
4月,YashanDB正式发布长期支持版本YashanDB V23.2 LTS,标志着YashanDB单机主备、共享集群和分布式实时数仓等完整产品体系,已全面进入可规模化使用的长期支持阶段;同时配套数据迁移工具、监控运维工具和开发者工具,可以满足支撑各类企业应用。
YashanDB V23.2 LTS 经过了严格全面的测试,涉及百万级测试用例,历经上百种长稳与压力模型测试,持续运行30*24h以上,且通过数百种故障场景和百万级持续极端暴力故障的可靠性验证。作为企业级用户投产的长期支持版本,YashanDB V23.2满足各类业务场景、尤其是核心生产场景对数据库系统的严苛要求,是支撑金融、能源、政务等关键行业核心系统的里程碑版本。
在新版本中,YashanDB增强众多企业级能力特性,在产品的性能、兼容性、易用性、可用性方面有了大幅度提升。
高性能:共享集群双节点TPCC性能达312W
共享集群双节点 TPCC性能达312W
23.2 LTS版本共享集群作为一个里程碑版本,具备规模化商用能力,面向高端核心业务场景提供透明多写、高可用以及高性能的数据库能力。
基于如下的环境配置,

经实测,在客户端、服务端分机部署模式下,两节点1000仓700并发运行10分钟,TPCC性能达312W;并且基于此环境,共享集群产品稳定运行,通过7*24小时长稳测试。
组网环境如下:
客户端服务器
CPU 96 Core/256G Mem/100Gb Nic/ SATA 500GB*1
数据库服务器
CPU 96 Core/512G Mem/100Gb Nic/NVMe 3.84TB*2
WDS存储服务器
CPU 96 Core/256G Mem/100Gb Nic/4 x NVMe 3.84TB
网络交换机
100Gb/s 交换机
存储配置如下:
设备类型
分布式块存储产品
设备型号
华瑞指数云SDS2.0 WDS V3
详细参数
硬盘:4 x NVMe 3.84TB
端口:100Gb Nic
缓存容量:256GB缓存
数量
服务器:3台
每台硬盘数量:4块 (容量14TB)
增量同步性能提升8倍
对于数据仓库,数据增量同步入库能力是一个非常关键的能力。23.2 LTS对这部分能力进行了优化,极大提升了数据增量同步入库的性能,对于lineitem表模型,单任务同步性能由原来1MB/s提升到8MB/s:
通过优化降低数据同步任务的内存开销,使得并发数据同步得到提升,并且保持接近1的扩展比;
通过对同步任务流水线优化,提升同步任务的性能;
将增量同步入库的数据直接写入稳态数据,使得数据存储具备较高的压缩比,同时使得数据入库即可获得较高的查询访问性能。
更强的兼容性:Oracle兼容能力大幅提升
V23.2 LTS在V23.1版本的基础上,广泛吸纳了在银行、证券、能源、政务等多个业务场景中的实际需求,持续提升产品的Oracle兼容性,让更多的业务场景可以利用V23.2 LTS进行平滑应用迁移。
语法、语义、高级特性兼容能力全面增强
首先是数据类型方面。V23.2 LTS开发了float(n)类型,为用户提供更高精度的浮点数类型。该数据类型的使用语法、数值范围、有效数字,均与Oracle完全兼容。
