
要点速览:
- 新闻:近日,顶级机器学习开源库Hugging Face分享性能结果,展示了Habana® Gaudi®2 AI硬件加速器针对1760亿参数大模型卓越的运行推理速度。同时,该结果亦展现了在Gaudi2服务器上运行主流计算机视觉工作负载时的能效优势。
- 重要意义:目前,ChatGPT等生成式AI工具正在为整个行业带来全新的能力,而其模型所需的计算亦使性能、成本和能效成为众多企业关注的焦点。
- 纵观大局:随着生成式AI模型变得越来越大,在数据预处理到训练和推理等一系列复杂的AI负载功能上,能效成为推动生产力的关键因素。开发人员需要一种灵活、开放、高能效和更可持续的解决方案,即“一次构建、随处部署”的方法,使各种形式的AI(包括生成式AI)都能充分发挥其潜力。
- 下一步:AI已经走过很长的一段路,但仍有更多方面有待挖掘。英特尔致力于AI的真正民主化和可持续性,这将使人们能够通过开放的生态系统更广泛地从该技术,以及生成式AI技术中获益。
- 总结:一个开放的生态系统让开发人员能够利用英特尔对流行开源框架、库和工具的优化,来构建和部署AI。英特尔AI智能硬件加速器以及第四代英特尔®至强®可扩展处理器的内置加速器提升了性能和每瓦性能,以满足生成式AI对性能、价格和可持续性的需求。
生成式AI能够模仿人类生成的内容,在改变我们工作和生活方式的诸多方面提供了一个令人兴奋的机会。然而,这种快速演进的技术也揭示出,在数据中心成功利用AI需要极其复杂的计算。
英特尔面向未来进行了大量投资,希望每个人都能利用这项技术,并能轻松进行大规模部署。同时,英特尔正与产业伙伴接洽,以支持一个基于信任、透明和多种选择的开放式AI生态系统。
拥抱具有卓越性能的开源生成式AI
生成式AI例如GPT-3和DALL-E等语言模型已经存在一段时间了,但ChatGPT(一种可以进行类似人类对话的生成式AI聊天机器人)则引发巨大轰动,让人们开始关注传统数据中心架构的瓶颈。ChatGPT还加快了对硬件和软件解决方案的需求,这些解决方案使AI能够充分发挥其潜力。基于开放方法和异构计算的生成式AI使其更容易获得,并更经济地部署最优的解决方案。开放生态系统允许开发人员在优先考虑功耗、价格和性能的同时,随时随地构建和部署AI,从而释放生成式AI的力量。
网络研讨会:英特尔将举办数据中心和人工智能事业部投资者网络研讨会
英特尔正在积极采取措施,并通过优化主流的开源框架、库和工具来实现出色的硬件性能,同时消除复杂性,来确保自身是实现生成式AI的明智选择。近日,顶级机器学习开源库Hugging Face发布的结果显示了英特尔AI硬件加速器卓越的推理运行速度,该结果基于对包含1760亿个参数的BLOOMZ模型(一种基于转换器的多语言大型语言模型(LLM)和包含70亿参数的较小BLOOMZ模型进行推理。其中,对于包含70亿参数的较小BLOOMZ模型,Habana®第一代 Gaudi®具有明显的性价比优势。此外,Hugging Face Optimum Habana库简化了大型LLM的部署,用户仅需对代码进行极小的修改。
英特尔研究院的研究人员还使用Habana Gaudi2在LMentry(一种最近提出的语言模型基准)零次学习设置下评估BLOOMZ。BLOOMZ的精度与GPT-3模型尺寸相似,如下图所示,最大的176B BLOOMZ模型的性能优于类似大小的GPT-3模型。
