截至12月6日,世界杯无障碍字幕直播间已累计观看超1800万,多次占据热榜前列……但TA带来的远不止这些。
“过去觉得世界杯距离我太远了,熬夜看球却听不懂、听不清只能紧紧盯着屏幕;但今年无障碍字幕直播间一出,似乎一下子就把我骨子里的体育DNA带动起来了,字幕和画面同时播放,那感觉说身临其境也不为过,最重要的是再也不用担心跟不上、听不懂了……”
“以前观看这种节目其实我挺迷茫的,周围人都在热烈讨论,甚至到精彩处欢呼雀跃,但因为我自己的身体原因,很难融入,脱节带来的孤独感一度让我很沮丧……如今借助无障碍字幕直播间,我又找到了那份可以与朋友快乐同步的体验!”
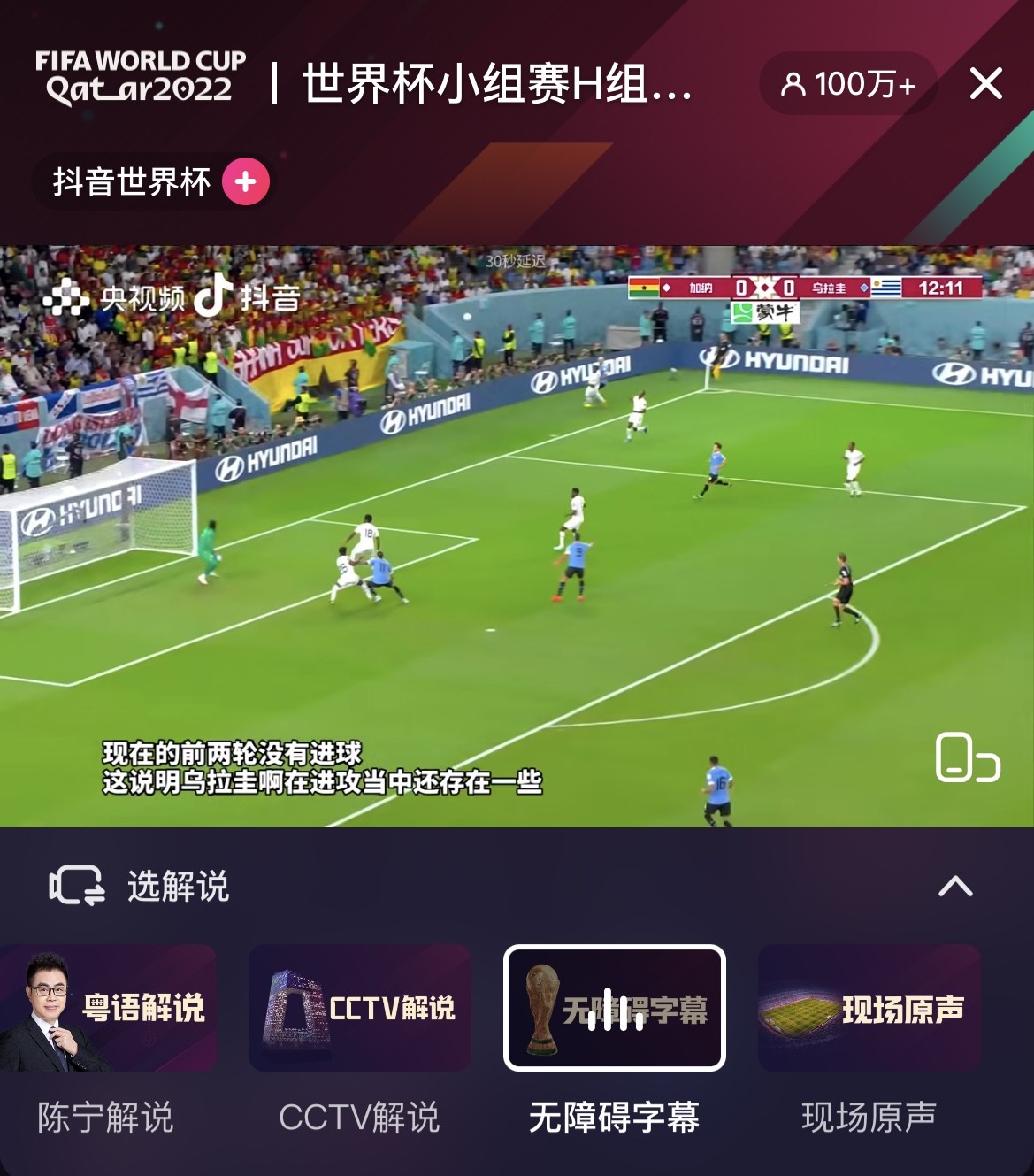
沉浸体验并与快乐同步,是“无障碍字幕直播间”带来的惊喜与感动;但对火山语音团队来说,做好“无障碍字幕直播间”的技术支持与保障,让精彩持续,却是前所未有的挑战。
攻克口语现象、语速语气差异化 火山语音自研端到端流式语音识别系统
“其实语音识别本身就是一种挑战!足球比赛瞬息万变,解说下来,很多口语现象不可避免,尤其是自我修正以及语序颠倒,差异化的语速语气更是司空见惯。如果再碰上一些没有经过专业训练的解说嘉宾参与其中,识别的难度就会进一步加码。为应对这个问题,我们其实思考了很久,最终还是通过自研端到端的流式语音识别系统得到了解决。”火山语音团队表示。
据了解,火山语音团队基于RNN-T框架,通过大量训练数据的积累和持续的算法优化,自研推出的端到端的流式语音识别系统,可以有效规避传统语音识别系统中涉及的大量人工流程,例如依赖专业人员设计各种口音的发声规则等,大幅度提高口音识别的效果。当然其他中间环节的人工假设也减少了很多,比方说对于犹豫、自我修正、语序颠倒等口语现象的表达,会有更好的建模能力。
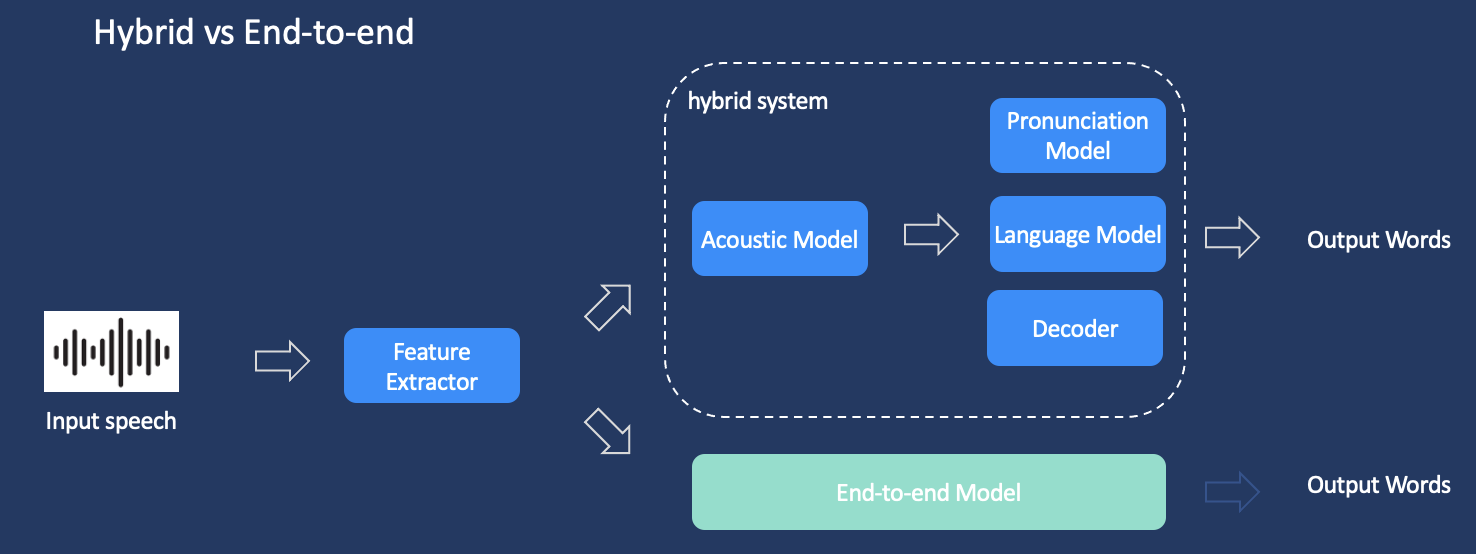
据团队介绍,端到端识别系统的backbone结构(主干网络结构)对识别效果至关重要,所以火山语音采用了业界领先的Conformer结构,可以同时对局部信息和全局信息进行建模,识别效果较传统的CNN、LSTM和DFSMN等结构都有了大幅提升。但随之而来的Conformer的计算开销也会增加不少,因此团队又从模型角度优化了Conformer的训练和推理耗时,主要包括下采样、Attention Mask和模型压缩等方式。“首先Conformer结构的计算复杂度与输入音频的长度相关,特别是Attention计算复杂度与n的平方相关,即音频序列长度越长模型越慢,因此在整个模型的浅层,我们通过增加下采样来降低模型的序列长度;其次通过Attention Mask的方式约束Attention的范围;最后通过自研的模型压缩框架,自动对模型进行裁剪和量化,在降低计算复杂度的同时,效果基本无损。”
除了对识别准确率的要求之外,字幕的上屏速度也对观赛体验起到重要影响。火山语音团队通过在RNN-T训练过程中,对于每个字的发射延迟增加损失函数,叠加Conformer结构强大的上下文建模能力,发射延迟提升了300-400ms。
“无视”背景噪声 优化术语识别 品质字幕如此炼成
在过往的很多大型竞技比赛中,因为“遭遇”大量背景噪音,例如背景音乐以及现场欢呼声等,而带来的识别困扰,被认为是同传字幕不准的“罪魁祸首”。“赛场上经常会出现的观众呐喊声,特别容易被误识别为’嗯、啊、哈’的语气词;背景音乐和观众声则会降低解说员声音的清晰度,对识别模型造成了较大挑战。”火山语音团队提出。
针对上述问题,团队设计了一整套流程应对优化:首先需要自动化地从足球比赛音频中提取出这些噪声片段,通过在模型中显式地建模噪声, 将噪声误出字的比例下降了95%;同时通过数据增强方式提高声学模型在足球场景下的鲁棒性,即在有背景音的情况下也能清晰识别人声,实现更好的流式字幕效果。
在世界杯这样的大型赛事中,提高对相关术语的识别效果,提升同传字幕的专业度往往很关键。通常的做法是收集相关场景的语音识别训练集,但收集的过程耗费时间太长且成本较高;此外面对大量文本语料,如何利用这些纯文本来优化领域识别效果,这对于端到端的语音识别是一个业界难题。
“针对足球术语的优化,我们选择在收集的足球文本语料的基础上训练语言模型,通过语言模型干预方式提高模型在足球领域的适配性。”由于端到端模型本身也隐含语言模型信息,直接与外部语言模型进行融合,往往效果不佳。所以团队根据 RNN-T 的建模方式,通过解藕声学模型和语言模型,显式建模内部语言模型,调整内部语言模型和外部语言模型的权重,可以实现最佳的融合效果。
