
导语:50+ 论文成果、CVPR 自动驾驶大挑战赛“端到端规模驾驶“获奖综合自动驾驶模型、NVIDIA Omniverse 云传感器RTX 重磅亮相CVPR 2024,充分展现了NVIDIA Research 在前沿科学研究领域的硬核实力。

NVIDIA 的研究人员站在快速发展的视觉生成式 AI 领域最前沿,正在开发用于创建和解释图像、视频与 3D 环境的新技术。
NVIDIA 将在 6 月 17 日至 21 日于西雅图举行的国际计算机视觉与模式识别会议(CVPR)上展示 50 多个此类项目成果。其中的两篇论文(一篇关于扩散模型训练动态,另一篇关于自动驾驶汽车高清地图)入围了 CVPR 最佳论文奖。
NVIDIA 同时还在 CVPR 自动驾驶大型挑战赛中获得了大规模端到端驾驶类别第一名。这座重要的里程碑代表 NVIDIA 正在将生成式 AI 全面应用于自动驾驶模型。NVIDIA 提交的获奖作品在全球 450 多件参赛作品中脱颖而出,还获得了 CVPR 创新奖。
NVIDIA 在 CVPR 上展示的研究成果包括:一种可轻松定制以描绘特定物体或角色的文本转图像模型、全新的物体姿态估计模型、神经辐射场(NeRF)编辑技术以及一种能够理解流行语的视觉语言模型等。另外还展示了介绍汽车、医疗和机器人等行业的特定领域创新的论文。
这些研究成果都加入了强大的 AI 模型,帮助创作者能够更快地将其艺术构想变为现实,加快制造业自主机器人的训练速度,通过协助处理放射学报告为医疗专业人员提供支持。
NVIDIA 感知与学习研究副总裁 Jan Kautz 表示:“人工智能,尤其是生成式人工智能,是一次关键的技术进步。从可以为专业创作者提供超强助力的强大图像生成模型,一直扩展到可以帮助开发新一代自动驾驶汽车的自动驾驶软件,都将在 CVPR 上呈现 NVIDIA Research 如何不断拓宽技术边界。”
NVIDIA 还在 CVPR 上发布了 NVIDIA Omniverse Cloud Sensor RTX,这套能实现物理级精确传感器仿真的微服务,从而加速各类全自主机器的开发工作。
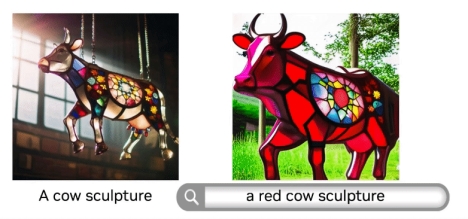
无需微调,JeDi简化自定义图像生成
扩散模型是当前基于文本生成图像的核心方法。使用扩散模型的创作者通常以一个特定的角色或物体为中心,例如围绕一只动画老鼠创作一个故事,或者集思广益讨论一款特定玩具的广告等。
此前的研究已经让这些创作者能够通过微调(即用户在自定义数据集上训练模型)对扩散模型的输出结果进行个性化处理,使模型能够专注于特定的主题。但这一过程非常耗时,而且不支持普通用户使用。
由约翰-霍普金斯大学(Johns Hopkins University)、丰田工业大学芝加哥分校(Toyota Technological Institute at Chicago)和 NVIDIA 研究人员共同撰写的论文《JeDi》提出了一种新的技术,使用户只需要使用参考图像就能在几秒钟内轻松实现个性化的扩散模型输出结果。研究小组发现该模型达到了最先进的质量水平,明显优于当前基于微调和无微调的方法。
JeDi 还可以与检索增强生成(RAG)相结合,为品牌产品目录等数据库生成特定视觉效果。
新基础模型让姿态更完美
NVIDIA 研究人员还在 CVPR 上展示了用于物体姿态估计和跟踪的基础模型 FoundationPose。该模型无需进行微调,即可在推理过程中即时应用于新的物体。
该模型通过一小组参考图像或者物体的 3D 呈现了解物体的形状,并且在流行的物体姿态估计基准测试中创下了新纪录。在了解物体形状后,它就可以识别并跟踪物体在视频中的 3D 移动和旋转情况,即使在光线条件较差或有视觉障碍物的复杂场景中也不受影响。
FoundationPose 可用于工业应用,以帮助自主机器人识别和跟踪与之交互的物体。它还可以用于增强现实应用,使用 AI 模型在实时场景上叠加视觉效果。
NeRFDeformer转换3D 场景,只需一张快照
NeRF 是一种 AI 模型,可以基于在环境不同位置拍摄的一系列 2D 图像进行 3D 场景渲染。在机器人等领域,NeRF 可用于生成现实世界复杂场景的沉浸式 3D 渲染,例如杂乱无章的房间或建筑工地等。一旦需要进行更改,开发人员就需要手动定义场景的转变方式,或者重新制作 NeRF。
伊利诺伊大学香槟分校(University of Illinois Urbana-Champaign)和 NVIDIA 的研究人员则使用 NeRFDeformer 简化了这一过程。在 CVPR 大会上展示的这一方法,可以利用单张 RGB-D 图像成功转换现有的 NeRF。RGB-D 图像由正常照片与深度图组合而成,深度图可以捕捉到场景中每个物体与摄像机之间的距离。

