近期,第29届国际知识发现与数据挖掘大会(ACM SIGKDD Conference on Knowledge Discovery and Data Mining,以下简称KDD)在美国加州长滩举办。由火山引擎数智平台,北京大学计算机学院和蒙特利尔学习算法研究所等单位合作的论文 《Rover: An online Spark SQL tuning service via generalized transfer learning 》(以下简称Rover)成功被大会收录。Rover由北京大学的沈彧和火山引擎数智平台的任鑫宇杨担任共同第一作者,北京大学的崔斌教授担任通讯作者。

KDD会议始于1989年,是数据挖掘领域历史最悠久、影响最大的顶级学术年会。KDD广泛的交叉学科性和应用性吸引了来自统计、机器学习、数据库、万维网、生物信息学、多媒体、自然语言处理、人机交互、社会网络计算、高性能计算及大数据挖掘等众多领域的研究者,为来自学术界、企业界和政府部门的相关人员提供了一个学术交流和成果展示的理想场所。
Apache Spark作为主流的分布式计算框架,在工业界得到了广泛的应用,字节跳动内部庞大的例行计算任务每天消费数百万core CPU及数十PB RAM规模的计算资源。每个Spark任务通过200余个相互关联的配置参数启动,但是,由于平台默认配置缺乏弹性,任务环境多样,终端用户经验不足等问题,相当数量的计算资源常因不合理的配置而被浪费。传统上,有经验的大数据工程师可以依据每个任务的运行情况,对其配置进行人工分析和调整。然而,这种人工调优方式在面临在高维参数组合时往往有天花板,并伴有运维迭代成本高昂等问题,使得其难以被规模化。
为了解决此问题,火山引擎的工程师和北京大学的研究者一起设计了一种结合机器学习方法与人类专家知识的基础设施成本优化框架(如图1所示),该框架以贝叶斯优化算法为基础,使用高斯过程作为代理模型学习配置参数集与任务成本/运行时长的关系,并通过可信赖的迁移学习机制,从人类专家知识编码中获得安全性和可解释性(如图1中Expert-assisted Optimization部分所示),并从相似的历史任务中获得额外的收敛加速特性(如图1中Controlled History Transfer部分所示)。
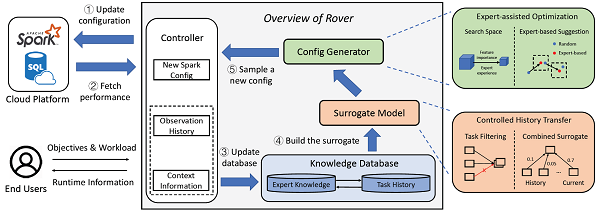
该方案能自动化识别和调整例行计算任务的配置参数集,在不破坏任务服务等级的前提下压缩资源浪费,有效节省运行成本。经验证,Rover在公开任务集及字节跳动内部的实际部署中,对比当前市面领先的解决方案,在极限收益,收敛速度和安全性方面均有进一步提升。

Rover是基于火山引擎DataTester在字节跳动内部应用的自动调参系统优化器内核、增加迁移学习机制演化而来,并通过自动调参平台的配套服务来实施和运行的,目前该项研究已经在字节跳动上万个Spark数据开发任务上得到应用,已帮助公司节约700万元/年的资源成本。未来,这项技术将在字节跳动内部的大数据计算基础设施上大规模部署,预计每年将会节约近十亿元,还将通过火山引擎数智平台为外部企业提供通用优化器服务,可应用于基础设施成本优化,线上算法超参数优化等多种场景。
据了解,火山引擎数智平台(VeDI)是新一代企业数据智能服务平台,旗下的A/B测试产品DataTester经历了字节跳动的10年打磨,目前服务于字节跳动内部500余个业务线,也服务了包括美的、得到、凯叔讲故事等在内的上百家外部企业,为企业业务的用户增长、转化、产品迭代、运营活动等各个环节提供科学的决策依据,将成熟的“数据驱动增长”经验赋能给各行业。
附录论文地址:https://dl.acm.org/doi/10.1145/3580305.3599953