
当一家初创公司从头训练大语言模型
在网上看到一篇很有趣的文章,Yi Tay参与创办一家名为 Reka 的公司并担任首席科学家 ,主攻大型语言模型,他分享了初创公司训练大模型的心路历程:
训练模型的首要条件是获得计算能力。看似简单易行,但最大的问题却是计算提供商的不稳定性,以及集群、加速器及其连接质量因来源不同而存在的巨大差异。
我们总以为这只是一个加速器选择的问题(TPU 与 GPU 等),所有 GPU 集群都是一样的。这很快就被证明是错误的。
对不同的服务提供商进行了抽样调查,发现即使是相同的硬件,即 GPU(H100),硬件质量的差异也非常大。请注意,这里的硬件指的是集群的整体质量,而不一定是芯片或加速器本身。整体感觉像买彩票。
更具体地说,我们从几家计算提供商那里租用了几个集群,每个集群都有数百到数千个芯片。我们所见过的集群有的还过得去(只存在一些小问题,但只需花几个小时的时间就能解决),有的则完全无法使用,每隔几个小时就会因各种原因出现故障。具体来说,有些集群的节点每隔 N 个小时就会出现故障,问题包括布线问题、GPU 硬件错误等。同一家提供商的每个集群在鲁棒性方面也可能存在巨大差异。
同时,即使其他一些集群的节点明显更稳定,它们也可能存在 I/O 和文件系统不佳的问题,甚至连保存检查点都可能导致超时,或耗费大量时间来降低集群利用率。其他一些计算资源甚至需要完全不同的软件层才能运行,而且对自带代码库的团队不友好 —运行实验或大型工作需要额外的迁移成本。
还有不同的集群会有不同的模型算力利用率(MFU)。如果你不幸找到了一个节点布线不良或存在其他问题的提供商,那么浪费的计算量不可忽视。如果系统的文件系统非常不理想,那么当团队成员开始跨集群传输大量数据时,训练运行的 MFU就会下降。
SK 海力士称HBM今年销售额将占整体内存10%以上
本周,SK 海力士 CEO 郭鲁正在年度股东大会上表示,今年 HBM 在整体 DRAM 内存的销售占比将达到两位数,明年供应情况依旧紧张。
在回答股东为何 SK 海力士在 AI 爆火、HBM 热销的去年仍出现 9 万亿韩元(当前约 482.4 亿元人民币)净亏损的提问时,郭鲁正表示这是因为占销售额绝大部分的常规 DRAM 产品价格下滑,HBM 虽然火爆但去年销售额占比仅有个位数。
在技术层面,郭鲁正认为 HBM 内存将针对客户需求进行定制,逐渐摆脱通用标准产品的身份。有韩媒称SK 海力士已收到来自谷歌的定制HBM订单。
对于中国产能,SK 海力士表示已收到了升级许可,无锡工厂的 DRAM 工艺将更新至1a nm制程。
长江存储QLC闪存 X3-6070擦写寿命已达四千次
CFMS 2024上,长江存储称采用第三代 Xtacking 技术的 X3-6070 QLC 闪存已实现 4000 次 P/E 的擦写寿命。而消费级原厂 TLC 固态硬盘在测试中普遍至少拥有 3000 次 P/E级别的擦写寿命。据市场预测,到2027年 QLC 占比有望超过 40%,大幅高于去年的 13%。
长江存储表示,其采用第三代 Xtacking 技术的 X3-6070 QLC 闪存相较上代产品 IO 速度提升 50%、存储密度提高 70%、擦写寿命达 4000 次 P/E。意味着长江存储的 QLC 技术已开发成熟,可向企业级存储、移动端等领域扩展。忆恒创源就在此次峰会上展示了基于长存 QLC 闪存的 PBlaze7 7340 系列数据中心级固态硬盘。
ASML新款NXE:3800E EUV光刻机晶圆吞吐量提升近22%
