
版权声明:本文为上海市计算机学会存储专委陈雪菲原创文章 DOIT授权转载
生成式AI的热潮在短时间内席卷全球,以一种势不可挡的趋势迅速出圈,在某一时间段,似乎出现了“除了IT行业,人人都是AI专家”的盛况。这一轮如火如荼的全民AI热潮迸发至今,业已过半载,待最初的烟花绚烂散去,现如今又情形何如?
1.独角兽OpenAI倒闭倒计时?

2023年8月,印度媒体Analytics India Magazine刊载了一份报道,宣称OpenAI有可能在2024年底破产,理由有三:用户量见顶后快速流失,日均70万美元的高昂运营成本和开源对手如Llama2的强大压力。(110亿的微软投资应该能够粉碎这一流言,以2.5亿的年运营成本算,还能支撑40年,但前提是微软投资的确已到账且没有业绩考核等撤出条件)。同时,“ChatGPT变笨”的说法也在网上有所流传,一些用户说AI给出的反馈并不像一开始那么惊艳,有时答案里埋藏了一些谬误,有时甚至会严重到行业用户认为“不可用”。另外,相比GPT-3.5,有观点认为GPT-4并没有带来准确率上面质的提升,按照监管评估机构News Guard专家的说法,反而有所下降,尤其是识别虚假信息能力变低。最后,无论是GPT-3.5还是GPT-4,隐私保护的技术也一直没有明显进展,而这也是大规模应用不可回避的重要问题。
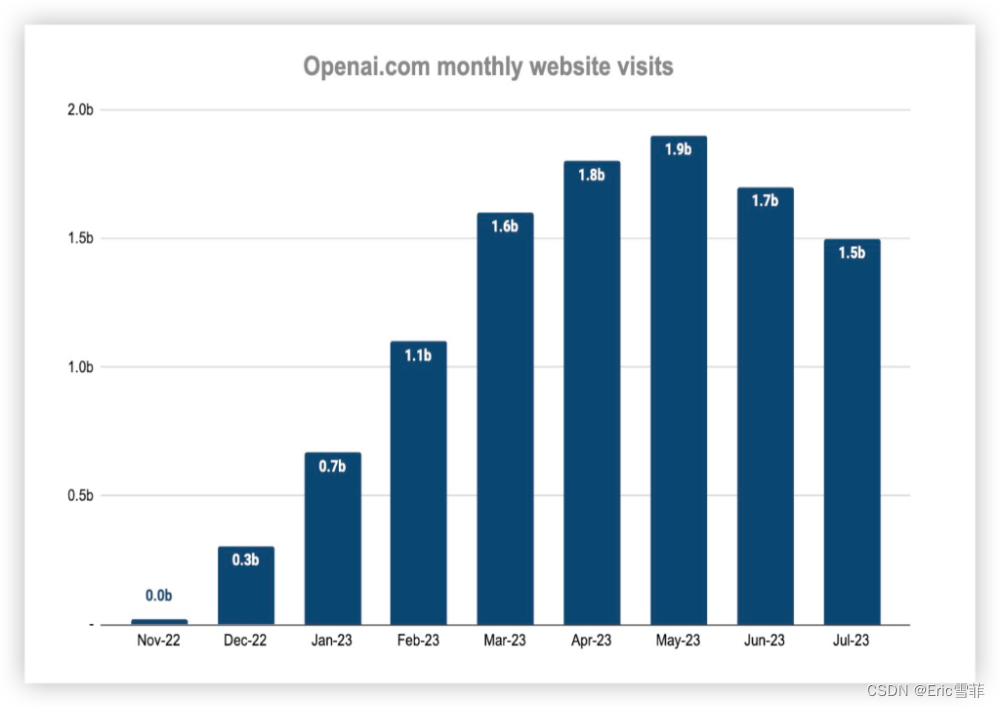
图1:OpenAI每月用户访问量
2. 大模型到天花板了吗?
