2022年的云科技春晚,亚马逊云科技的re:Invent 2022开始了。
北京时间11月29号上午11点半,我个人最关注的主题内容,继续由亚马逊云科技高级副总裁Peter DeSantis带来。

Peter DeSantis的演讲内容分四个“靓仔”,分别是硬件、网络、科学和软件。其中,科学部分指的是AI/ML方面的创新,软件指的是应用软件运行。
首先,看硬件方面的创新

首先登场的依然是最令人期待的AWS Nitro,回顾历史,Nitro被分成了四个版本来介绍,每一代都会有一些明显的进步和提升,这次发布的就是Nitro V5。

与上代相比,Nitro V5采用的晶体管数量翻倍,内存速度提高了50%,PCIe带宽也实现了翻倍。反映到性能方面,PPS网络性能提高60%,延迟降低30%,此外,能耗比也将提升大约30%。

首发采用Nitro V5的就是这款叫C7gn的EC2实例,它采用的处理器是Graviton3,作为一款网络优化型实例,带宽提升到了200Gbps,各项参数相较于上代的C6gn有不小提升。
第二位重磅登场的其实是新一代的Arm处理器Graviton3E。

Graviton2相较于Graviton1提升很大,Graviton3相较于Graviton2有25%的性能优势,今年,很多人期待的是Graviton4,但这次只有Graviton3E。
Graviton3E是Graviton3的一个变种,主要优化了在浮点运算和向量运算场景中的表现,这种都是高性能计算领域特别强调的能力。
图中展示的性能提升仅限于在高性能计算领域,比如有分子动力学GROMACS、金融期权定价FINANCIAL OPTIONS PRICING等等场景。

为Graviton3E首发护航的就是HPC7g实例,它同时还采用了Nitro V5。对了,这就说明Nitro V5是专门给所有7代主机准备的。
第二,看网络创新方面的创新
网络部分,Peter重点介绍了SRD(Scalable Reliable Datagram)的重要性,并表示,EFA、EBS和ENA都用上了自家的SRD。
EFA是亚马逊云科技的高性能网卡,主要面向HPC和AI集群场景,它依靠Nitro来Offload,绕过内核,以此来提供更高的稳定性,更高的吞吐带宽和更低的延迟。

EFA优势很明显,但由于跟TCP有一些不同,所以,真正用的时候,只有少数对延迟特别敏感的应用才有可能来适配它,为了能让人用上EFA,亚马逊云科技也对接了HPC生态。

SRD在降低EBS写延迟方面效果显著,如上图所示,它能将极少数(P99.999)会出现的35ms延迟降低五倍,并且能将整体的延迟水平降到一个全新的水平。
SRD除了可以帮EBS降低延迟,还能提高吞吐带宽,如上图,采用了SRD的io2,其IOPS和带宽提升了四倍。
Peter还表示,此后新发布的EBS io2都会支持SRD,并且,不会给用户带来额外成本,应用本身无感知,用就行了。

与EFA不同,ENA(Elastic Network Adapter)才是大多数人要用的网络服务,亚马逊云科技把SRD装了进去ENA之后,发布了一个叫ENA Express的新东西。
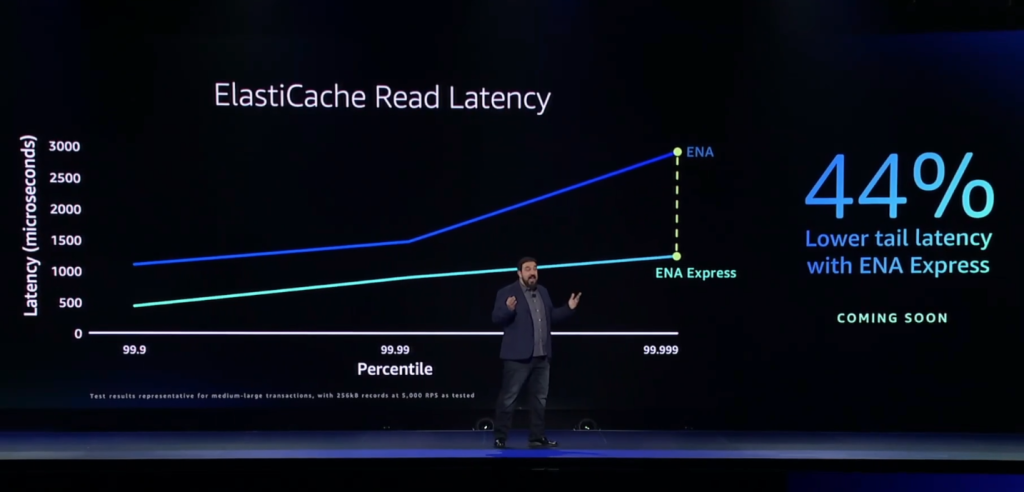
其主要价值也是降低延迟和提升带宽,其中,带宽直接从原来的5GB/s提升到了25GB/s。