VILA 视觉语言模型获取图像
NVIDIA 与麻省理工学院(MIT)联合开展的 CVPR 研究项目正在推动视觉语言模型技术的发展。视觉语言模型是一种能够处理视频、图像和文本的生成式 AI 模型。
该研究小组开发的 VILA 是一个开源视觉语言模型系列。在测试 AI 模型回答图像问题能力的关键基准测试中,VILA 的表现优于先前的神经网络。VILA 独特的预训练流程解锁了新的模型能力,包括更加深厚的世界知识、更强大的上下文学习能力以及多图像间的推理能力。

VILA 可以理解流行语并基于多个图像或视频进行推理。
VILA 模型系列支持使用 NVIDIA TensorRT-LLM 开源程序库进行推理优化,并且可以部署在数据中心、工作站甚至边缘设备的 NVIDIA GPU上。
在 NVIDIA 技术博客和 GitHub 上均可进一步了解 VILA。
生成式AI 助力自动驾驶和智慧城市研究
在 NVIDIA 主笔的 CVPR 论文中,关于自动驾驶汽车研究的论文有十多篇。其他与自动驾驶汽车相关的重点内容包括:
· NVIDIA 自动驾驶汽车应用研究,赢得 CVPR 自动驾驶挑战赛冠军并在如下 demo 中进行了演示。
· NVIDIA AI 研究副总裁 Sanja Fidler 于 6 月 17 日的自动驾驶研讨会上发表关于视觉语言模型的演讲。
· 多伦多大学和 NVIDIA 研究人员共同撰写的论文《在轨迹预测中生成和利用在线地图的不确定性》成为 24 篇入围 CVPR 最佳论文奖的论文之一。
此外,在本届 CVPR 上,NVIDIA 为 AI 城市挑战赛提供了有史以来最大的室内合成数据集,助力研究人员和开发人员推进智慧城市与工业自动化解决方案的开发。该挑战赛的数据集使用 NVIDIA Omniverse 生成,这是一个由 API、SDK 和服务构成的平台,可帮助开发人员构建基于通用场景描述(OpenUSD)的应用和工作流。
NVIDIA Research 在全球拥有数百名科学家和工程师,专注于 AI、计算机图形学、计算机视觉、自动驾驶汽车和机器人等领域的研究。了解更多有关 NVIDIA Research 在 CVPR 上的相关信息:https://www.nvidia.com/en-us/events/cvpr/。