一部分业界专家认为到GPT-4为止,当前的大模型也许已经成长到头了。技术上而言,有两个问题已经不可回避:首先,语料用尽是一个重要原因,“人类历史上创造出的优秀资源就这些了”虽然现在各种UGC,MGC网络数据总量仍在时刻增加,但是大多都没有带来新的信息量,反而大量无用甚至是误导的谬误信息充斥其中,真知灼见难觅。无论OpenAI也好,Google或是Meta也好,用于训练大模型的数据语料没有量或者质上的根本差别。其次是模型本身的技术限制,一味单纯追求规模提升似乎效用在递减,Meta首席人工智能科学家Yann LeCun(杨乐春)提出:“ChatGPT背后的生成式人工智能技术已进入了死胡同,有太多局限性无法突破”。即使GPT-5出现,也不会带来颠覆性的进化。这位来自法国的图灵奖得主是CNN之父和深度学习三巨头之一,同时也可能是地球上最懂AI的人之一。但也有不乏继续坚持在规模上做大的参与者,例如Google计划在秋季发布的下一代大模型Gemini,据说参数量还会翻倍。
3.竞争格局如何激烈?
通用大模型的头部竞争是非常激烈的,先是Google以LaMDA、PaLM 、PaLM 2发起挑战,然后是Meta的Llama 2,OpenAI的强劲竞争对手一直都在,并且在各方面性能上没有出现明显差距。虽然公司名字里有Open,但是迫于各种压力,OpenAI选择闭源并收费的方式提供服务,而Meta很快用开源和可定制两大利器进行了有效的进攻,这迫使OpenAI不得不在8月宣布 GPT-3.5支持定制,有测试表明,经过微调的GPT-3.5 Turbo版本在某些任务中甚至可以超越GPT-4。
23年5月,Google内部文件泄露,“我们没有护城河,OpenAI也没有”,而两月后,23年7月的一份分析材料指出,GPT-4在技术上是可复制的,未来中美两国的互联网大厂和AI头部企业,都会有能力构建出和GPT-4一样,甚至是超过GPT-4的模型。OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了三个月(之后又微调了6个月),利用率在32%到36%之间。
OpenAI用于训练的云基础设施成本约1美元/每A100小时,以此计算,仅训练成本大约是6300万美元。这对于小公司是一个不低的门槛,还不考虑是否能够搭建如此巨大规模的硬件设施,包括持续紧缺的GPU卡和数据中心资源。
然而,IT行业的摩尔定律并未完全失效,时间流逝仍然会带来更高的性能和更低的成本,在2023年下半年,以性能更好的H100作为主力的云基础设施已经有更高性价比,以2美元/每H100小时计算,同样规模的预训练可以在约8,192个H100上进行,只需要55天完成,如此一来,费用降为2150万美元,约为先行者OpenAI的1/3。
到23年底,估计至少有9家公司将拥有同等规模或以上的集群(如Meta到12月底将拥有100,000个以上的H100),竞争对手已经在虎视眈眈。如果非要寻找OpenAI的护城河,或许有三点可以考虑,真实用户的使用反馈,业内最顶尖的工程人才,以及目前业界公认的领先地位。
个人分析而言,我认为通用大模型的竞争态势将非常类似于多年前的搜索引擎,虽说不一定出现严格的赢者通吃局面,但也相距不远。市场最后剩下的通用大模型玩家多半只剩几家巨头:包括一个能给出最准确答案,能力最强的领先者和不超过3家的追赶者,后者对用户的更大意义可能只是多个备选而已。当然,行业大模型或者垂直大模型又是另外一回事,这里暂且不做讨论。
