
据IDC预测,2026年中国大数据IT支出规模预计为360亿美元左右,其中复合平均增长率约为21.4%,位列全球第一。从以上数据可以看出,中国大数据市场前景是非常广阔的。

接下来看一下数据库发展历史。
在1960年左右出现了数据库,紧接着在1970年左右出现了关系型数据库,典型代表如MySQL,1980年左右出现了数据库仓库的理论,并且出现了MPV架构的数据仓库,1998年左右出现了NoSQL数据库,典型代表如MongoDB。
随着2000年互联网的快速发展,出现了大量的非结构化数据处理的需求,紧接着在2006年~2009年出现了Hadoop Spark代表的大数据平台,同时在2006年AWS推出了云计算业务,很多数据开始上云。在2010年左右出现了分布式流数据处理,典型代表如2010年出现的Storm平台,2013年出现的SparkStreaming,2014年出现的Flink产品,同时在2010年还出现了数据湖的概念,2017年~2019年出现了Delta Lake、Hudi、Iceberg等数据湖产品,2013年~2017年是云原生快速发展的几年,出现了如Kubernetes这样的技术,很多数据库、数据仓库、数据湖产品都基于云原生进行构建,在2020年左右出现了湖仓一体化的数据平台。
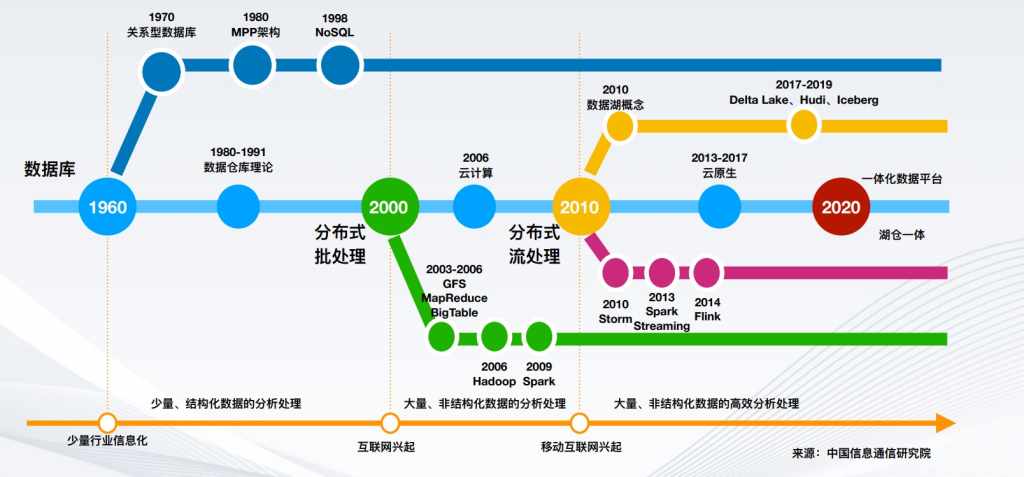
从以上可以看出,从1960年到2020年左右数据平台一个大概的发展历史,接下来分别看一下数据库、数据仓库、数据湖包括湖仓一体的产品。
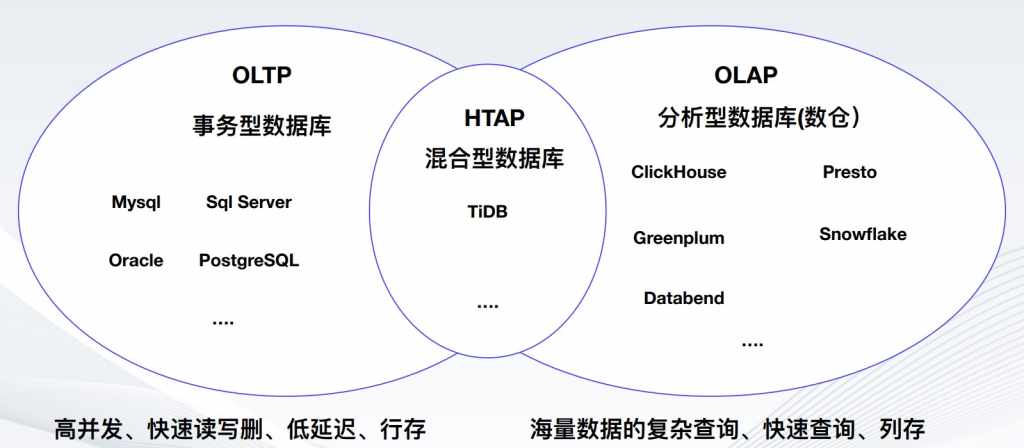
数据库是我们大家所熟知的,比如你去商场里购买了一件产品,这个商品它会记录进入到数据库中,是什么时间点购买哪件产品,这个产品的价格是什么,这通常称为事务性数据库,典型代表如MySQL、Sql Server、Oracle、PostgreSQL,特点在于要处理高并发、快速读写删的能力,并且是低延迟的,通常采用行存数据库方式。
还有一种数据库是偏向于分析型的,它重点在于是哪类人购买了哪类产品,它的用户画像是什么样的,这类数据都是通过分析型数据库进行处理的,它的特点在于是海量数据的复杂查询、快速查询、通常采用列存。典型代表如ClickHouse、Presto、Greenplum、Snowflake、databend,都是属于数仓库类似的产品。
