
我们平时数据库所接触到的业务场景一般具有不可预知性,可能业务数据规模会不断扩大,这个时候需要对这个机型做一个扩容,也可能业务读写操作会集中在某一段数据上,其他范围的数据会相对空闲一些,这样会导致一个后果,少部分的节点承担了整个集群大部分的压力,为此就需要做负载均衡。
以双11场景我为例,压力在一段时间内有一个猛增,对此需要能够及时调度数据库,把压力分摊到很多的节点上。这种业务的不确定性就是一种敏态,如果数据库没有办法应对这种场景,有可能会导致读写比较缓慢,甚至服务不可用。
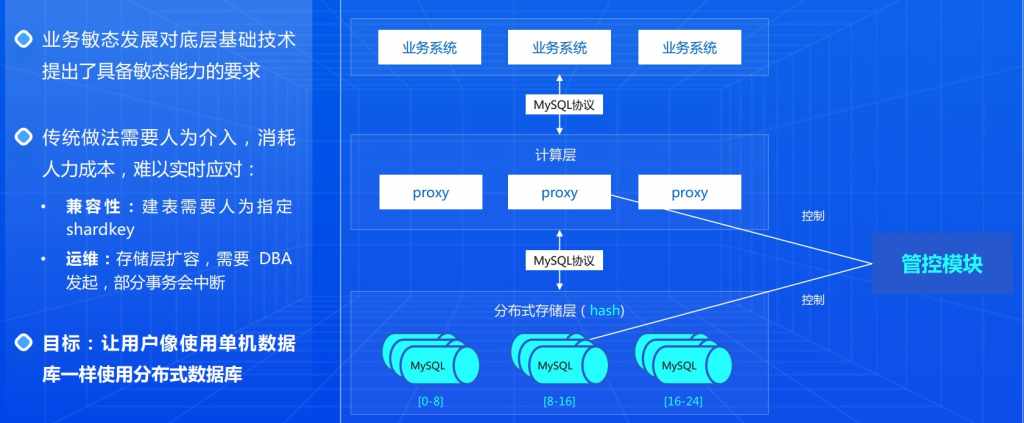
为了应对这种敏态场景,传统做法是人工介入,比如在建表的时候,需要人为指定一个shardkey做分表,但是一般这种方法SQL语法未必能够兼容所有数据库,另外也需要用户自己去预判数据热点,不是很灵活。同时还有一点,比如需要扩容的时候,一些普通的场景需要DBA(数据库运维工程师)发起,可能会中断这个业务的执行。人工扩容没有办法及时处理。
想让数据库能够具备一个自主应对敏态场景能力,尽可能解放人力,让用户像使用单机数据库一样使用分布式数据库。
首先介绍一下TDSQL的架构,这是一个TDSQL的整体架构,它是一个全分布式的,并且实现了存算分离的数据库,它由三个模式构成,首先最上面的是MySQL Engine,它是一个计算节点,它的一个目的是将SQL语句转化成KV请求发送给存储集群,它会做一些查询弱化。
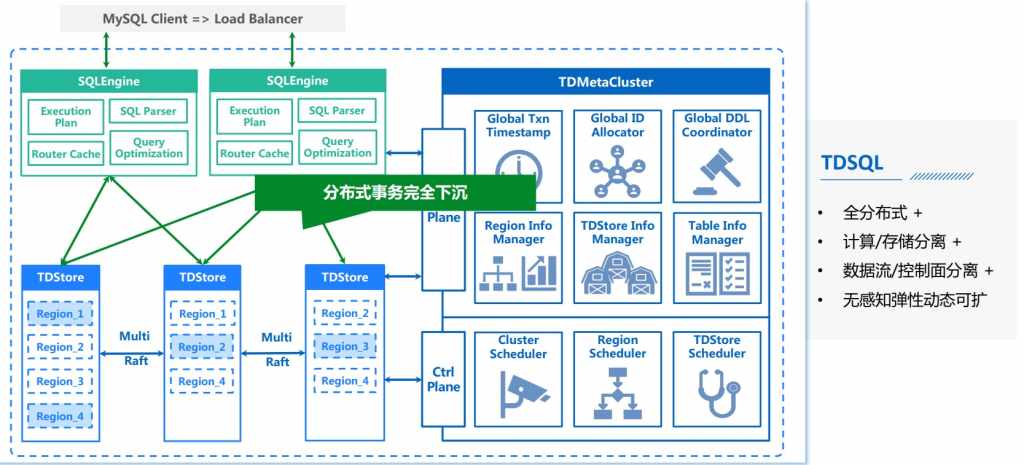
下面这个是TDStore,它是一个Share Nothing存储的分布式集群,它是一个KV的存储模块,用来接收Engine下发的一些KV请求,可以看到TDStore做了一个数据分片,把整个范围的数据划分成各个连续的Region,每一个Region其实是一个独立的Raft pool,它的Raft pool每一个副本是打散在不同的TDStore上,这样我们就实现了一个初步的负载均衡。TDStore同时提供了一个分布式事务的下沉,使用2副本保证一个分布式事务提交的原子性。