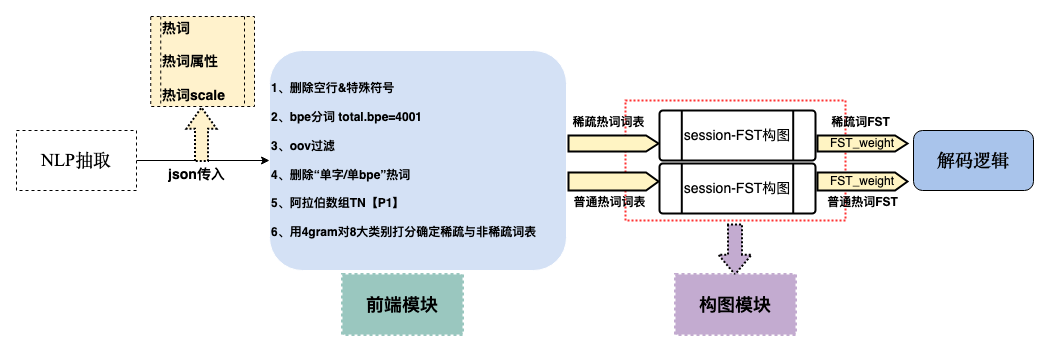
“对于教练与运动员人名识别难的问题,我们从足球相关语料中自动挖掘专有名词、球队和球员名称等术语,通过在解码备选中引入FST(Finite State Transducer)逻辑结构,结合’匹配走图+Backoff权重偿还’的方式对热词进行干预,有效利用该热词专项技术优化后,这些术语的召回从 64% 提升到 76%。”团队总结道。
尽管成功使用了热词干预的方式,但经过大量测试实践,火山语音团队发现,人名又是一种特殊的热词,在 RNN-T 训练平行语料中多为 OOV,采用简单的热词干预方式会存在两个问题:第一,人名中的每个单字RNN-T建模单元都是常见字,但是组合起来作为热词是OOV,这种情况下,纯热词激励权重会导致在不该出现人名的时候召回了人名,即“过召回”,再加上scale过大,导致弧上的边加分过于明显,更易过召回,这是人名重复出字的主要原因;第二,Top10备选路径里面不会出现人名,单纯通过外挂热词FST根本无法有效加分。
针对上述两个问题,团队对人名热词干预做出了两方面优化,分别是扩大FST干预备选以及对热词区分稀疏热词和普通热词,然后对两种热词分别构图,在解码逻辑区别处理。经过两项优化,人名的召回率从76%提升到84%。此外还联合火山语音音频合成团队的同学,采用TTS技术合成术语音频,并加入声学模型训练中,将这些术语的召回率进一步提高到90%,字幕效果更佳。
如今在火山语音识别技术支持下,火山引擎语音识别产品已广泛应用于视频娱乐、办公会议、硬件交互、智能客服等诸多行业,为客户提供了优质且有前景的语音识别解决方案。近日,在火山语音识别能力的技术支持下,火山引擎语音识别产品获得了国家语音及图像识别产品质量检验检测中心(简称“AI国检中心”)颁发的语音识别增强级检验检测证书,充分表明其语音识别技术能力已达到行业领先水平。
从洗脑主题曲“下蛋歌”的魔性旋律与动作被争先效仿,到可爱吉祥物“拉伊卜”被誉为“会飞的饺子皮儿”,再到旅居中东的大熊猫四海竟然能听懂四川话,乡音未改好不欢乐……不得不说今年的卡塔尔世界杯确实贡献了很多“眼前一亮”,如今赛程已进四强争霸,想必无障碍字幕直播间还将带来更多惊喜。