还有一类需求,就是既有事务性数据库的需求,也有混合型数据库的需求,那就是出现了HTAP混合型数据库,典型代表如TiDB,它既可以做TP类的事务处理,也可以做AP的数据的处理,但是如果说特别大量的数据处理,建议还是用OLAP类数据库进行处理。
接下来看一下什么是大数据平台,大数据平台主要有以下特点:
第一是数据量大,通常是TP、PB甚至是EB级的数据。
第二是数据类型繁多,结构化、非结构化、日志、视频、图片、地理位置等等,这些数据都需要进行处理。
第三,商业价值高,但是这种价值需要构建在海量数据之上,通过数据分析、机器学习进行挖掘出来,提供给前端的业务系统。
第四,处理实时性要求高,海量数据的处理要求不局限在离线中,而是推荐系统,它的实时性要求非常高,不等看完短视频,接下来就推荐其他的,看完战争片以后,给你推荐的爱情片,可能就不是他所喜欢的,就体现不了它的价值。
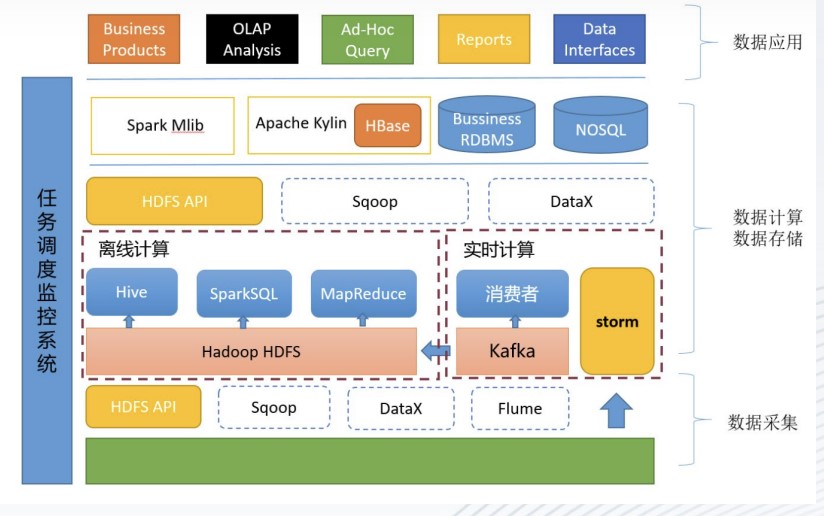
这是一个大数据平台典型的架构,从下往上首先是数据采集,所采集数据源可以是多种多样的,比如说是从其他的数据库中,事务性数据库或者其他的数据库中进行采集,可以是文件系统,可以是日志等。
之后进行数据的计算和存储,再往上是数据的应用,比如说是通过OLAP的数据仓库进行分析。
接下来看一下数据湖与数据仓库之间的关系,数仓主要是偏向事前的建模,数据湖主要偏向事后的建模。数据湖通常是把所有的数据结构化、半结构化、非结构化数据放到里面,都可以进行存储,之后根据这些数据进行建模处理,数仓则不同,通常在建模之前就进行数据的一些提取、抽取、分析,所以说它偏向于做事前的建模,而且它的存储通常是结构化、半结构化数据。
引擎方面也不太一样,数据湖是多种引擎都可以用,有多种数据源进行有限的优化,数据仓库是特定的数据引擎,通常选用一种数据引擎,或者说是两三种特定的数据引擎,根据它的数据特点或者业务系统的要求选择特定的数据引擎,经常对数据进行高度优化,甚至数据处理过程高度优化。
项目启动方面也不太一样,数据湖是易启动的,只要你有需求就可以快速的建立数据湖,把非结构化数据、结构化数据进行存储,数据仓库是需要提前规划、提前运作的。