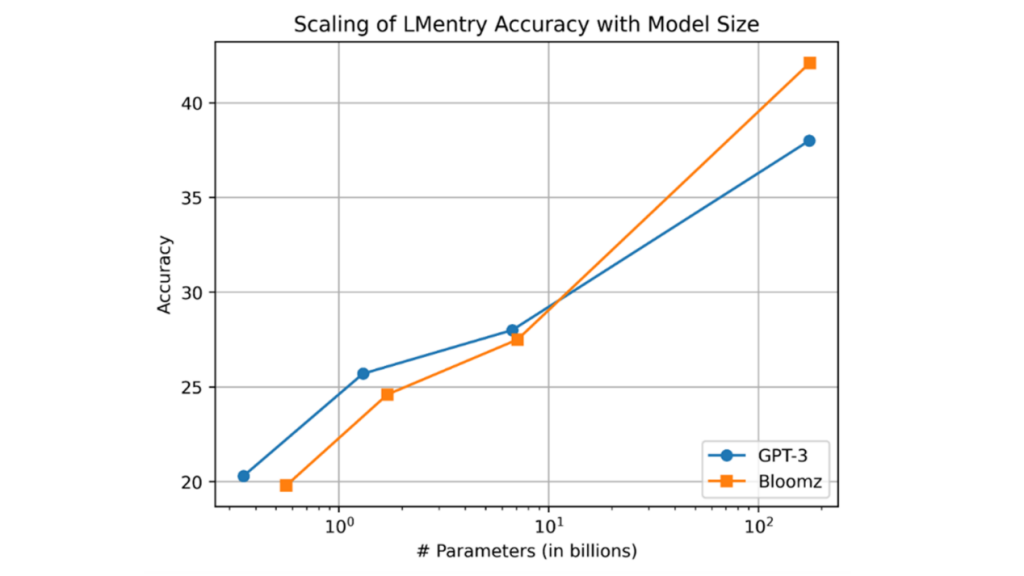
在100K LMentry提示上,BLOOMZ模型(最多1760亿个参数)使用Habana Gaudi加速器对生成的语言输出进行的自动评估。1
此外,Hugging Face亦介绍了Stability AI的Stable Diffusion,这是另一个用于从文本生成图像的最先进生成式AI模型之一,也是流行的 DALL-E图像生成器的开放访问替代方案,Stable Diffusion在内置英特尔®高级矩阵扩展(英特尔®AMX)的第四代英特尔至强可扩展处理器上运行的平均速度提高了3.8倍。
这种加速是在不更改任何代码的情况下实现的。此外,通过使用英特尔Extension for PyTorch with Bfloat16(一种用于机器学习的自定义格式),自动混合精度可以再提速一倍,并将延迟减少到5秒——比初始基线32秒快了近6.5倍。用户可在Hugging Face网站上一个基于英特尔CPU(第四代至强处理器)的实验性Stable Diffusion演示中进行自行尝试。
Stability AI创始人兼首席执行官Emad Mostaque表示:“在Stability AI,我们希望让每个人都能构建自己的AI技术。英特尔已经使Stable Diffusion模型能够高效运行在他们的异构产品上——从第四代Sapphire Rapids CPU一直到像Gaudi这样的加速器,因此是实现AI民主化的一个绝佳合作伙伴。我们期待在下一代语言、视频和代码模型等方面与他们合作。”
OpenVINO进一步加速了Stable Diffusion推理。结合使用第四代至强CPU,它的速度几乎比第三代英特尔®至强®可扩展CPU提高了2.7倍。Optimum Intel是OpenVINO支持的一个工具,用于加速英特尔架构上的端到端管道,它将平均延迟再降低3.5倍,总共降低近10倍。
解决价格、性能和效率问题
此外,为满足减少用电量的关键需求及不断增长的性能需求,还需要提供更加可持续的解决方案。一个开放的生态系统可以消除阻碍进步的障碍,使开发人员能够在每一项工作中都能够使用最好的硬件和软件工具进行创新。
Gaudi2与第一代Gaudi构建在相同的高效架构上,可助力大规模工作负载的性能和效率达到全新高度,并在运行AI工作负载时展现出强大的能效优势。
大规模AI工作负载还需要达到“一次构建、随处部署”方式,这种方式基于灵活、开放的解决方案,能够实现更好的能效。第四代至强处理器是英特尔最具可持续性的数据中心处理器,有着更高的能效和节能效果。凭借英特尔AMX这样的内置加速器,在广泛的AI工作负载和使用案例中,推理和训练性能可提高10倍2 ,同时其每瓦性能相较英特尔前代产品最多可提升14倍3。
附录:
1 2023年3月24日进行测量,使用部署于英特尔开发者云上的Habana Gaudi2深度学习服务器,该服务器采用8个Gaudi2 HL-225H夹层卡和第三代英特尔至强处理器,运行SynapseAI®软件版本1.8.0,batch_size=1
2 参见intel.com/performanceindex:第四代英特尔至强可扩展处理器部分的[A16]及[A17]
3 参见intel.com/processorclaims:第四代英特尔至强可扩展处理器,E1
结果可能不同。







