
2022年9月16日,在北京举办的掘力计划第 24 期《大语言模型应用&实践》活动上,来自 Zilliz 的 Towhee 开源项目负责人陈将带来了题为《拓展大语言模型边界:利用向量检索构建知识库》的技术分享。

陈将来自于 Zilliz,现任 Towhee 开源项目负责人。拥有多年的大数据基础架构和数据安全开发经历,曾先后在谷歌云服务和搜索架构部门担任技术负责人和产品经理,期间带领团队开发了数据索引仓库应用于低延迟、高吞吐的短视频搜索等场景。对处理海量非结构化数据和多媒体内容检索有着丰富的行业经验。陈将拥有密西根大学计算机科学硕士学位。
视频回放:https://juejin.cn/live/jpowermeetup24
一、大语言模型的局限性

大语言模型例如 ChatGPT 在通用能力上表现强劲,但也暴露了一定的局限性:
● 缺乏专业领域知识:对通识知识了解广泛,但无法回答专业领域的问题,如怎样修复特定机械设备。这是由于训练数据没有覆盖这些专业领域。
● 容易产生幻觉:可能给出错误或虚假的回答,但无法轻易判断真伪。在严肃场景下可能产生严重后果。
● 信息过时:训练数据是某一固定时间的快照,无法获取更新后的信息。且无法频繁重新训练。
● 预训练数据不可变:训练结束后很难删除或纠正无效信息。
二、用知识库改进大模型
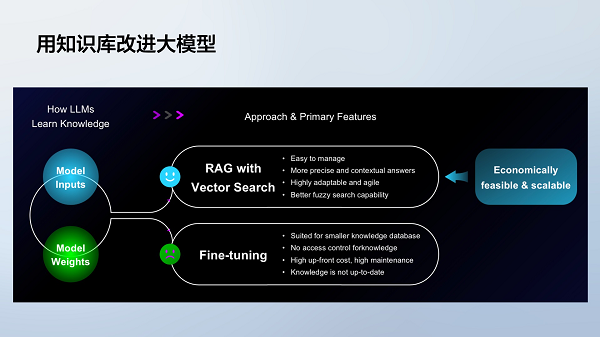
针对上述问题,主要的改进思路有:
● 使用数据库承载专业领域知识,如向量数据库构建知识库。
● 做微调(Fine-tuning),使用少量标注数据增强特定领域能力。
● 做提示工程(Prompt Engineering),添加提示词避免生成虚假信息。
● 使用外部数据库存储最新信息,实时更新大模型的外部记忆。
相比微调,使用知识库的优点是:
● 易于知识管理,可以细化操作知识片段。
● 准确度高,只要检索相关度高就可提升回答质量。
● 各种优化手段灵活,可不断迭代。
● 信息模糊匹配能力好,不需要严格匹配关键词。
微调的优点是可积累信息,逐步提升模型在某领域的能力,但也面临其他领域能力下降、管理难度大、训练成本高等问题。
三、CVP技术栈详解
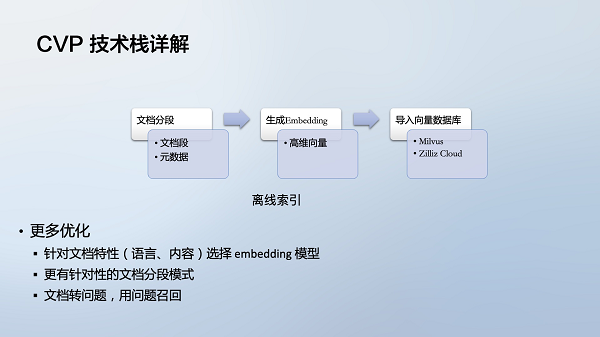
CVP表示大语言模型(C)、向量数据库(V)和提示词工程(P)的结合。主要流程是:
离线索引:
● 对文档分段;
● 用 embedding 模型生成向量;
● 将向量导入向量数据库。
可以做各种优化,如选择不同的 embedding 模型等。
在线问答:
● 从数据库检索相关知识片段;
● 组装提示词,将知识片段插入提示词中;
● 将提示词发送给大语言模型,生成回答。
也可以做各种优化,如多轮检索、排序等。
四、动手搭建知识库增强问答
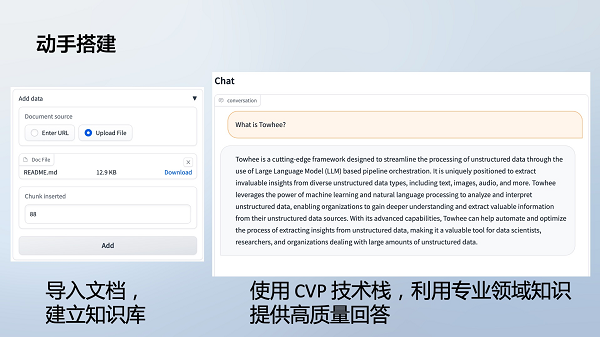
使用开源工具 Milvus(向量数据库)、 Akcio(实现CVP逻辑)可以快速搭建一个示例:
● 导入文档,切分生成文档段;
● 用户提问时,从 Milvus 检索相关文档段;
● Akcio 组装提示词,插入检索结果,询问大语言模型;
● 大模型组织知识片段内容,生成高质量回答。
相比直接询问大模型,引入外部知识库可以显著提升回答的相关性。这展示了向量检索构建知识库在拓展大语言模型认知边界方面的潜力。
五、展望

向量检索构建知识库还面临如何高效管理知识变更等工程难题,需要持续的研究和开源社区努力。与智能体结合也值得期待,或许会带来管理记忆的全新模式。
结语
通过陈将老师的分享,我们可以看到,在大语言模型风靡的今天,识别和改进其缺陷尤为关键。这场分享系统地剖析了大语言模型的局限性,并分析了现有的解决方案。文档检索增强 (Retrieval Augmented Generation) 作为一种提升大预言模型能力的手段,被业内普遍看好。本次分享中的 CVP 技术栈提供了一种简单可行的思路,也为我们进一步深入研究提供了参考。当然,要落地应用仍需要处理好知识表示、持续迭代等问题。
相信在不断升级的工具和算法支持下,知识库必将发挥越来越大的作用,甚至有望真正解决大语言模型“无知”的问题。让我们拭目以待吧!
掘力计划
掘力计划由稀土掘金技术社区发起,致力于打造一个高品质的技术分享和交流的系列品牌。聚集国内外顶尖的技术专家、开发者和实践者,通过线下沙龙、闭门会、公开课等多种形式分享最前沿的技术动态。