4. AI发展轨迹:十年磨三剑
从2012年的计算机图形识别技术的突破算起,中间2016年的Alpha GO再到2022年底ChatGPT的横空出世,AI技术从小数据小模型走到了大数据大模型大算力的时代。

历经10年,我们从只能完成特定任务的弱人工智能出发,越来越接近强人工智能,从深度卷积神经网络技术到深度强化学习到大模型,从感知到决策到生成与行动,业界如今开始以一个新术语“智能体”来代指AI。现在的大模型已经非常接近强人工智能(又叫通用人工智能、AGI),它具备多种能力甚至接近理论上的全能力。假设能够继续顺利往下发展,下一阶段的超人工智能理论上能够全面超越人类现有水平,到达从未触及到边界,未知会带来恐惧,到时候人类如何与之相处?2019年我参加世界人工智能大会时,在现场听到另一个图灵奖获得者,CMU的Raj Reddy教授提出一个模式:GAT(全面智慧助理)。他的这个设想是让超人工智能去辅助前沿科学的突破,再转而教授我们新的知识,从而辅助人类文明进步,希望最终的发展能如他所愿。
5. 大模型框架和基本流程
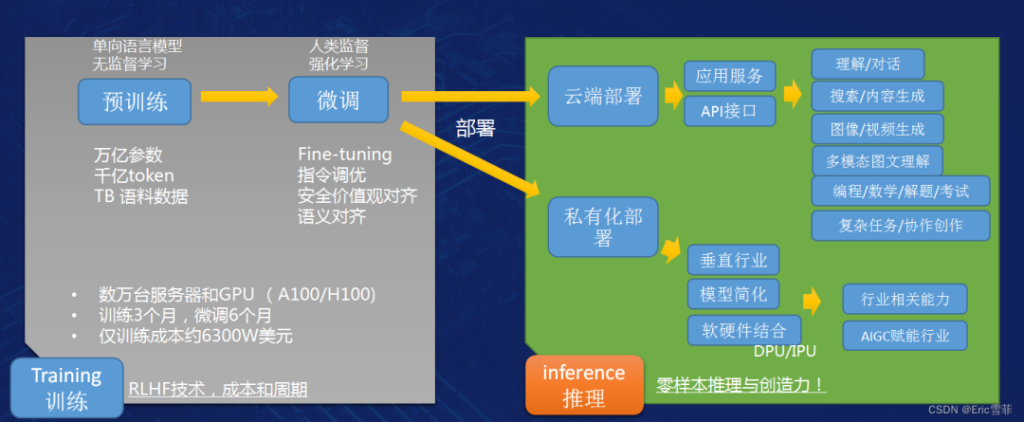
大模型需要三个要素,软件算法,巨大的GPU集群和用于训练的数据集,之后是大量的工程工作。如果不考虑前期预备阶段的数据归集和数据清洗,打造一个大模型可以粗略地分为训练和推理(工作)两步:通过有效训练形成综合能力,然后在推理阶段提供出来给用户(包括以聊天应用ChatGPT答复的各种问题和提供的各种帮助)。
以能力的复杂度从易到难排序,大模型具备的能力包括理解,对话,搜索,文本内容生成,图像和视频的生成,多模态图文理解,以及学科考试,编程、复杂任务完成以及协助人类复杂创作等各类型。
第一步训练阶段通常又分为预训练和其后的微调阶段,以OpenAI为观察对象,到GPT-4为止,预训练阶段的所使用的数据都是以大量的文本信息为主,通过无监督学习的方式,输入高达1.8万亿参数的模型中进行训练,如前所述,OpenAI使用了25000张A100卡和3个月的时间完成训练,随后后还有长达的6个月微调工作需要完成。
微调阶段大多使用Fine-tuning技术,其中一个重要环节是RLHF(Reinforcement Learning with Human Feedback),即基于人类反馈的强化学习。RLHF解决了生成模型的一个核心问题,如何让人工智能模型的产出和人类的常识、认知、需求、价值观保持一致。简单地说就是对AI三观进行纠偏,杜绝离经叛道,解决所谓的“大模型幻象”问题。
以上训练阶段完成基本算大功告成80%,接下来就要考虑不同的部署方式以及后期的用户反馈持续优化。OpenAI采用的是云端部署,同时提供ChatGPT的用户直接访问应用接口和可集成API接口,其他第三方例如微软可以通过API集成,在自己的软件或云服务中调用大模型,提供给用户不同的能力和应用如Copilot(最近“知名网红数学家”陶哲轩就安利了一下VSCode插件+Copilot如何好用,之前GPT4帮助自己编程也很棒),而国内百度等布局云端通用大模型的厂商也提供API集成模式。除此之外,国内一些厂商更愿意选择面向垂直行业的私有化部署,通常在几十个节点规模以下,面向特定行业提供仅一两类AI辅助能力,这样模型可以简化,不必大而全。因此你会看见国内不少厂商宣称自己发布了很多个大模型,通常实际就是面向垂直行业的“小模型”,严格地讲还是属于弱人工智能范畴。这类应用不仅体量规模小,还可以实现软硬件结合,部署到边缘端,是更容易落地的AI 赋能行业模式,也是当前大量创业公司瞄准的细分赛道。