右边这个模块是一个全局的原数据管理模块MC,它提供的是一个全局递增的时间戳管理,还有它提供了一个全局的资源调度,比如说发现某一个TDStore压力比较大,这个时候它就会向TDStore下发调度任务,把它的一部分压力均衡到另外一些压力不怎么大的TDStore节点上,这样就实现了一个比较初步的负载均衡,等于说对于这种敏态业务的支持是离不开MC的帮助的。
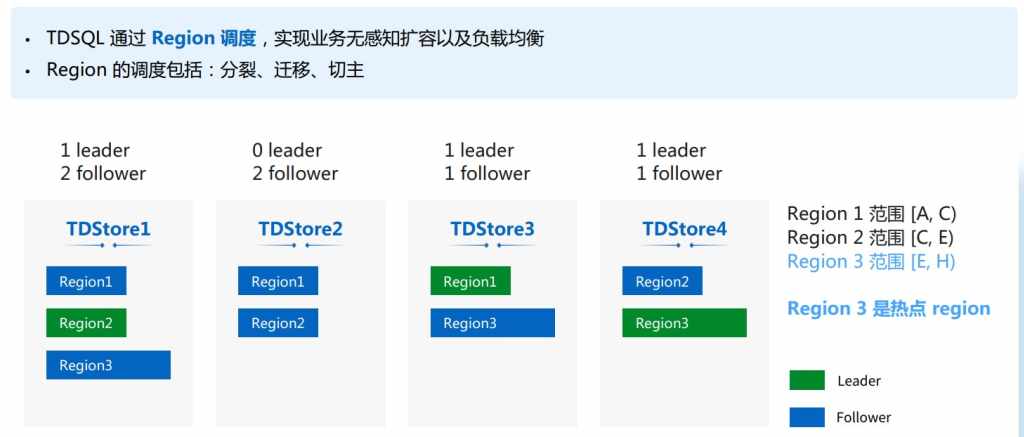
接下来简单介绍一下TDSQL是如何去进行数据的调度以及负载均衡的,介绍一下Region调度原理。
Region目前的调度分为分裂、迁移和切主三种,刚刚提到过TDSQL其实是以Region做数据管理的,也就是说每个Region管理的是一段连续范围的数据,并且每个Region都是独立的Raft Pool,所以这些Region的副本会散落在不同的TDSQL节点上,可能每一个TDSQL所包含的Region数量是有所差异的。同时SQL Engine是向Region Leader副本下发读写请求的,所以Region Leader副本要比follower副本承担更多的压力。由此可以得到一个初步结论:如果观察到一个TDSQL节点包含了比较多的Region副本数,或者它上面的Leader副本比较多,说明这个TDSQL就承担了比较多的压力。
这里举一个具体的例子,这个图上展现的是4个TDSQL构成的存储集群,其中包含三个Region,我们可以看到Region3比较大,表现上面的数据比较多,读写比较频繁,所以是一个热点Region。此前我们提到过。Region Leader要承担更大的压力,所以对于热点Region3 Leader所在的TDSQL4节点压力会更多一些,同时我们可以看到TDSQL1有3个副本,而其他的TDSQL都只负责两个副本,所以TDSQL 1压力也比较大。
因此我们最终想达到一个目的,我们想把TDSQL1和TDSQL4的一部分压力转到压力比较小的TDSQL2上。
具体怎么实现的?