对于用户来说,也是只管用就行了,应用方面不需要单独作出调整。
第三部分,机器学习方面的创新。
这部分,Peter重点介绍了如何提高机器学习训练效率的问题。

如上图所示的是机器学习模型精度对训练时间的影响,16位计算精度的训练速度快(也省显存),但损失函数的值收敛不够,也就是说,训练出来的模型会很不准。

32位计算精度可以,但比较费时间,浪费时间就意味着会更费资源,更费钱,为了保证精度的同时能缩短训练时间,人们搞出了混合精度的做法。
为了进一步减少训练时间,还有了叫STOCHASTIC ROUNDING的做法,这个具体是什么,我实在是听不懂,有点超纲了,大概知道这是一个优化训练过程的思路。(懂的大佬能用白话解释一下吗?)
不过,提高训练效率的另外一个思路是横向扩展,用多台服务器来一起做训练。虽然集群运算的效率高,但集群信息交换同步的问题也很大,因为信息交换同步本身就会消耗很多时间。
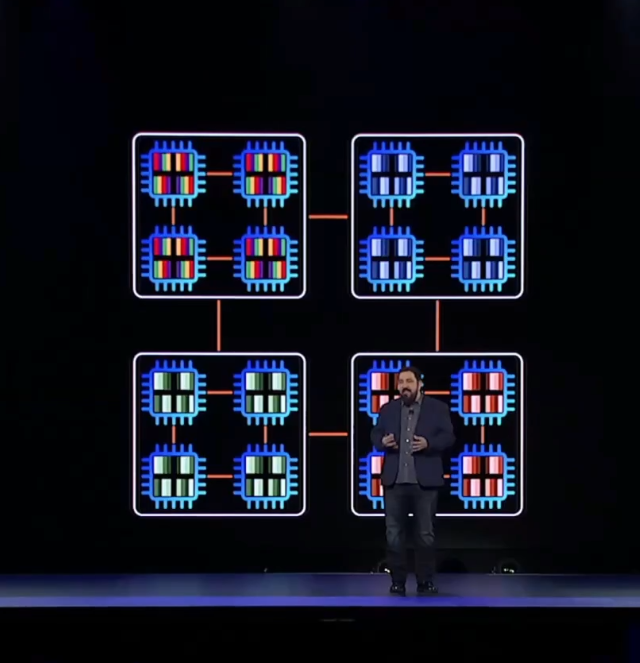
Peter介绍了一个叫Ring of Rings(环中环?)的技术来解决信息交换同步效率差的问题。
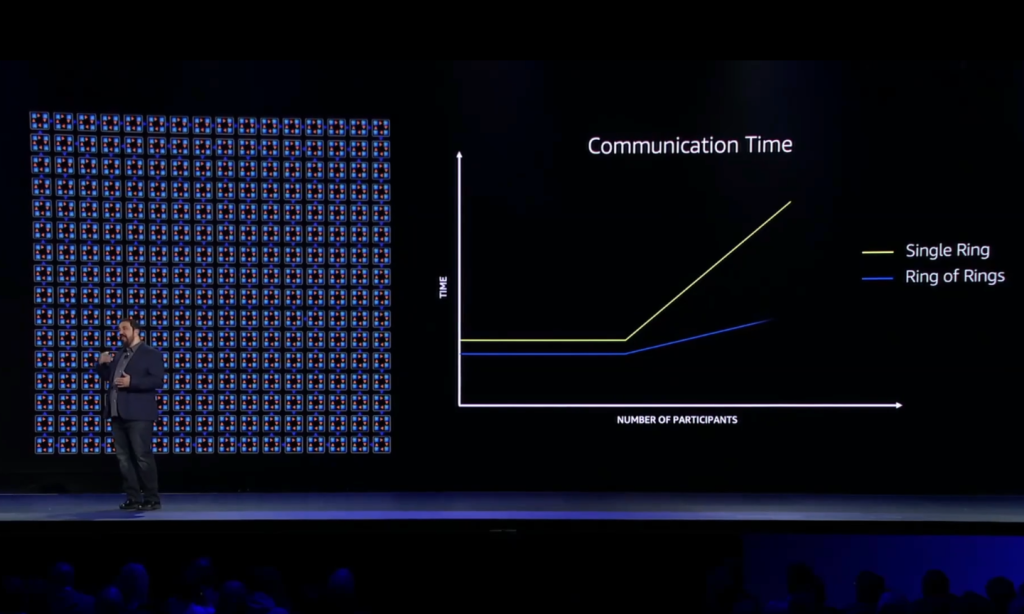
相较于传统的Single Ring的方案,能提高信息交换同步的效率,能把集群规模做的更大。

目前,Ring of Rings技术支持开源的机器学习模型PyTorch,能把PyTorch的信息同步交换速度提高75%。
这么好的技术,怎么才能用上呢?

于是Peter就介绍了新推出的Trn1n实例,它的芯片自然是去年发布的Trainium芯片,网络部分采用的是增强的1600 Gbps的EFA网络,这种实例更适合用分布式集群来训练超大模型。
第四部分,软件运行方面的创新。
这部分主要谈的是亚马逊云科技引以为傲的Serverless服务Lambda,具体说是减少Lambda运行软件应用时的冷启动时间。

此前发布的Firecracker其实也做了一些优化,而今天又再进一步,这就是新发布的AWS Lambda SnapStart,它能把冷启动的时间缩短90%。
至于具体的技术实现的话,大致原理就是用了Snapshot快照技术来加快或者说绕开运行时环境初始化的时间。
关于Peter介绍的主要内容就先记录到这里。
以下是这两天的主要日程,喜欢熬夜的朋友可以蹲一下,我就不熬夜了。

我个人关注的会是CEO和CTO的演讲,渠道方面的不感兴趣,机器学习部分会酌情看一下,主要是预计我能听懂的不多orz。
最后,顺手贴一个注册观看链接: