
(图片来源/Meta Research)
继OpenAI、微软及谷歌的文本生成式AI(generative AI)模型,Meta也公布了能产生文本的最新AI模型,并准备将其开源。
Meta CEO Mark Zuckerberg在本周通过Facebook公布了AI大型语言模型LLaMA(Large Language Model Meta AI)。并表示,大型语言模型已显示产生文本、对话、为文章做摘要、以及其它更复杂的任务如解决数学定理或预测蛋白质结构的潜能。Meta将把LLaMA模型开放给AI研究社群,供研究人员进行不同领域研究。
与openAI的聊天机器人ChatGPT或谷歌应对“策略”Bard 不同,LLaMA不是聊天机器人,而是类似于GPT-3.5和LaMDA的LLM(大型语言模型)汇编,这些LLM 支持对话式AI应用。LLaMA 目前是Meta进行的一项非创收尝试,并未积极整合到公司现有的业务组合中。
与OpenAI的GPT-3.5(多达1750亿个参数)、谷歌的LaMDA(多达1370亿个参数)和PaLM(5400亿个参数)以及微软的Megatron-Turing自然语言生成模型(5300亿个参数)等LLM相比 ), Meta对LLaMA 模型的汇编明显更小,但可用作训练更大语言模型。这些模型以大量未标注的资料训练而成,很适合微调后用于多种任务,减少后续大型模型测试、验证及探索新使用情境的计算资源需求。
Meta称,过去数十亿参数的大型自然语言处理(natural language processing,NLP)模型发展出产生创意文本、解决数学定理问题、回答阅读理解问题等能力。
但训练和执行这类大型模型的成本和资源不是所有人都有的,也限制了研究的进展,并造成语言模型的偏见、毒性(toxicity)和产生错误信息。相对的,小型模型是以更多token(小段字词)训练,比较容易为特定使用情境重训练及微调。
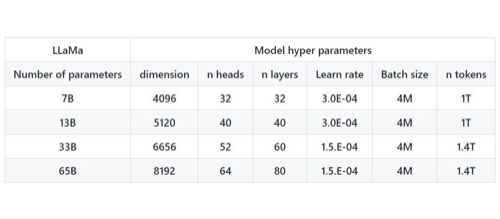
Meta最小的模型LLaMA 7B以一万亿token训练、LLaMA 65B及33B则以1.4万亿训练。此外他们选择从20种使用人口最多的语言的文字字词为训练输入,以拉丁和西里尔(Cyrillic,一种斯拉夫语)字母为主。
按参数来说,Meta的LLaMA有多种规模,分成70亿、130亿、330亿及650亿参数。最大的LLaMA-65b模型相比一些世界级知名LLM,如DeepMind的Chinchilla(700 亿个参数)和谷歌的PaLM也极具竞争力。Meta也提供了LLaMA模型卡(model card)透明度工具,像是标杆测试模型对模型偏差和毒性的评估值,供研究人员了解模型的限制。
最后
当前LLM 应用范围已经远超出聊天机器人,涵盖了从游戏到生产力软件的无限范围用例,并且在为生成式AI的需求带来增长机会,预计其将年复合增长率将超过30%,并有可能成为一个价值50+亿美元规模的市场。