其次是内置高级包。V23.2 LTS自带一系列程序包,这些程序包将用户使用SQL语句或PL语句难以完成的功能以PL函数、存储过程的方式提供给用户,以方便用户完成复杂的数据管理、系统运维任务。V23.2 LTS新增对以下高级包的支持:
高级包
功能
DBMS_SQL
解析、执行动态SQL
DBMS_LOB
创建、读取、修改LOB
DBMS_ROWID
提取ROWID中的信息
最后,在过程语言(PL)方面,V23.2 LTS新增与Oracle兼容的批量能力,包括BULK_COLLECT、FORALL,以提升存储过程中批量语句执行的效率。
共享集群内核功能增强
V23.2 LTS共享集群支持了DBLink、二级分区以及统计信息自动收集等,同时支持用户创建自定义本地临时表空间、本地swap表空间,提供实例级的临时数据访问服务,降低实例间的信息交互,提升相应业务场景下的性能。
支持外部表,数据查询更便捷
V23.2 LTS新增了对外部表功能的支持,语法上兼容了Oracle 19C。在YashanDB中创建只读外部表,可以指定链接存储系统上的具体CSV文件或者是数据目录对象DIRECTORY的文件,用户无需将外部数据导入数据库后再进行处理,而是可以像访问普通表一样访问外部表。当涉及大规模数据处理和分析时,外部表可以直接在存储系统上执行查询,避免了数据传输的开销,显著降低了数据存储成本,提高了查询性能。
更加完备的高可用能力
备份恢复功能增强
数据备份和恢复是数据高可用的最后一道防线,对于用户系统的稳健运营至关重要。缺乏有效的备份和冗余机制,可能导致重要数据的永久丢失和损坏。V23.2 LTS共享集群支持了yasrman备份恢复工具,方便用户备份与备份管理,同时支持PITR(Point-In-Time Recovery,基于时间点的数据恢复技术)恢复以及远程备份,用户可以灵活使用相关的备份恢复能力。
数据容灾恢复增强
另外,V23.2 LTS共享集群在YFS元数据被破坏时,可以从fast recovery area(快速恢复区域)获取备份数据,并做自动恢复。同时在多failgroup的情况下,支持数据多副本能力,用户可以通过多副本机制进行数据校验和恢复,从多方面增强系统的可靠性。
更低的使用成本
新增2副本部署,数据存储成本降低1/3
数据存储是数据仓库系统中最昂贵的组件,尤其是在处理大数据时,数据存储的成本尤为突出。为了降低业务高可用模式下的数据存储成本,V23.2 LTS存储服务DN组引入了一主一备这种高可用部署形态,使得业务在获得高可用能力的同时,数据存储由3副本变成2副本,数据存储成本下降1/3。同时,DN组一主一备的部署形态还支持故障自动切换能力,高可用能力满足RTO<10S,RPO=0。
更好的易用性
V23.2 LTS在易用性上做了大量提升,让运维、数据压缩等操作都变得更加简单和高效。
易运维,高效管理