6. 生成式AI技术前沿动向
了解完基本框架,我们来看看业界最新的动向。
本轮的AI技术发展脉络基本如下:CNN –> RNN->LSTM->RNN/LSTM +Attention -> Transformer(例如在典型AI应用机器翻译领域,几个比较重要的阶段分别是: Simple RNN -> Contextualize RNN -> Contextualized RNN with attention -> Transformer)。
目前业界的主流大模型基本都是在Transformer框架下发展而来。它是2017年提出的技术,而当前大火的GPT是Generative Pre-traning Transformer的简称,从名字就能看出来在技术上已经又演进了一步。除了增加预训练技术, 我观察到的另一个突出的特点就是“横向扩展”。
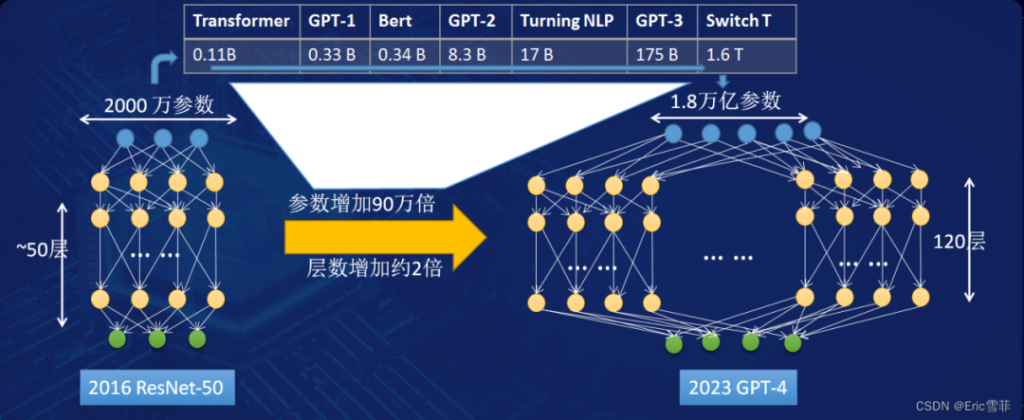
经过这些年的发展,模型规模急剧膨胀,深度计算已经渐渐快要成为“宽度计算”,回看2016年业界流行的ResNet-50模型,仅采用了约50层的神经网络结构并辅以2000万参数进行训练和推理;而2023年的业界公认最好大模型 GPT-4使用了1.8万亿参数,而神经网络层数仅仅增加到120层。从层数(深度)上看仅仅是翻倍多一点点,但参数量增加了90万倍,这直接导致了集群节点数量(宽度)的急剧膨胀。GPT-4已经使用2万多张GPU卡才能完成进行训练所需计算,所以业界戏称深度计算已经膨胀成了宽度计算。(注:B是10亿,因此Transformer使用了1.1亿参数,GPT-3使用了1750亿参数,国内两个流行模型65B和130B分别是650亿和1300亿参数)
7. 2023年大模型的五个关注问题
第一是模型的规模。
当你考虑大模型的规模,会看到不同的衡量方法:参数量,token数,数据量和训练集群大小,这几个概念互有关联。首先参数量的增加是出于软件算法的演进,这导致了架构的横向扩展,训练集群的节点数量自然大幅上涨。而架构拓展后,就可以用更多的数据集投入训练;token是对训练数据的元切分,当训练数据量越多,token数也会增加,但不一定是线性关系。所以,这四个元素都能从不同的维度对模型规模做一定的衡量和反映。
时间来到2023年下半年,如前面所提及的那样,业界对于一味增加规模所能够带来的效果已经有两种看法:一部分专家和企业认为边际效用的递减很明显,例如Meta认为自己的LLaMA130亿参数版本表现已经优于GPT-3(1750 亿参数),而业界一些小一点的模型,基于数百亿甚至是数十亿参数的模型表现良好,不必非要膨胀到千亿和万亿那个规模。在7月针对GPT-4的分析文档中也指出,相比GPT-3膨胀了10倍以上参数规模之后,出现了大集群利用率显著下降的问题,业界用“bubble”这个术语来描述部分GPU没能全力工作摸鱼的现象,由于部分计算能力“空转”现象的出现,推理成本上升了约3倍,这同时给以马斯克为代表的AI高能耗批评者提供了新的素材。
