
1月11日前后,ChatGPT上线GPT应用商店,可能是因为围观的人太多了,上线之初ChatGPT又趴窝了。
在我看来,此次的所谓GPT应用商店,就是把此前大家做的GPT都放到了一个页面当中,有一套检索和分类系统,来便于分享和查找这些GPT。
上线这几天,我比较感兴趣的就是这个叫Consensus的GPT。

这是一个基于人工智能的研究助理,它检索了Consensus(共识)网站上的2亿篇学术论文,用户可以问它某个主题有哪些论文,并且能给你这些论文的准确链接,找到出处链接。

作为关注数据存储领域的内容编辑,我问了它关于闪存存储有哪些论文。
它提到了这样几篇论文,看起来是分了三大类,其实都是用来提高NAND闪存性能和可靠性的。

我挑选了一个跟AI有关的论文,末尾还提供有论文的链接,它会把我引导到Consensus网站上。
AI让我了解了这篇论文的大致信息,我很快就了解到:
传统机器学习在NAND故障预测方面存在问题,基于预训练的模型在某些NAND下表现可能很好,但换了NAND颗粒之后就不行了,为了重新适应新的NAND需要重新训练模型,这很麻烦。
而新的叫LightWarner的无模型强化学习算法,算是一个故障预测器,可以动态学习闪存错误特性,它可以更快地适应不同闪存芯片,不同寿命周期的错误特性变化,从而降低模型迁移的成本。
论文中还提到,在对六种类型的3D闪存芯片进行评估时,LightWarner的表现比传统监督式机器学习方法故障预测准确率高了约10%。
这种高预测准确率意味着LightWarner能够有效识别即将发生的故障,从而有助于提前采取措施,避免数据丢失或系统故障。
还能了解到,LightWarner的一个主要优势是其对不同闪存芯片类型的适应性,这使其在不断变化和发展的存储技术领域中具有重要的实用价值。
该模型还可以提升数据存储系统的整体稳定性和可靠性,对于如云计算、大数据分析领域也都有价值。
我比较好奇,这个强化学习的训练过程是如何完成的?于是就试着追问了一下:

这里大致解释了系统会收集各种数据,通过数据积累和对模型的优化,一步步优化模型,虽然讲的很有条理,但与我想要的答案有些许偏差。
于是我试着问的更具体一点:

它列举了可用于训练的几种方式,包括常用于训练的各个芯片,还提到了用服务器和云基础设施的方案,基本等于白问,估计论文里也没有这些介绍。
最后,我问它,如果要把LightWarner部署,作用于SSD里,应该用什么方案,它是这么说的:

它的回答倒是很全面,几种可能,以及要注意的点都列举出来了。
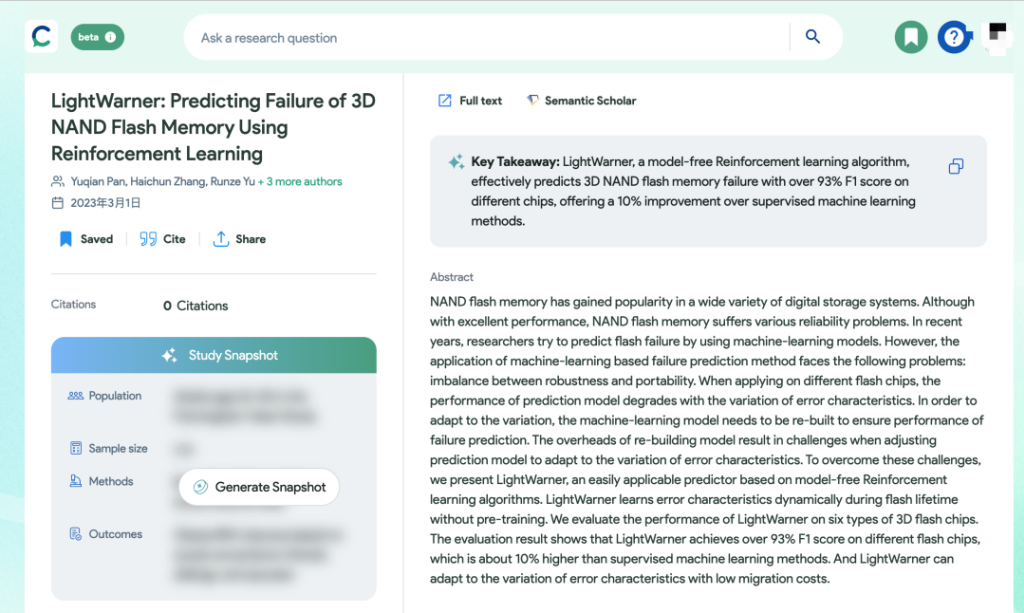
由于我没法直接从IEEE下载论文,最多也只能看到一点摘要信息,对照来看,GPT说的没有明显错误。
目前看来,Consensus对于希望快速了解有哪些论文,想快速了解论文大致要解决什么问题的人,还是很有帮助的。
如果有朋友对这个论文感兴趣,可以试着自行下载获取。多说一句,六位作者全都是国内大学的研究者,Consensus提到的其他论文的作者也都至少是华人居多。