治理方面也不太一样,数据治理方面,数据湖是偏向于数据量比较大,数据仓库也是数据量比较大,但是更强调数据质量。数据湖通常是做一些数据机器学习,做一些数据挖掘,数据仓库偏向于提供给前端的BI展示,可视化方面。
聊完了数据湖、数据仓库之后,我们来看一下2020年左右出现的湖仓一体,湖仓一体是一种将数据湖的灵活性和数仓的易用性、规范性、高性能结合起来的一种新型架构,类似于在湖边搭建的很多小仓库,把数据湖中不同的数据进行有效的分析,或者通过机器学习甚至来检索音视频信息等等处理。

说到了湖仓一体,先看海外的两个产品,第一个是Snowflake,它之前是一直做数仓这个产品起家的,但是随着业务量的逐渐发展,现在它提出了DataCloud理念,这是一个数据云平台的概念,它也逐渐的往湖仓一体方向发展。databricks是2013年由伯克利大学的研究人员成立的,偏向数据湖的概念,现在它也具有部分数仓的能力,所以说这两个产品越来越靠近,他们的产品边界越来越模糊,snowflake可以作为一部分湖的数据处理,databricks可以做一部分数仓的处理,他们逐渐都往湖仓一体的架构演进。
接下来看一下什么是新一代云原生数仓。
新一代云原生数仓同传统数仓相比有以下特点。
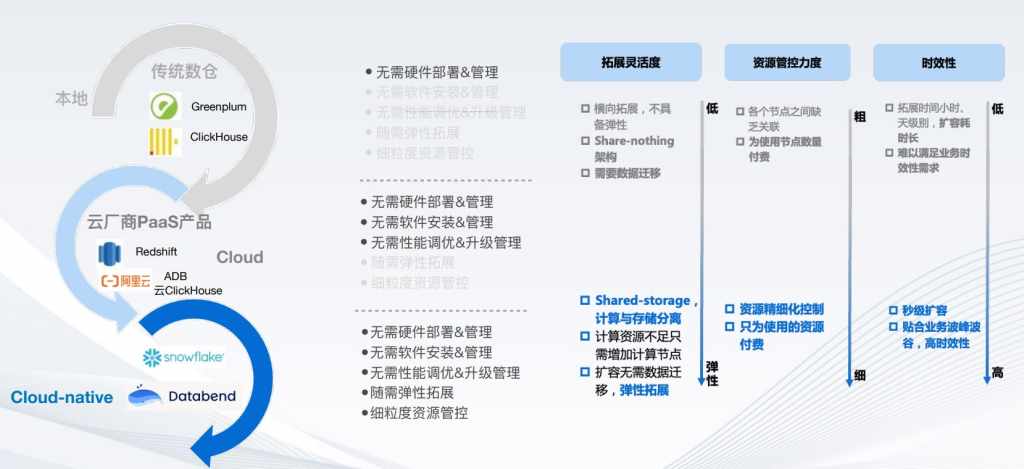
第一,传统数仓是在云计算发展之前就已经出现的,1982年左右出现了数据仓库,当时还没有云计算,它通常是采用存算一体的架构,比如Greenplum、ClickHouse都是这样的产品形态。随着云计算的发展,开始把这些产品搬到云上,典型的代表如K8S推出的Redshift,阿里云推出的云ClickHouse等等,相对用户来说不需要基于虚拟机或者物理机,重新去搭整个数仓平台,可以一键化部署出来,性能调优云厂商也会做,升级管理也会做,但是这样的产品形态还是存算一体的架构,只是省了整个的搭建过程,甚至是部分的运维工作,但是还是需要运维整个数仓平台的。
2012年出现了Snowflake产品,讲究存算分离的架构,基于云计算进行构建的,底层基于对象存储,上层的计算节点是可以随意扩展的,所以说跟着业务量进行扩展,包括Databend也是存算分离的架构,基于云原生构建的,底层基于对象存储,上层的计算节点可以跟业务量进行随意扩展。相对于传统数仓来说,其灵活性非常高,业务量繁忙的时候可以增加计算节点,底层存储节点,因为都是存在对象存储之上或者共享资源池,通常对象存储是没有容量限制的,这样只需要增加上层的计算节点就可以了,所以说灵活性非常高。而传统数仓灵活性相对差一些。
