用户实现价值最大化。
整体来说,对用户的价值来说,架构比较简单,一套TOB就能实现OLTP的查询,又实现OLAP的数据分析,降低用户的运营和使用成本。并且降低了整个链路,大数据链路,降低出风险的概率,提高可能性。同时,提供了准实时的数据分析能力。还有降低用户的使用成本,整个资源投入产出比达到MySQL同等QPS的1.5倍。当前网易有90多套集群都已经在使用TiDB了,总数量可能达到500多TP吧。
我今天的分享就到这里,谢谢大家!
( 本文基于速记整理而成,未经过本人审阅 )







