
前不久,AMD推出了新款加速卡产品AMD AlveoV80。由于采用Versal FPGA自适应SoC与HBM存储芯片,该加速卡既可用于计算的负载,也可用于内存密集型的工作负载,除了支持高性能计算,还支持数据分析、金融科技、存储等领域应用。目前该加速卡已经向全球的客户出货。
在传统固定缓存层次的处理架构中,因数据的读写和输入不规则的访问模式,无论是存储还是网络都存在低效率瓶颈。自适应计算架构由于在计算附近分配内存,既降低延迟和低功耗,又可以灵活适应自定义的数据类型和数据迁移,自1984年问世以来,一直为市场肯定和追捧,又因被AMD收购而不断发扬光大。

“Versal FPGA与HBM解决了大数据和带宽问题,不仅取代了DDR4或其他外部芯片,提升了安全性和灵活性,同时还支持多种协议,减少了功耗、占板面积,降低了时延,帮助用户实现性能的最大化。”5月31日,AMD自适应和嵌入式计算事业部(AECG)高级产品线经理Shyam Chander先生宣布了Alveo V80计算加速卡的特征与行业应用实践。
在推出Alveo V80加速卡的同时,AMD还推出了基于GitHub的设计示例,让硬件的开发者更快上手并缩短产品上市时间,同时也使得之前熟练应用Vivado工具的Alveo硬件开发者能够实现价值最大化。
Alveo V80关键特点与性能提升
AMD Versal HBM自适应SoC架构为系列家族最大的器件Aveo V80加速卡提供支持。

观察其总体架构可以发现,其特点之一是提供260万个LUT的可编程逻辑,作为集成型高带宽网络核心与加密引擎,二是具备多达10890个DSP计算逻辑片,提供较之前代产品3倍的DSP性能提升,消除各类瓶颈;三是采用PCle Gen5接口,支持64G传输速率,扩展MCIO后提供超级通路,实现存储卡的轻松集成与连接。
与上一代产品AMD Alveo U55C相比,AMD AlveoV80加速卡有了全面的提升:存储器带宽从200GB/s提高到820GB/s,逻辑密度从1.3M提升至2.6M,网络带宽从200GB/s升至800GB/s,PCle带宽从32GB/s提升至64GB/s。
通常情况下,使用加速卡都离不开与本地的CPU进行连接,这将限制能够使用到的GPU加速卡的数量。但是V80采取网络附接加速卡方式避开了这一限制,相比传统加速卡,首先是低时延处理传入的网络数据,其次它能避开CPU至加速器的PCle瓶颈,三是消除了分立式网络接口卡(NIC),最终实现每服务器的卡数和计算密度的最大化。这些功能还实现了在线加密、数据包监控和传感器处理。
HBM存储相对DDR而言更为昂贵,但AMDAlveo V80采取灵活的存储配置将HBM应对非常广泛的工作负载,一个有效的对策就是在做PCB的封装尺寸时权衡HBM包装时的芯片占板面积大小,同时以正确地配置FPGA资源作为补充。Shyam强调,此次从UltraScale+U55C升级到AMD Versal V80,以性能的提升来对冲有限的成本增加,实现最高的性价比,而这也是推出Alveo V80的逻辑。
典型案例应用
新款Alveo V80加速卡已经在行业取得了一些成功案例。
在天文领域,联邦科学与工业研究组织(CSIRO)是澳大利亚的一家国家级研究机构,它参与了世界最大的射电天文天线阵列的建设,通过处理无线电波来研究早期宇宙并探索信息演化。
这个最大的射电天文天线阵列项目采用13.1万个天线来采集数据,以15Tb/s的速度持续传输数据,其工作负载主要是以DSP方式支持传感器数据的实时传输与波束成型及连接,由420块AMD AIveo U55C卡、21台服务器和4个机架来提供支持。
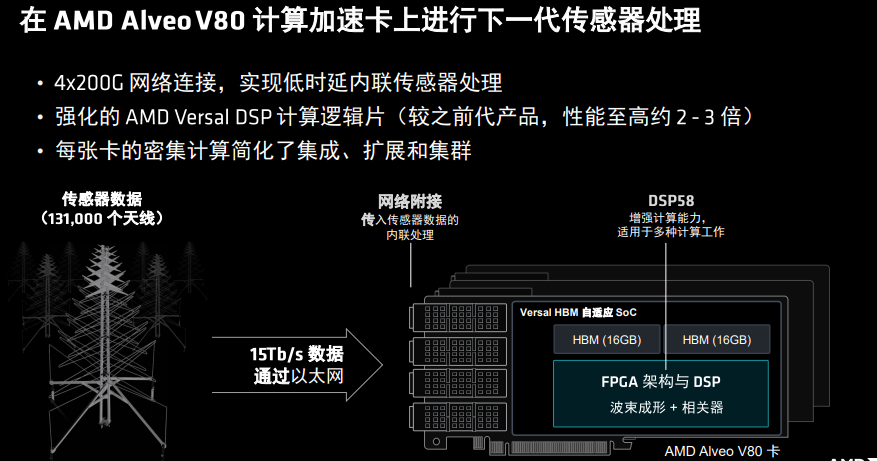
在工作负载越来越复杂,而机架空间有限等情况下,CSIRO采用140张AMD AIveo 80计算加速卡与14台的服务器进行下一代传感器处理,通过4x200G网络连接,实现了低时延内联传感器处理,强化的AMD Versal DSP计算逻辑片,每张卡的密集计算简化了集成、扩展和集群,以几乎相近的成本,在有限的空间内迅速将算力提升达3倍之多。数据显示,该项目功耗从以前的年520千瓦时降低为年236千瓦时,加速器数量减少三分之二,服务器减少三分之一,功耗降低55%,总拥有成本也降低21%,而且功能灵活性极大提升。

