
AI算力运营现状
今天,如果随便打开一个提供AI算力运营的平台,基本上都是基于容器云,即Kubernetes架构的。这种架构有许多优越性,对于平台开发者来说门槛低,可以借助于国外开源社区的代码、知识和方案,只需在上面构建用户界面和运营功能,即可提供简单的算力运营功能。

客户需求多样化
随着客户群体范围不断拓展,既有需要借助外部推理服务和应用使用AI的用户,也有拥有自己AI团队、用自有数据训练大模型的大型企业。许多用户利用天云融创软件的SkyForm算力调度平台管理GPU算例进行应用开发,需要连接本地IDE与算力池中的资源;生物信息行业不仅需要GPU资源运行如AlphaFold这样的AI应用,还需要CPU资源进行基因分析。算力的多样性可以大大提高资源利用率,降低算力运营者的成本。
容器集群方案的局限性
由于大部分AI用户习惯使用容器的方式进行模型训练和推理,天云融创软件起初也像其他算力运营平台一样,重点支持单个和多个容器组合的应用。然而,随着客户群体的扩大和应用形态及算力需求的多样化,我们发现现有的容器集群方案存在许多局限性:
1.模型训练中调整依赖组件:每次都需重新制作镜像,对于需要频繁调整库和方法的开发人员来说,调试周期长,效率低。
2.多机训练镜像瓶颈:多机训练时,从镜像库下拉镜像效率低,启动时间长,镜像仓库容易成为瓶颈。
3.GPU故障处理复杂:在大规模GPU集群中,故障处理复杂,需自动判断和处理故障GPU,并重新调度任务。
4.复杂任务调度能力不足:AI和大数据任务需要高并发、低延迟的调度能力,Kubernetes缺乏复杂任务调度能力。
5.存算分离架构延迟:Kubernetes的存算分离架构增加了数据访问延迟,影响计算效率,特别是在AI和大数据场景下。
6.本地IDE开发限制:许多开发者希望使用本地IDE(如VSCode),通过SSH远程连接算力池开发模型和应用,现有方案需要提供复杂的网络转发功能。
天云融创软件的解决方案
基于上述问题,天云融创软件开发了同时支持裸金属(HPC)和容器应用的SkyForm算力调度系统。这一系统不仅能调度多容器应用,还能同时调度和运行裸金属HPC应用。
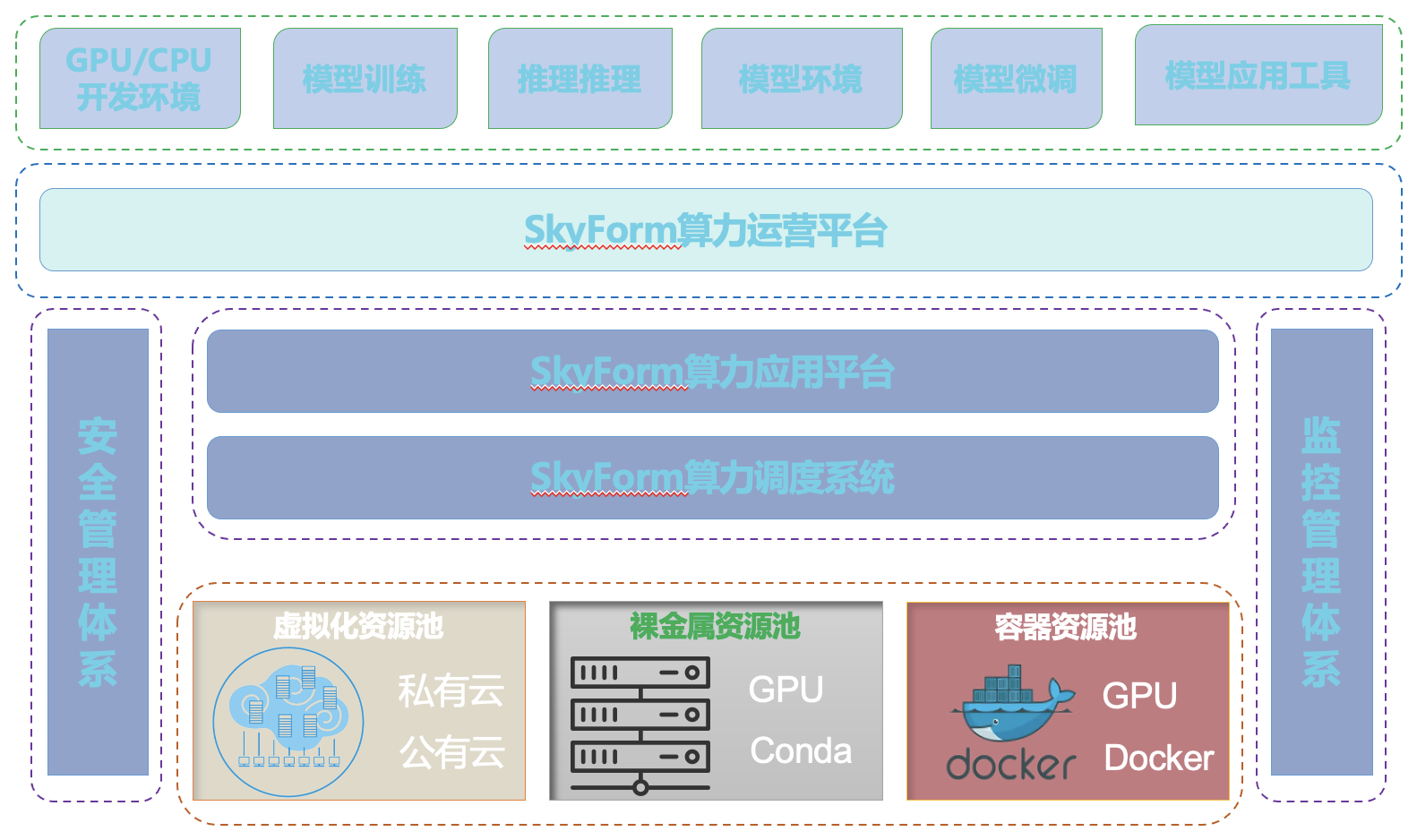
在裸金属上使用Conda建立个人的用户空间,既能达到与容器类似的固化软件组件和库的功能,还能避免下拉容器镜像的动作,将大型分布式模型的启动时间从几十分钟缩短到十几分钟。
天云融创软件的SkyForm调度器每15秒钟监视一次GPU的健康状况,自动处理故障GPU,重新调度任务,实现模型的断点续训或推理的自动恢复。
通过我们产品自带的4层和7层网络协议转发,用户可以动态申请GPU资源,然后使用自己桌面上的VSCode,安装远程连接插件,通过SSH与分配的容器资源联通,实现远程开发功能。
最后
天云融创软件的SkyForm算力调度管理平台已经在国内多家智算/超算中心、多个行业领域部署应用,为AI训练和推理提供安全可靠的算力服务。我们坚持裸金属和容器混合算力调度和管理,以满足多样化的客户需求,提高算力资源利用率,降低运营成本。