第二个关注点是如何实现更好的多维并行。
生成式AI是一个典型的并行计算应用,并行度越高越有利。所以要从多个维度增加并行度,目前多维并行包括三种并行技术:数据并行,张量并行和流水线并行。
数据并行相对简单,数据一份太大,因此分割成多份,放到多个计算节点,让多个GPU同时进行并行计算。
而张量并行可以简单理解为一个大模型单卡放不下,所以将其切开放,多个GPU一起算加快速度。张量并行的弊端是中间的通信开销太大,目前广泛采用二维、三维张量并行的核心思想是用更多的局部序列化替换全局序列化,用更多局部通信换取全局通信,从而降低通信成本,提高效率。Nvidia的黄仁勋在GTC 2021 年演讲里也提到把所有张量并行都放在服务器内,避免跨服务器的通信开销太大,得不偿失。(注:张量计算是大模型的重要运算特色,张量(Tensor)是多重线性代数中会接触的数学概念,在物理中和工程中都有应用,它可以执行一些数学运算,例如内积,缩并和与矩阵的相乘(矩阵就是二阶张量,向量是一阶张量,而零阶张量就是标量)还可以执行切片抽取矩阵等)。
张量的好处就在于它是多维的,能够在一个张量里包含更多数据,如此计算效率更高。
流水线并行需要一点巧妙权衡,它需要考虑层数和 GPU 数量之间关系,有专家提过一个比喻,GPU就像工程队,任务是盖很多楼房,每栋楼有很多层,流水线层数相当于楼层数。15 个工程队盖 1000栋楼,理论并行度可达到15,让每个GPU都忙起来,杜绝摸鱼。因此提高并行效率的诀窍在于增加batch size,提高流水线层数和 GPU 之间的比值。
在7月的GPT-4分析资料里指出,GPT-4采用了8路张量并行+15路流水线并行,一个原因是受限于GPU卡最大8路NVlink的现状,另一个原因可能是A100的40GB显存数量。
三种并行技术中,张量并行是当前业界关注的一个重点,若能有所提升,会带来更大的帮助。2023年7月,Google宣布开源张量计算库TensorNetwork及其API,宣称对GPU的加速效果百倍于CPU。相信业界已经很多人在试用,实际效果如何我还没看到分析或报告。
第三个关注点是混合专家模型(MoE)。
不同于单个的大模型,包括OpenAI,Google和微软都使用了这种新的架构。MoE的基本思想是用多个相对小一些的模型组合起来,各自成为某一部分的专家,共同向外提供推理服务。每次推理时仅使用一到两个模型,如此能够有效降低推理时的参数量以及资源。例如Google的GlaM模型一共使用了1.2万亿参数,内部是64个小神经网络,推理时仅使用2个,8%的参数,8%能耗。七月的分析材料显示,GPT-4使用了16个专家模型,每个拥有1.1万亿参数。之所以它专家模型数量远小于理论最优值64~128, 是因为OpenAI的专家认为太多的专家模型会阻碍泛化,也很难收敛,对于打造一个通用大模型的目标实现是不利的。
除了通用大模型的领域,一些垂直大模型也在使用同样的思想,只不过使用了另一个术语“大模型路由”,例如低代码应用大模型时,会参照Web编程引入“路由”概念,事先按不同场景和能力打造出众多“小模型”,例如有的模型只做表单table,有的模型做图表,把功能分拆下去。当使用时,会根据用户的需求决定哪些“小模型”被调用,按何种顺序调用,最后完成整个任务。虽然使用的名词不同,但其中的设计思想是非常近似的。