建模和算法交易是金融科技企业采用加速卡趋之若鹜的场景。在建模仿真与回测方面,AMD Alveo V80加速卡支持密集计算的FPGA架构与DSP,大数据集与历史定价数据由HBM支持;在低时延算法交易方面,Alveo V80可以加速交易策略和期权定价,另以752Mb的RAM用于定价数据、交易记录,HBM则用于数据集与订单信息。
由AMD AIveoV80推动的网络安全
企业客户普遍重视网络安全问题,都希望能够有非常坚硬坚固的网络安全措施来防止网络攻击,保障数据安全,下一代防火墙也能在确保安全的同时,进一步提高能力。
Alveo V80能实现这样的目标——Versal芯片因为能提供硬化的IP包括加密引擎,能实现800G的内嵌IPSec,HBM则用于缓冲和流量表存储来加强安全性能,同时还能与数据有更好的连接,更好地实现流量管理。
造福传统FPGA开发人员以及更多行业应用
AlveoV80特别面向传统FPGA开发人员,以低时延、自定义数据类型、自定义数据迁移面向自定义工作负载,设计沿用开发者非常熟悉的AMD Vivado套件,简化Alveo硬件设计框架硬件的开发,同时还支持定制和优化。所有的这些示例和使用方式,在GitHub上都有展示,用户也可以直接从上面下载。
“传统上,构建内部的PCle卡需要经过大量的RTL验证,还有很多系统集成的任务。如果使用V80,就可以避开这种系统集成的任务,可以实现非常快速的部署,再加上基于Supermicro和AMD EPYC处理器的锚服务器支持,甚至可以即刻部署。”谈及新一代的定制化性能,Shyam Chander认为Alveo V80真的是“大放异彩”——它不仅能够大幅降低时延,在实时处理方面表现也非常优秀。而这一切,都归功于硬化硬件的处理与灵活应变的优势。

事实上,快速上市始终是Alveo V80的优势与非常重要的价值定位。AMD对于产品的全生命周期有非常重要的考虑和关照,通常不低于五年期的生命周期服务。
针对当今丰富的AI加速器卡市场,Shyam Chander表示Alveo系列产品侧重内联网络、实时处理场景,这是FPGA的自适应SoC的优势,Alveo V80不仅在计算和存储器带宽方面提供非常高的性价比,在工作负载方面也提供了非常高的价值,包括逻辑资源和低时延,以及各个节点的可扩展性。他相信,Alveo系列在未来还将继续呈现强大的生命力。







