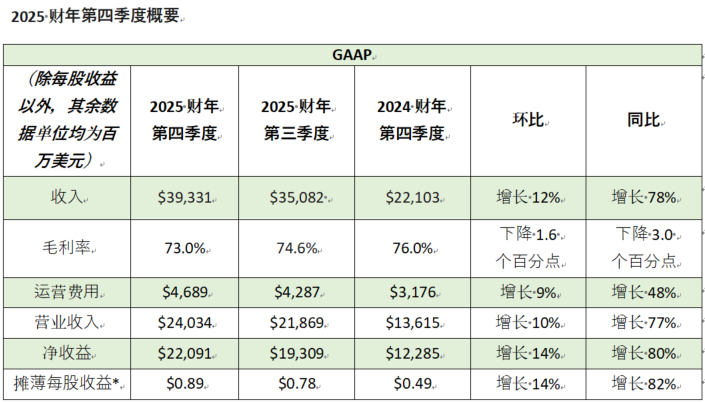
英伟达最近GTC大会发布了系列重磅产品,除了芯片和NIM软件外,在连接能力上继NVLink和NVLink-C2C还发布了X800 系列交换机,为AI训练量身定制,进一步加速各种数据中心中AI、云、数据处理和高性能计算应用。主要还是在大模型训练上是绝对王者。
而另一个高速协议CXL是通过PCIe总线连接DRAM池。以数据中心服务器为例,每个服务器都有定量内存,上面跑应用也是限量供应,超了不行,太少又不划算,CXL作为一个开放式内部互连新标准出现了,目标是跨主机和所有CXL设备构建通用内存池,提高内存容量,实现内存访问和一致性缓存。
它主要有三种变体:
CXL 1 提供扩展内存,让 x86服务器访问 PCIe 连接的加速器设备(如smartNIC 和 DPU)上的内存;
CXL 2 是在多个服务器主机和带有内存的 CXL 连接设备之间提供内存池;
CXL 3 是用 CXL交换机在服务器和CXL设备之间提供内存共享。
这三者都有一致性缓存机制,意味着本地CPU L1 缓存和指令缓存(包含内存中的子集)具有统一的存储内容。 CXL 1 和 2 基于 PCIe 5.0,CXL 3 使用 PCIe 6.0。通过 CXL 访问外部存储器增加延迟。
CXL系统中访问、共享或池化的所有内存都需要CXL 访问方式,也就是需要 PCIe 5.0 或 6.0访问和 CXL 协议支持。x86服务器中的DRAM和GPU中的GDDR 内存是合适的。但英伟达宇宙里没有 PCIe 接口,通过中间层与 GPU 集成的高带宽内存 (HBM) 不算匹配。
AMD的Instinct M1300A 加速处理单元 (APU) 有组合CPU和GPU内核及共享内存空间,有 CXL 2接口。英伟达的超级芯片GB200配置了Arm Grace CPU 和 Hopper GPU,有分离的内存空间。
SemiAnalysis分析师 Dylan Patel 在撰写的CXL和GPU文章中称,他观察到英伟达的 H100 GPU 芯片支持 NVLink、C2C(链接到 Grace CPU)和 PCIe 互连。但 PCIe 互连范围有限。 只有16 个 PCIe 5.0通道,整体运行速度为 64GB/秒,而 NVlink 和 C2C 的运行速度均为 450GB/秒,速度快七倍。Patel认为,英伟达GPU 的 I/O 部分空间有限,与 PCIe 等标准互连相比,英伟达更喜欢带宽。因此,芯片上的PCIe部分未来不会增长,甚至可能会缩小。
国外媒体Block&Files指出,这个说法最终得出的结论是,CXL将无法访问英伟达GPU 的高带宽内存。而x86 CPU 不使用 NVLink,并且 x86 服务器中拥有额外的内存意味着即使外部内存访问延迟增加,内存密集型应用依然可以运行得更快。
因此,当AI训练工作负载在配备HBM的 GPU 系统上运行时,CXL 将不会出现在这些工作负载中,但它可能在运行AI调整和推理工作负载的数据中心 x86/GDDR-GPU 服务器中发挥作用。
GTC上还有群联电子的新发布,它的说法是自己采用了软件中间件。在AI模型训练等高性能计算任务中,经常需要处理的数据量远超过GPU内存的容量,需要频繁地在GPU内存和主存储(如SSD)之间交换数据,影响计算效率。群联的解决方案是在GPU内存和SSD之间创造一个“缓存层”,这个缓存层能部分承担原本由GPU内存要做的任务,从而在不显著增加成本的情况下,间接扩大GPU的“工作内存”,使其能够处理更大的数据集,提高AI训练的效率和规模。技嘉的老大李宜泰称这是把SSD 当作 DRAM 来用。
现在的CXL和 NVLink感觉在各自的圈子里都是无敌的,一个生态无敌,一个带宽无敌,而且都在向外扩展,会不会出现交汇尚未可知。如果谈大火的AI训练,CXL不好说适不适配,但英伟达目前不乐意是可能的。
另一方面也说明,AI训练的需求日益增长和复杂化,计算和存储的融合方案面临创新变革。在此背景下,4月24日,DOIT将在成都世外桃源酒店举办“2024数据基础设施技术峰会”,畅谈如何通过最新的技术创新,来提供更强大的存力与算力支持,以满足日益增长的用户需求。