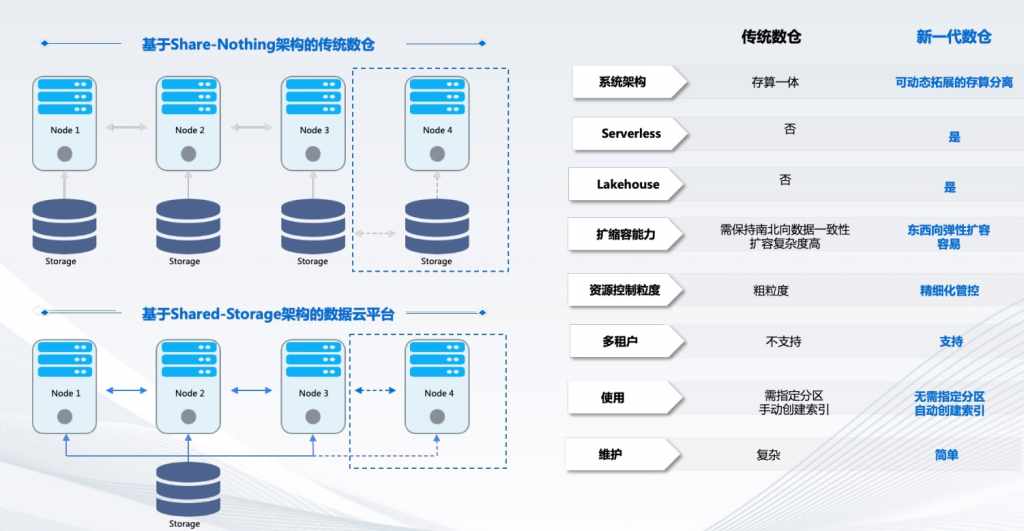
讲一下传统数仓和新一代数仓的差异,左侧是传统数仓和新一代数仓的示意图,传统数仓是基于Share-Nothing进行构建的,它的特点首先是计算单元和存储单元是一体的,比如构建在物理服务器或者虚拟机上的,如新增加一个结点,需要将原有数据放到新的节点上来,这就需要保证原有数据安全,做一些备份操作,其次新节点还要校验整个数据的一致性,过程是非常复杂的。
左下图可以看到新一代的数仓通常是基于Share Storage架构构建的,底层是共享存储,可以是对象存储,可以是软件定义存储,其上层的计算节点是无状态的,而底层存储系由对象存储保证的。
右侧列出了传统数仓和新一代数仓的差异,首先从架构地方面:传统数仓是存算一体架构的,而新一代数仓是基于可扩展的存算分离架构的,现在有部分传统数仓也会基于存算分离架构进行改造,可以支持对象存储,但是这种改造其实是半状态,就是一半的状态,它可以把数据存储到对象存储中来,它跟新一代数仓还有差异的,传统的新数仓会基于对象存储做各种优化、调度,而传统数仓是不具备这些的,改造过来只是将数据可以存储到对象存储中来,但依然是传统存算一体架构,需要指定分区、创建索引等,这些都是跟新一代数仓有差异的地方。
存算一体架构有助于实现Serverless架构,新一代数仓是Serverless架构,而传统数仓不是。新一代数仓可以支持Lakehouse(湖仓一体),也可以支持数据湖,可以基于HDFS文件进行处理,而传统数仓不具备Lakehouse功能的。
扩容能力方面,传统数仓是南北向的数据,要保持一致性,它的扩容复杂度是比较高的;而新一代数仓是东西向扩容,是比较容易一些的。
细腻度方面也不一样,传统数仓通常基于KVM进行调度,而新一代数仓基于微服务化进行调度,调度的更精细化一些,速度更快一些。传统数仓不具备多租户概念,而新一代数仓通常都会支持多租户,可根据业务线进行不同的数据处理,可以进行不同业务单元业务结算。传统数仓使用起来要指定分区,手动创建索引,而新一代数仓是无需指定分区,自动化创建索引。
什么是Databend?
Databend具有哪些产品功能特点,能给用户带来哪些价值?
Databend公司团队主要来自于Clickhouse社区,以及国内和海外的大厂,团队人员在数据库和云计算领域具有丰富的经验,贡献过很多开源代码和开源项目,比如Clickhouse、MySQL内核(TokuDB)、RadonDB、NessDB等开源项目。
Databend成立于2021年3月,成立之初获得了高瓴创投和华创资本、九合创投的融资,2022年6月首家通过了中国信通院组织的《可信云-云原生数据仓库通用技术能力》的评审,并获得信通院颁发的《2022年云原生新锐企业》。
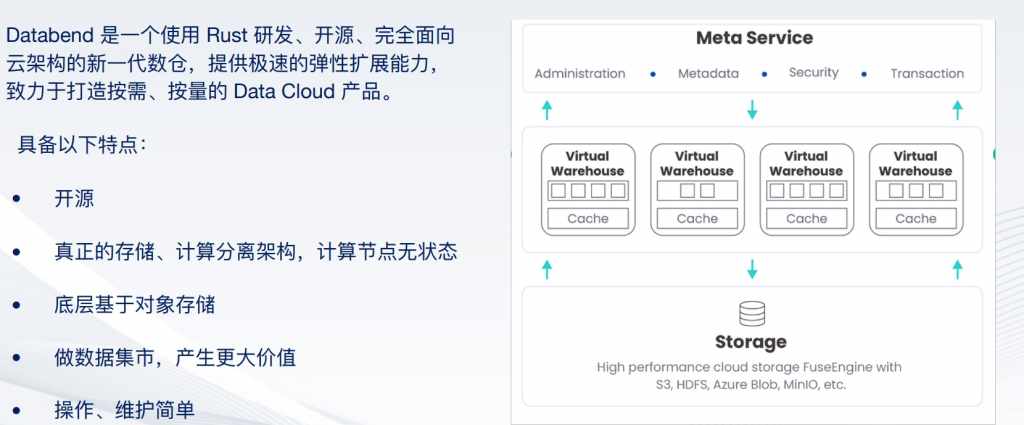
Databend是一个使用Rust研发、开源、完全面向于云架构的新一代数仓,提供了极致的弹性能力,致力于打造按需、按量的Data Cloud产品体验。
具有以下的特点,首先内核Databend是完全开源的。第二,真正存算一体架构,计算节点无状态。第三,底层基于对象存储构建。第四,可以做数据集市,做一个Data Marketing,可以产生更大数据价值。第五,操作运维起来非常简便。
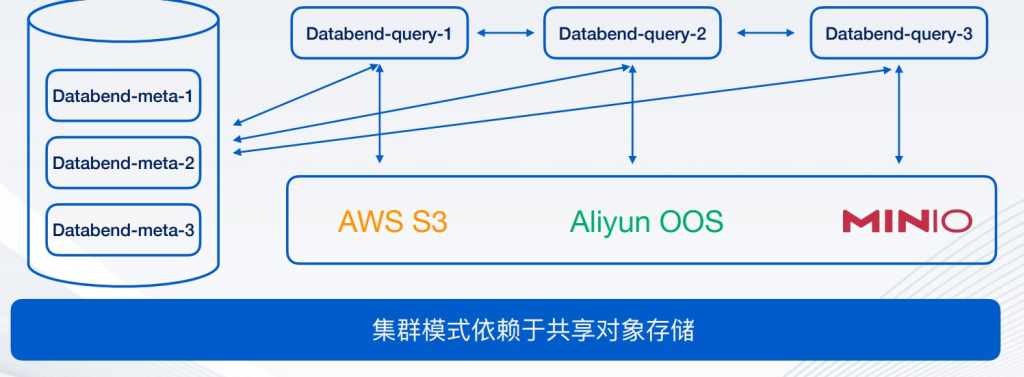
这是Databend的部署图,左侧是Databend的节点,主要存储一些源数据信息,中间是它的计算节点,主要是做数据的查询、分析、计算任务,计算节点可以是随意扩展的,跟你的业务量进行扩展。它构建在对象存储之上,可以是AWS S3、阿里云OOS,甚至私有化部署的MINLO等。
目前Databend已经支持的对象存储包括AWS、Azure、阿里云、腾讯云、青云、金山云,包括社区里贡献了谷歌GCP、谷歌的对象存储和华为对象存储。私有化支持Minlo、SeaveedFS、Ceph等等。
开源必然聊到开源社区,Databend是在成立之初就进行了代码开源,也就是Day1就开源,随着一年多的发展,目前已经自然增长到4700多个Stars,其中一半来自海外,有140多位代码贡献者,四成来自公司外的社区,10位左右海外活跃贡献者,包括Apache的顶级成员,包括SAP北美大数据工程团队负责人。
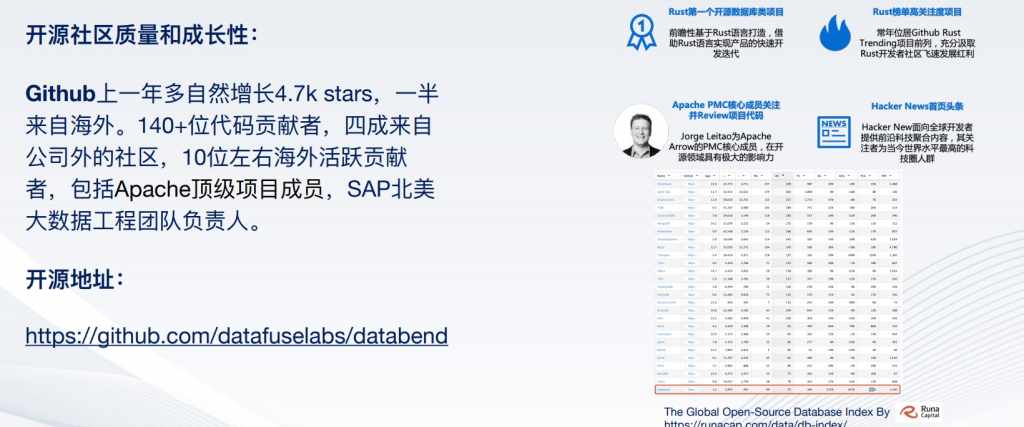
Databend是Rust上开源的第一个数据库类项目,多次上了Rust榜单,同时也上过HackerNew首页,它是世界程序员的一关注内容的科技平台。
右下角是海外著名的投资机构做得世界上所有数据库的排名,Databend大概排在世界所有数据库当中27位左右,也是这些数据库当中最年轻的一个。
接下来了解一下Databend的典型应用场景举例。
Databend可以做数据的归档,以多点为例,前有很多用户商品相关的订单信息,都存储在MySQL数据库当中,随着业务量逐渐增大,每一个月的数据都很大,都需要进行归档的处理,大概它有20多台归档的数据库,每台服务器大概有500TB硬盘,所以说每年光用于数据归档的服务大概就有50万人民币左右,而且是构建在云之上的。之后他们采用了Databend的产品,底层把所有的数据归档到对象存储中,通过Databend。上层开两到三个计算节点,如此进行处理以后,它既可以满足查询的需求,同时也满足归档的需求,为用户带来价值就是节省大概90%的成本,这个成本也可以很好的算出来。
它的服务器从原有的20台降到了2到3台,所以计算单元CPU内存也是非常耗费资金的,所以说通过归档的应用,大概为多点节省了90%以上的成本。
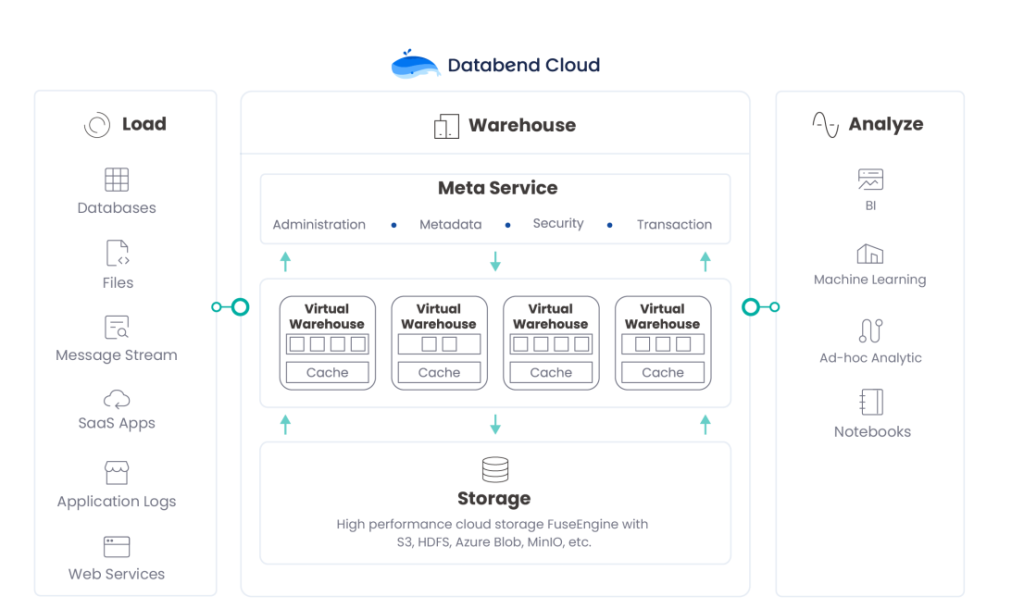
接下来聊一下另一个产品,DatabendCloud,底层核心是构建在开源的Databend内核之上,为用户提供了SaaS化的一站式服务,中间DataWarehouse一核是由Databend驱动的,之上有一个SaaS一体化平台,用户只需要注册用户名密码就可以使用整个数仓平台了,左侧可以把各种数据源,比如说基于MySQL、基于SQLserver数据导入,甚至一些文件进行导入。右侧可以通过Databend loud进行分析,分析完以后提给前端的BI和Machine Learning等等。
对于用户来说,首先不需要维护整个平台了,整个平台都是由Databend维护,用户只需要注册用户名密码,进来以后直接进行连接,就可以达到原有的数仓能力,而且按需付费,需要计算的时候启动一个计算节点,当不需要处理的时候会自动关掉,这个自动关机也是由系统设定的,可以选择一分钟、五分钟、十分钟设定,可以自动关掉,这样对于用户来说达到了一个按需使用、按量计费的目的,节省了用户的成本。
这个图片是我们DatabendCloud申请页面,可以通过申请平台和网址进入到DatabendCloud进行申请,注册申请完就可以开通DatabendCloud,用户就可以直接使用了。
Databend典型用户中,多点是做数仓归档处理的;快手是用到了Hive功能,它原有的数据都是存在Hive中,利用Databend进行数据的分析处理;新加坡比特币交易所主要用Databend进行日志的处理,而且是海量日志PB级数据的处理;茄子快传主要利用Databend具有数仓的分析能力,作为它其中的一个分析平台,替换原有的Presto系统;Voyance为非洲银行提供类似于Snowflake产品形态的公司,它提供的是一个可视化的拓扑、可以展示的DataCloud平台,内核也是基于Databend构建的。
(本文根据Databend 联合创始人王吟演讲速记整理而成,未经过本人审阅。)







