
8月12日在掘力计划系列活动第21场《解析大语言模型的训练和应用》分享中,蚂蚁(计算智能技术部)Ray团队开源负责人,Ray开源社区Committer宋顾杨应邀作了题为《Ray: 大模型时代的AI计算基础设施》的技术分享。

宋顾杨的分享主题:《Ray: 大模型时代的AI计算基础设施》。Ray 这个分布式计算引擎框架,可能很多人都没有听说过 Ray 这个框架,主要是原因作为一个基础设施,Ray 往往不以产品的形态出现,而是作为产品的支撑。
如果来说一些基于 Ray 来支撑的一些产品,大家肯定就耳熟能详了,比如:OpenAI,OpenAI 在今年揭露了一些他们的 GPT 系列产品底层训练所使用到的分布式计算框架,其中 Ray 框架就被他们重点指出了其所发挥的作用。
1. Ray 的演进
Ray 从诞生之初,其实是作为一款强化学习方面的框架被创造出来,随着时代的不断变化,Ray 也被加入了更多的功能,其定位也在慢慢发生改变,先来看一下 Ray 的发展历程:
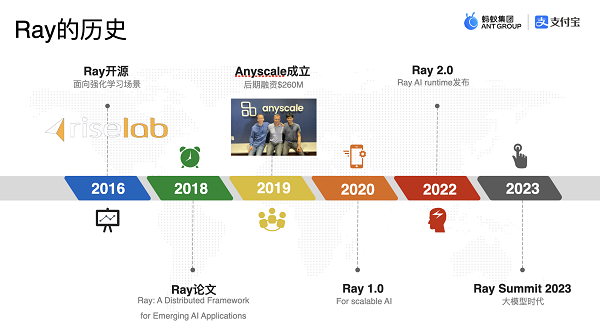
从诞生到现在,Ray 经历了七年的发展,从一开始的强化学习方向到现在的AI方向,Ray 的团队及其开源社区也做了很多的努力,其中宋顾杨所在的蚂蚁集团从 2017 年就开始采用 Ray 框架作为支撑,并为 Ray 内核贡献了超过 26% 的代码,所以 Ray 框架其实在蚂蚁的各个场景内都有涉及,并且蚂蚁集团也为其发展也贡献了不小的力量:

到目前为止,Ray 的定位就是一款面向 AI 的新一代 AI 计算框架,同时也是一款通用分布式计算框架。
Ray 在计算系统中解决的核心问题可以用一张图来概括:

对于任何一个分布式系统研发团队来讲,他们会面临一些很重复的问题,就是上图右边的这些问题,这些问题会耗费整个研发团队很多不必要的经历,Ray 来解决的就是这么一个问题,让研发团队更专注于自身的业务系统上而非通用问题上。
2. Ray 核心能力

通过上面分享人给的例子图,可以看出 Ray 对于整个计算任务有很强的优化,无论是从效率还是功能上,都远远超过传统的云原生计算方式。
Ray 能有这么大的提高,离不开它的一些核心设计点:
1. 不绑定计算模式:把单机编程中的基本概念分布式化。
2. 无状态计算单元:通过简单的注解就可以让一个本地方法放到远程机器上执行。
3. 有状态的计算单元:轻松将一个本地类部署到远程机器上,类serverless。
4. 分布式 Object:多节点之前 Object 传输,自动垃圾回收。
5. 多语言和跨语言:Ray 支持 Java、Python、C++,并且可以做跨语言调用。
6. 资源调度:注解声明式任务需要分配的资源,比如 CPU,是否同一节点。
7. 自动故障恢复:Ray 所有组件都具有自动恢复功能,用户无需关心其底层细节,声明其实现即可。
8. 运行时环境依赖:针对不同的任务可以直接声明不同的运行环境,比如需要一个带 tensorflow 的 python 环境。
9. 运维:完善的运维与监控功能与可视化页面。
虽然实现了这么多强大的功能,Ray 的架构却是非常的简洁高效:

具体想要了解具体 Ray 的架构协作方式可以参考他们的官方文档,在这里就不多做阐述了。
3. Ray 的开源生态与案例

上图就是 Ray 支持的 AI 生态的全景图,几乎涵盖了市面上所有主流框架,也就是说,在 Ray 里面可以很方便的上面这些框架做集成。
通过这些框架集成,Ray 也可以将整个AI pipeline执行过程串联成以下四个大步骤:

Data -> train -> tune -> serve,这四步涵盖了所有分布式训练的主要功能:
1. 数据预处理。
2. 深度学习。
3. 深度调优。
4. 在线推理。
在 Ray 中,你可以通过短短百行代码完成以上所有步骤。
在开源大模型训练方面,也有许多大型项目在使用 Ray:

在企业级应用方面,大家最耳熟能详的应该就是 ChatGPT-4了:

除了 OpenAI 之外,还有许多来自全球各地的公司在深度使用 Ray:

最后,如果大家对 Ray 这个框架感兴趣,可以去其官网了解关于它的更多内容~
关于掘力计划
掘力计划由稀土掘金技术社区发起,致力于打造一个高品质的技术分享和交流的系列品牌。聚集国内外顶尖的技术专家、开发者和实践者,通过线下沙龙、闭门会、公开课等多种形式分享最前沿的技术动态。