本周,据荷兰媒体 Bits&Chips报道,ASML官方确认新款 0.33NA EUV 光刻机 ——NXE:3800E 引入了部分 High-NA(高数值孔径) EUV 光刻机的技术,运行效率得以提升。
NXE:3800E 光刻机已于本月完成安装,可实现 195 片晶圆的每小时吞吐量,相较以往机型的 160 片提升近 22%。
新一代光刻技术 High-NA EUV 采用了更宽的光锥,在 EUV 反射镜上的撞击角度更宽,会导致影响晶圆吞吐量的光损失。因此 ASML 提高了光学系统的放大倍率,从而将光线入射角调整回合适大小。
但在掩膜尺寸不变的情况下,增加光学系统放大倍率本身也会因为曝光场的减少影响晶圆吞吐量。因此 ASML 仅在一个方向上将放大倍数从 4 倍提升至 8 倍,这使得曝光场仅需减小一半。
为了进一步降低曝光时间,提升吞吐量,有必要提升光刻机载物台的运动速率。ASML 工程师就此开发了同时兼容现有 0.33NA 数值孔径系统的新款快速载物台运动系统。对于 NXE:3800E 而言,其光学原件同之前的 3600D 机型相同,仅是配备了更高效的 EUV 光源,所以其吞吐量收益主要来自每次曝光之间的晶圆移动加速。
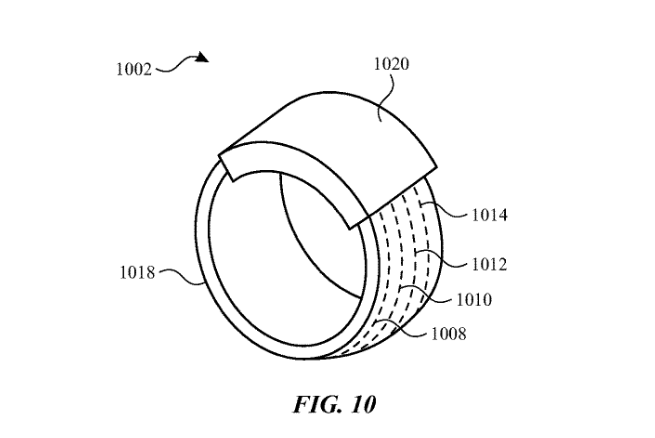
苹果智能戒指专利获批
据美国商标和专利局(USPTO)近日公示的清单,苹果公司获得了一项关于智能戒指的专利,展示了多种交互手势,不仅支持捏合、画圈等,而且支持玩“石头剪刀布”游戏。
图片来自网络
这项新专利名为“皮肤间接触检测”(Skin-To-Skin Contact Detection),主要介绍了实现“第一身体部位和第二身体部位之间的接触或运动手势”的多种方法。
苹果在专利描述中表示:“本专利涉及检测手势的设备和方法。用户可以在一个手指或者多个手指上佩戴如戒指等设备,检测一只手的手指与其他身体部位(如同一只手的其他手指或拇指,或另一只手的拇指)之间的手势。”
苹果在专利中概述了多种交互手势,其中包括打响指,做出剪刀、石头、布手势,用一只手指在另一个手心上画手势、捏指滑动等等。
创业公司Databricks推出1320亿参数的开源模型——DBRX
本周大数据人工智能公司 Databricks 开源了通用大模型 DBRX,这是一款拥有 1320 亿参数的混合专家模型(MoE)。这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。
DBRX 的基础(DBRX Base)和微调(DBRX Instruct)版本已经在 GitHub 和 Hugging Face 上发布,可用于研究和商业用途。人们可以自行在公共、自定义或其他专有数据上运行和调整它们,也可以通过 API 的形式使用。
基础版:https://huggingface.co/databricks/dbrx-base
微调版:https://huggingface.co/databricks/dbrx-instruct
GitHub 链接:https://github.com/databricks/dbrx
DBRX 的效率很高,它是基于斯坦福 MegaBlocks 开源项目构建的混合专家模型,平均只用激活 360 亿参数来处理 token,可以实现极高的每秒处理速度。它的推理速度几乎比 LLaMA2-70B 快两倍,总参数和活动参数数量比 Grok 小约 40%。
Databricks NLP 预训练团队负责人 Vitaliy Chiley 介绍道,DBRX 是在 12 万亿 Token 的文本和代码上预训练的 16×12B MoE LLM,它支持的最大上下文长度为 32k Tokens。







