
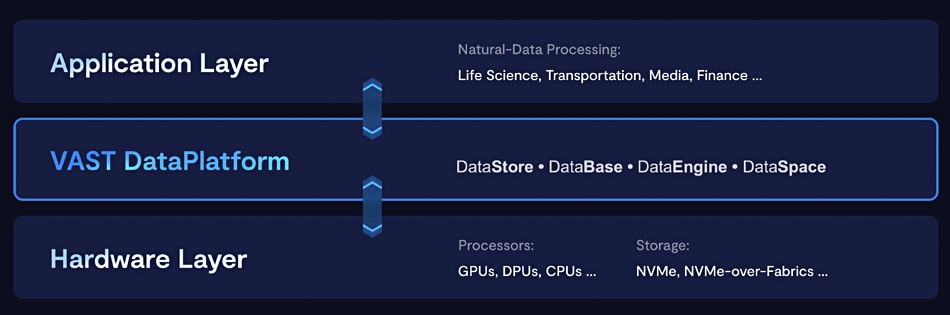
近日,VAST Data宣布推出新的AI数据库软件,作为其即将发布的超大数据平台的一部分,旨在展示数据存储和数据库如何融合成一个单一平台。
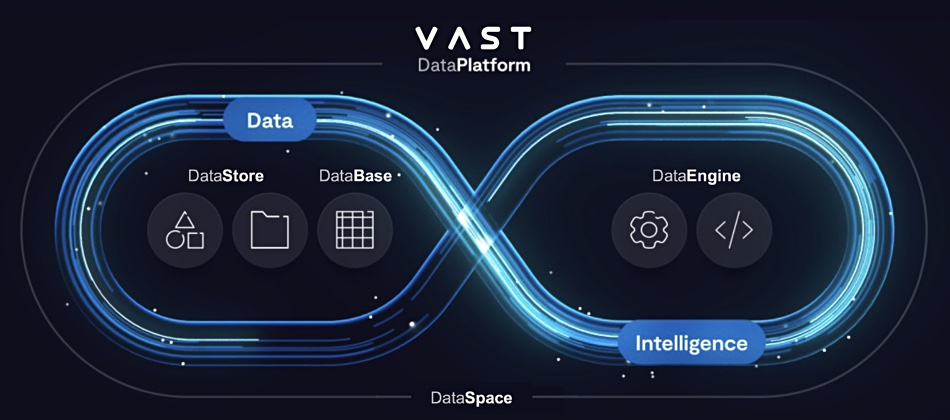
其数据平台套件与前超算公司Thinking Machines 概念对标,基于其 NAS DataStore、VastOS 存储软件和带有数据目录软件的单层 QLC 闪存认证硬件基础。目前,VAST正在添加数据库部分并开发DataEngine部分——最终的计算层。等明年 DataEngine 软件组件推出,这个“存储-数据库混合”平台才完整。
VAST 数据库是一个结合事务和分析的数据库,采用可扩展和 ACID 事务分布式设计,并具有针对闪存优化的 EB 级列式数据结构。VAST 表示,其架构是为了快速数据捕获,并聚合了标准数据库、数据仓库和数据湖的功能。
该公司正在通过在VAST Data Platform中本地添加应用触发器和基于Python的函数来开发VAST DataEngine。其目的是将其打造成全局函数执行引擎。
DataEngine将在VAST DataStore上运行,处理实时的丰富内容、物联网数据和文本。该软件通过关联VAST存储群集的所有元数据,访问所有群集的全球位置,包括存档数据,来做出决策。
VAST声称,全球联盟的机器将在全球范围内处理数据,以获取最大的洞察力和最大的基础设施效率。这将是一个全局命名空间——DataSpace,允许任意位置存储、检索和处理高性能数据。这意味着,做计算的是分布式的VAST DataStore群集,而不是单个数据中心。
VAST OS支持公有云,现已在 AWS、Azure 和谷歌云上可用。
DataEngine软件在DataSpace上运行,创建一个计算资源(包括CPU、GPU和DPU)的网状结构,可以将数据移动到计算(计算比重较大时),或将计算转移到数据(数据比重较大时)。
VAST Data表示,其Universal Storage是NFS的一种解聚共享实现,其底层有一个非常精细的准对象存储。该系统可以处理大量的AI工作负载,构建模型所需的海量数据,以及对新数据进行推断的大量计算,同时提供强大的性能。
人工智能工作负载需要大量数据构建模型,需要大量计算在新数据进入模型时对其进行推理,此外还有高性能要求。 因为这些都给存储系统传递信息带来了巨大的压力。Vast Data 表示,其通用存储(一个分离的非共享式NFS,底层有支持大细粒度的对象存储)能处理此问题。
VAST 表示,DataStore 将通过可查询的语义层嵌入到数据中来理解自然数据。它将持续递归地对数据进行实时计算,并随着每次交互而演化。
Hallak 认为,未来的AI系统在数据整合和学习方面可能会比现在的大型语言模型走得更远。 这将需要一个能吸收“整个自然数据范围——视频、图像、文本、仪器数据形式的非结构化以及结构化数据类型”的平台,这些数据将在世界各地生成,并使用实时推理和持续的递归人工智能模型训练进行处理。这就是函数和应用触发器发挥作用的地方。
VAST的数据库产品已经面市,一些客户已经在使用。DataEngine将在2024年初推出。







