红杉资本举办的AI Ascent2024大会上,红杉资本合伙人Stephanie Zhan与OpenAI创始成员、前特斯拉人工智能高级总监Andrej Karpathy深入探讨了AI的未来发展和对初创企业生态系统的影响。
以下为Andrej Karpathy对提问的简单概述:
OpenAI在生态系统中的角色及其它公司的机会
OpenAI和其它大模型企业都在努力构建一个LLmOS(大型语言模型操作系统),在这个平台上针对不同垂直领域的公司开发和定制应用,显然OpenAI目前是主导地位。这个系统类似Windows操作系统也会自带一些默认应用。但同时,它也会支持一个丰富的第三方应用生态,针对经济中的各个不同领域。其他公司要想在这个生态中获得一席之地,需要一些时间来找到如何与这个新的基础设施合作的最佳方式。
以早期iPhone应用为例,新技术的探索阶段通常伴随大量实验和学习过程。人们需要时间理解和掌握新技术一样,大模型和相关基础设施的开发和利用也需要时间来发展。这包括了解这些技术的优势和局限性,以及如何编程、调试、监督和评估。
在Andrej个人看来,比起任何一家具体的公司,他更关心整个AI生态系统的健康发展。他希望看到一个欣欣向荣的AI创业生态,而不是被几大巨头垄断的局面。未来可能会呈现一种类似Windows和Linux并存的状态,即会有一些主导的封闭平台,但同时也会有开放和开源的选择。
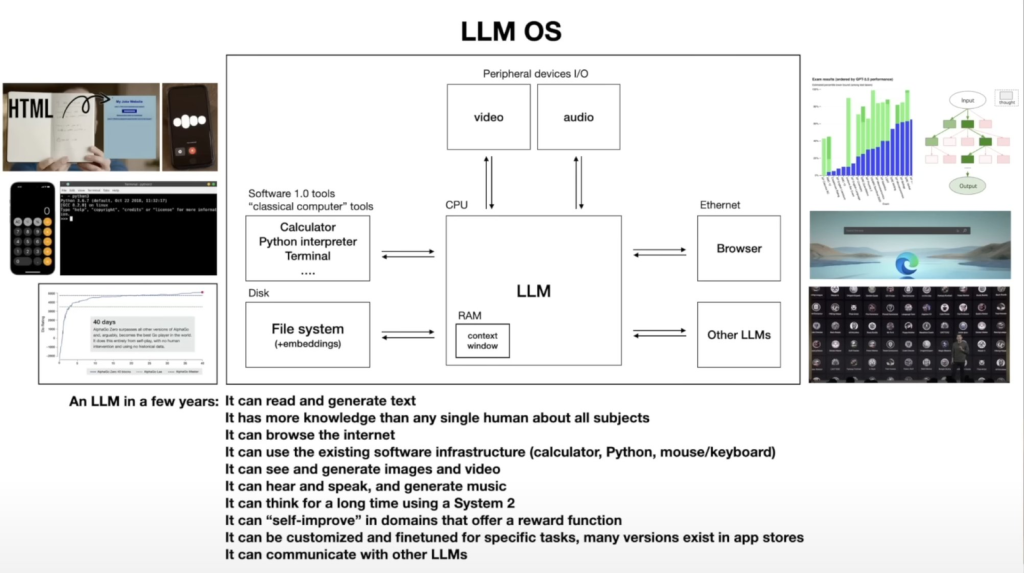
这是在网上找到的LLmOS图,还有几年后对大语言模型的愿景——知识比任何一个人都多,能浏览网页,能使用现有软件,比如计算器,Python等,还可以查看和生成图像和视频,能听能说,能生成音乐,会慢速思考,能自我升级,能为定制任务进行微调,还可以和其他大模型通信。
感言:自我升级,任务微调,这让我想到刘慈欣的一部科幻小说《赡养上帝》,未来随着AI无所不能,机器可以自我维护,人类仅仅作为服务对象存在,他们会忘记生存的手段,忘记技术与科学…虽然百年内不会发生,但依然让人毛骨悚然。
AI模型发展的关键因素:
在AI模型的发展中,模型的规模无疑是最重要的因素。但除了规模之外,还有很多其他重要因素,例如数据质量、算法选择、训练技巧等等。规模可以看作是模型性能的上限,而这些其他因素则决定了我们能在多大程度上逼近这个上限。
此外,强大的计算基础设施和优秀的人才也是不可或缺的。单靠资金和计算资源是不够的,还需要在算法、工程等方面有深厚积累的团队。
开源AI生态的现状和发展:
目前所谓的开源AI模型往往只是开放了训练后的模型权重,并没有提供数据、代码等一整套训练基础设施,因此还不能算是真正意义上的开源。开放大模型权重但不公开数据和代码,类似一个厨子公开分享了他拿手菜的精确配料比例(权重),但没有提供购买这些配料的地点(数据)或具体的烹饪步骤(代码)。
真正的开源需要对整个流程进行开放,让社区可以基于这些模块进行创新。一些大公司可以考虑更多地支持开源生态的发展,这不仅有利于推动AI民主化,也有利于整个产业的进步。
模型组合性方面的进展和思考
与传统软件开发相比,当前的神经网络模型在组合性方面还有所欠缺。不过也有一些组合使用的例子,比如可以将预训练好的模型组件进行组装,然后在下游任务上进行微调。但总的来说,目前还没有一套系统性的模型组合方法论。未来可能需要在模块化、标准化等方面做更多的研究。
成本和性能的权衡
在实际的开发中,我们通常会面临模型性能和计算成本之间权衡。一般的策略是先追求尽可能好的性能指标,而把成本优化放到后面。比如我们可以先用尽量好的模型去生成高质量的训练数据,然后再训练一个更小更便宜的模型去拟合这些数据。总的来说,我们应该遵循”先让系统work起来,再去考虑优化”的原则,即功能第一,优化第二。
AI的局限性
AI尤其是如ChatGPT这样的大模型,在处理复杂问题时存在局限性。虽然它们在收集数据和推理方面很强大,但并不能理解或处理问题的深层逻辑。人类和模型的思维差异导致了处理问题的难易程度不同,模型难以完全模拟人类的逻辑推理过程。
对未来AI发展的期待
为了让AI模型更加高效和智能,需要探索新的训练方法,使模型的学习过程更加符合人类的学习方式,包括练习、笔记、重构概念等。他将AI发展比作是要进入“研究院”,强调AI也需要像人类一样进行深入的自主学习。