2023年9月7-9日,外滩大会在上海黄浦世博园区召开,作为一场在2023年举办的,以金融科技和前沿科技为主的科技大会,自然少不了对大语言模型的讨论。

在大会期间,蚂蚁集团副总裁徐鹏介绍了蚂蚁集团在AIGC模型上的探索和实践。他认为,AIGC大模型将会发挥越来越大的作用,而蚂蚁集团作为人工智能领域的一个十多年的实践者,希望通过AIGC大模型的发展,为世界带来一些微小而美好的改变。
蚂蚁集团在AI方面有长期积累
蚂蚁集团是一家知名的金融科技公司,其金融属性主要来自旗下的支付宝平台。科技属性方面,源自在科技研发上的高投入。2022年,蚂蚁集团在研发上投入大约204.6亿。并且,蚂蚁集团共有18,678项有授权的专利,其中,超过95%都是发明专利。
蚂蚁集团还是开源技术领域的重要参与者,截止到2022年底,蚂蚁集团贡献了超过300多个项目,包含1,500个开源代码库,总的贡献者数量达到了6,000左右。在开源领域的活跃度,不仅能展示在技术上的优势,也能表明一家公司在技术方面持续投入的决心。
不仅如此,我们看到蚂蚁集团在技术上的投入还在不断加码。2021年4月,蚂蚁集团还成立了蚂蚁技术研究院。徐鹏表示,蚂蚁技术研究院是为了强化蚂蚁在技术探索和创新方面的一个机制,研究院致力做有用、有想象力的科研,开展前沿科技探索。
蚂蚁技术研究院有一个交互智能实验室,实验室主要聚焦计算机视觉和自然语言基础模型方向,会去开发通用人工智能算法架构,包括内容生成、多模态理解、数字人技术等人机交互关键技术,这与如今由ChatGPT掀起的生成式AI技术浪潮息息相关。
从徐鹏的介绍中了解到,由于需要降本增效并且提高使用体验,蚂蚁集团在AI方面一直在持续投入。这是因为,蚂蚁集团在多种场景中都能用到AI,比如,有了AI之后,可以实现营销服务、风控和理财等方面的智能化。
蚂蚁集团多年来深耕AI领域,结合蚂蚁集团自身业务特点建立了多种AI能力,包括自然语言处理、多模态学习、知识图谱、图机器学习以及运筹优化等多个方面。徐鹏对于认为这些能力对于蚂蚁的业务场景有明显价值。
2023年前后开始,随着以ChatGPT为代表的生成式AI技术的兴起,蚂蚁集团对于AI未来的发展也有了更多想法。
蚂蚁集团的AIGC模型战略和基础大语言模型
徐鹏提到了蚂蚁集团在AIGC模型上的整体战略,核心就是要提升AIGC模型研发效能和技术先进性,建设可持续发展的AIGC研发范式和开放共赢的应用生态,建设一流的基础模型,行业模型,实现toC、toB产品落地。
作为战略当中的核心构成,蚂蚁发布了蚂蚁基础大模型,大模型具体又分为语言大模型和多模态的大模型两种能力,它面向场景衍生出了金融模型、安全模型、医疗模型等多种模型,配合蚂蚁技术研究院的交互智能实验室,将模型应用于多个行业场景当中。
战略实施半年后,蚂蚁集团建立了AIGC模型数据体系和AIGC模型工程体系。前者负责数据的采集、加工、处理,后者负责模型训练、部署和调优,将其用在业务场景中。
为了提高AIGC模型研发效能和技术先进性,蚂蚁集团在软硬结合方面做了很多优化,也做了一些国产化适配的工作。
特别值得注意的是,为了提高训练效率,蚂蚁集团开发了智能分布式训练引擎和分布式推理引擎,利用分布式可扩展的特点来快速对模型进行训练和迭代,在下文即将提到的金融大模型训练中,底层算力集群达到了惊人的万卡规模。

除了构建准备数据和训练模型的基础平台,蚂蚁集团也开发了基础大语言模型,该模型采用了Transformer技术,使用了英伟达的显卡加速器,采用了蚂蚁自研的模型架构,支持刚才提到的并行式的训练和推理引擎。
蚂蚁集团的基础大语言模型经过微调后,可以初步适应某个应用场景。随后,可以利用强化学习让其进一步提升在场景上的能力。