AWR报告中增加了共享集群相关的章节信息(Global Cache Load Profile、Global Cache Efficiency Percentages等),提供了运行期间各种集群相关的统计数据,用户可以更好的了解共享集群性能表现。同时,V23.2版本对集群相关的参数做了优化,部分参数采用了自调优策略,降低用户使用成本,同时实现共享集群后台服务线程自管理。
自适应编码,提供高效的数据压缩能力
存储支持表字段的自适应编码,用户建表不用指定字段的编码类型,系统自动探测选择较优的编码类型,达到较优的编码压缩效果,做到”用户无感知“,大大降低用户使用门槛。
支持一键式收集操作系统和数据库信息
为了更快定位问题和优化系统,YashanDB在V23.2版本提供一键式诊断所需信息,包含操作系统基本信息、操作系统和数据库日志、数据库配置信息和数据库视图等信息,同时打包到指定目录,可以更快、更准地获取到便于定位定界的相关信息,支撑问题解决和性能优化。
更完备的工具体系
在此次版本迭代中,YashanDB全新上线开发、迁移以及运维工具,实现从安装部署、一键迁移、智能运维到应用开发的全生命周期管理,帮助用户简化学习及运维成本。
支持MySQL、DM8等多款数据库迁移
V23.2 LTS配套的崖山迁移平台(Yashan Migration Platform,YMP)新增MySQL、DM8等数据库离线迁移至YashanDB链路,同时新增统计校验、全量校验、失败重试、批量改写、迁移容错、暂停恢复等功能。
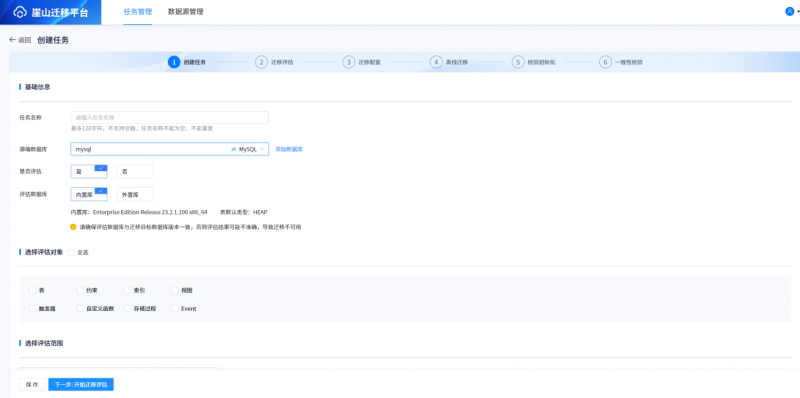
新增分布式可视化运维能力
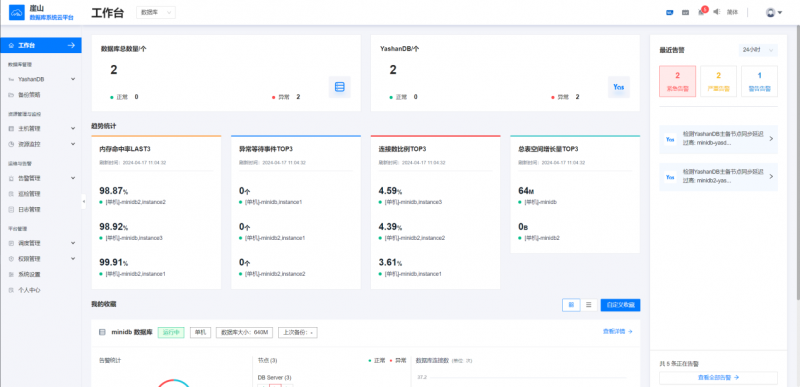
V23.2 LTS实现了分布式可视化运维能力,通过YashanDB 监控运维工具(YashanDB Cloud Manager,YCM)纳管YashanDB分布式数据库,目前支持对单机、共享集群以及分布式全产品形态的巡检管理、监控告警、备份恢复和慢SQL分析等可视化功能,实现了便捷的运维效率。
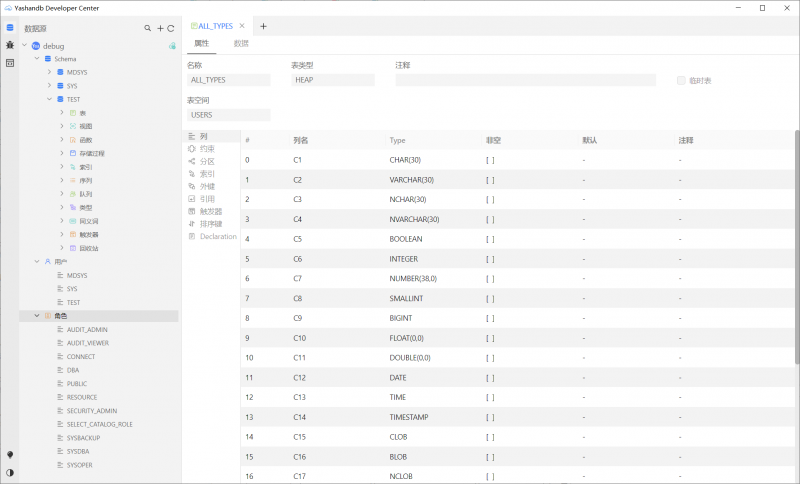
开发者工具全新发布
V23.2 LTS同时配套全新的开发者工具YDC V1.0 (YashanDB Developer Center,YDC),用户可通过YDC可视化地管理数据库中的表、视图、函数等数据库对象。具有丰富的功能和工具,支持数据库连接管理、SQL编辑及运行、智能IDE、图形化对象管理、执行记录、日志、结果集显示以及PL/SQL DUBUG等。
强化开源产品化应用能力
支持sqlalchemy方言包,可通过sqlalchemy框架访问YashanDB数据库;
支持Prometheus监控系统,通过yashandb-exporter组件可以自定义采集yashandb的监控项;
支持使用数据同步工具DataX向YashanDB数据库进行全量迁移;
支持通过GeoServer地理空间系统对YashanDB地理空间数据进行可视化访问。
自YashanDB个人版全面开放下载以来已收到很多宝贵的产品改进建议,在此也全新推出YashanDB V23.2个人版(download.yashandb.com),欢迎前往官网关注了解更多新增和优化特性。通信世