提到推理,“低延迟推理”已经作为一个术语概念被明确提出,它要求输入输出响应时间限制在可接受范围,模型必须以每秒输出一定数量的token,作为使用者,人类需要30 tokens/s方可接受。另外考虑到调用一次就是一次推理,成本也必须受控。推理优化的最新实践是“投机采样(Speculative sampling/decoding)”利用小模型先“打草稿”生成N个token,之后让大模型评判,可以接受的就直接用,不接受再修改。这个方法能够获得成倍的加速效果,并降低推理成本。据说GPT-4和预计今年秋季发布的Google下一代大模型Gemini都使用该方法,Google已经发表了相关论文。
第四是内存管理优化问题。
大模型是非常吃内存的,大模型的演进基础技术是Transformer框架,首先参数,梯度都需要放到内存里进行计算。以训练GPT为例,如果按照 10000 亿参数量计算,即使采用单精度,每个参数占4字节,仅参数就要占 4T内存,同时梯度也要占 4T内存。再加上这一著名框架里的核心机制attention,会在此基数上产生指数级的放大,总和的内存理论需求会到达PB级别。
目前内存优化业界已经有一些方案,基本思路通常有两个方向,一是尽量在软件算法上降低内存开销,二是尽量减少数据的移动,包括CPU和GPU之间,以及CPU和NVme硬件之间。
第五个关注点是视觉多模态。
据材料分析,OpenAI本想在GPT-4就采用从零开始的视觉模型训练,但由于种种原因,最终还是退了一步,先采用文本预训练之后,又用大约2万亿token进⾏了微调,形成了GPT-4的多模态能力。
而下一代模型“GPT-5”,计划从零开始训练视觉模型,用来训练多模态模型的数据包括:「联合数据」(LaTeX/文本)、网页屏幕截图、YouTube视频(采样帧,以及运行Whisper获取字幕),训练数据将出现大量非结构化数据,粗略估算以每token数600字节记,规模将是文本的150倍。
OpenAI期望下一代训练成功的“自主智能体”在具备GPT4的能力之外,还能够阅读网页,转录图像视频中的内容,也能自主生成图像和音频。(这下岂止好莱坞编剧,连编辑剪辑,后期制作也要加入抗议的队伍了)。
除了应用前景外,利用视觉数据进行训练还有可能产生一个根本性的改变。
到目前为止,语言和文本还是训练通用大模型的基础语料,GPT所获得的所有信息仍然受困于“语言的边界”,按照哲学家维特根斯坦的著名论断,“语言的边界就是思想的边界”,对于大模型来说,语言类的信息将其局限在逻辑和文本的世界之中,无法感知客观事实,有可能出现“缸中之脑”的哲学幻觉。相比而言,静态图片数据可以提供空间结构信息,而视频数据本身还包含了时间结构信息,这些信息能够帮助GPT进一步学习更深层的基础规律例如因果率等,打开更大的可能性空间。
当然现在基于文本类语料已经有“模型幻象”的问题,也就是所谓“一本正经胡说八道”的情况无法彻底杜绝,而从目前的研究发现,视觉多模态的幻象问题似乎更加严重,并且参数更大的模型诸如Lalma2比诸如7B这样的小模型更严重。如何更有效地减少幻象,仍是业界的一个待解决问题。