在推理时,它还可以支持工具学习的能力,通过自然语言来调用API,这样的能力使得模型不仅限于文本生成或理解,还能与其他软件或服务进行交互,从而执行更复杂的任务。
为了减少资源浪费并加速推理性能,蚂蚁集团的基础大语言模型也支持量化,将模型使用的浮点数转为精度更低的INT8和INT4整数,也支持减枝和蒸馏等手段来减小模型的规模。
此外,蚂蚁还构建了AIGC模型安全防护体系和评价体系,在保障模型安全运行的同时,能不断的优化迭代模型本身。
从徐鹏的介绍中了解到,除了开发多模态模型以外,蚂蚁技术研究还做了很多前沿性探索。比如,蚂蚁开源的CoDeF突破了视频生成方面的一个技术瓶颈,CoDeF可用于完成视频风格迁移任务,不仅细节多,产生的视频整体效果更好,而且,所需的算力资源还更少。
蚂蚁集团正在考虑将AIGC模型应用到toB的产业当中,比如帮助用户处理文档,做视频内容的分析和编辑,对遥感影像进行地块分割、农作物识别等任务。在面向个人用户的toC场景上,蚂蚁也在探索让用户以有趣的方式进行交互。
落地:发布基于基础大模型的金融大模型
在外滩大会举办期间,蚂蚁集团还正式发布了基于蚂蚁自研基础大模型的金融大模型,它针对金融产业深度定制,该大模型在金融专属任务中表现突出,在“研判观点提取”“金融意图理解”“等领域达到行业专家水平。目前,蚂蚁金融大模型已在蚂蚁集团的财富、保险平台上全面测试。
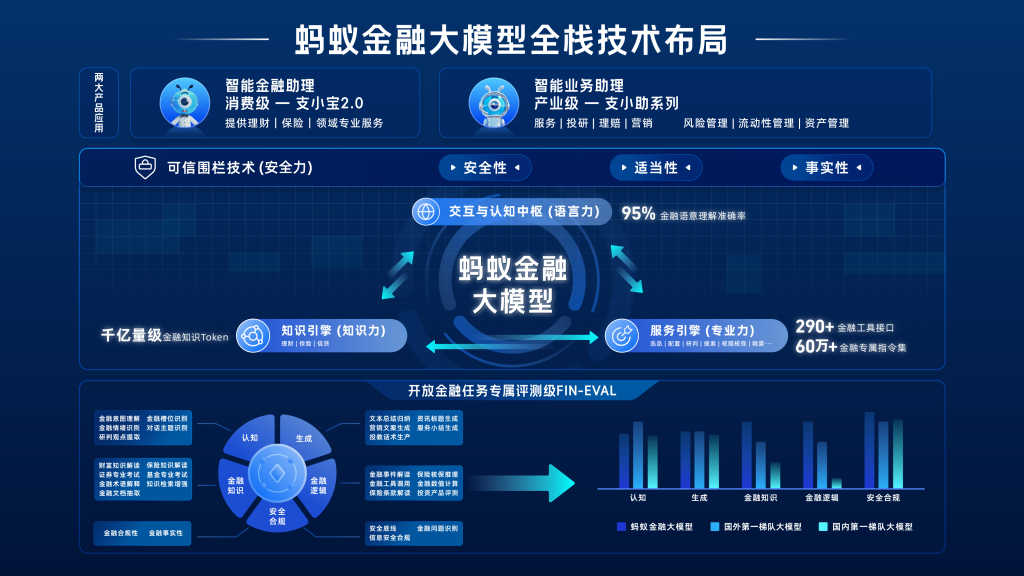
此外,同时发布的还有基于金融大模型能力的“支小宝2.0”和“支小助”。其中,“支小宝2.0”已内测近半年,将在完成相关备案工作后上线。“支小助”正在与蚂蚁平台合作机构内测共建,是为理财顾问、保险代理、投研、金融营销、保险理赔等金融专家准备的AI助手。
据介绍,蚂蚁金融大模型在万亿量级Token的通用语料基础上,注入千亿量级Token金融知识,并从300+真实产业场景中提取了共60万+高质量指令数据,形成了金融专属任务性能优化的优势数据资产。
落地:发布基于基础大模型的代码生成模型CodeFuse
同样是在外滩大会期间,蚂蚁集团首次开源了基于蚂蚁基础大模型研发的代码大模型CodeFuse。它可以根据开发者的输入提供智能建议和实时支持,帮助开发者自动生成代码、自动增加注释,自动生成测试用例,修复和优化代码等,以提升研发效率。
在近期代码补全的HumanEval评测中,CodeFuse得分74.4%,超过GPT-4 的成绩,也超过了WizardCoder-34B 73.2%的得分,在开源模型中位于国际前列。本次开源内容包括代码框架、模型等,现已上架相关平台,模型可在HuggingFace直接下载。
基于CodeFuse的应用场景有开发助手、IDE插件、数据分析器等,覆盖了目前研发工作的主要需求,在蚂蚁集团内部研发流程中陆续得到验证。CodeFuse面向多个层次的开发者。无论是初学者还是有经验的开发者,CodeFuse都能够提高编程效率和准确性。
面向未来
随着基于基础大语言模型的金融大模型和CodeFuse的发布,标志着蚂蚁在AIGC方面迈出了重要一步。蚂蚁集团表示,未来将持续探索和精进大模型的五大能力方向:
一是,建设高质量的数据标注团队,沉淀高质量数据体系;二是,攻坚基础大模型算法,以及高效绿色工程能力,提升模型逻辑推理等能力;三是,从通用语言大模型到通用多模态大模型,从一般通识走向全面专业;四是,建设高效的大模型评测标准和评测体系,加快大模型迭代速度;五是,建设大模型安全能力,保障大模型健康可持续发展。
徐鹏表示,蚂蚁集团也在积极参与一些行业标准的建设,通过一些开放的评测,通过建立评测数据集,让整个行业都可以享受大模型发展的红利。
具体在产业落地方面,蚂蚁将结合自身能力优势和自身业务当中涉及到的多种场景,探索大模型技技术在金融、民生、科技服务等领域的落地应用。