首先看一下Region分裂的大概原理。
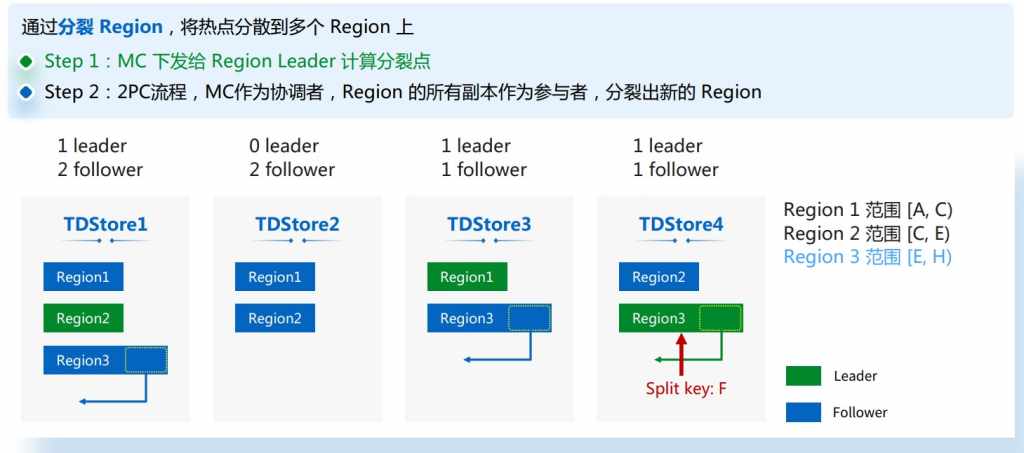
首先我们的Region仅仅只是一个逻辑上的数据分区,可以看到它展现的是一个大概分类流程,比如说一开始Region1范围是A到E,包含了ABCD四个数据,经过分裂以后可以看到底层的ABCD四部分数据没有变动,唯一变动的只是说新增了一个新的Region2,原来的Region1我们称之为OLD Region,新产生的Region我们叫做New Region,可以看到Region1范围变成A到C,包含的数据是RegionB 2个,Region2的范围是C到E,它所管理的数据是Region D,也就是我们经过分裂以后得到的两个Region,他们分别承担的是分裂之前的Region的50%的压力,这样下来等于说我们可以起到把一个压力比较大的Region给分裂成两个新Region,这样就可以摆脱一个热点Region的情况。
回到刚刚的例子,首先当我们要触发分裂的时候,MC会向Region的Leader下发一个计算分裂点,Leader收到以后会通过二分法找到整个Region范围内的数据中间点Key,把这个Key返回给MC,MC收到以后会重新向每一个Region副本下发分裂任务,当TDSQL收到分裂任务以后,它会在TDSQL上产生一个Region 4,相当于Region 3的数据范围变小了,把它的后半部分Region范围单独拆分出一个新的Region 4,这样来看虽然Region的热点没有了,但是从TDSQL压力来看,没有太大变化,比如说TDSQL 4,现在它变成了有两个Leader,一个副本的节点,而TDSQL更是承担了4个副本的压力,所以我们下一步的目的就是把TDSQL1和TDSQL4的压力均衡到TDSQL2上。

通过Region迁移去分担一部分TDSQL1的压力,具体的方式就是MC会向要迁移的目标节点,也就是TDSQL2下发一个添加副本的任务,TDSQL2收到以后会创建一个Region4的副本,等于短时间内Region4从3副本变成4副本的Group,我们的MC会向TDSQL1下发一个销毁副本的任务,等于Region4就被销毁掉了,Region4的副本数又恢复到3个。
经过一番操作以后,可以看到TDSQL1变成一个Leader和2个Follower,它的压力降低了很多。
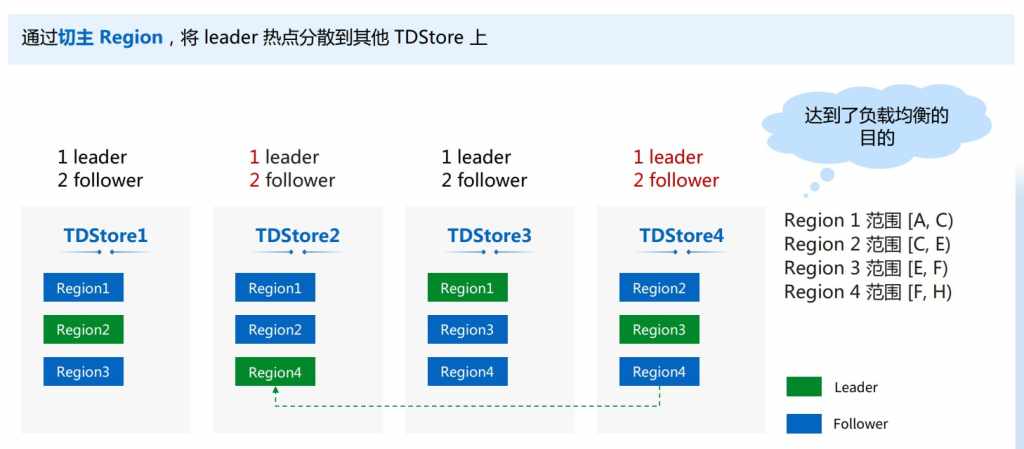
下一步我通过切主的方式把TDSQL4的Leader切到TDSQL2上,可以看到所有的TDSQL都变成了有1个Leader和2个Follower的情况,等于它的负载就得到一个均衡。
当然刚刚的演示仅仅是一个示意。实际在生产环境中,Region的数量还有TDSQL节点数量会有很多很多,同时针对同一个Region的分裂迁移和切主三种任务,可能也不会是这么紧凑的接连执行。这里有一个原因,如果没有特殊处理,Region的分裂和切主可能会对事务执行有一些影响,影响业务的正常进行。
接下来将重点考虑TDSQL是如何尽量优化事务跟Region调度的并发,去做到Region调度不杀事务(以下部分内容比较技术,详情可参见Doit学院的有关视频。)。
(本文基于腾讯云数据库高级工程师刘畅演讲速记整理而成,未经本人审阅)







