
当英伟达的股价屡创历史新高,登上全球市值第一的宝座,人工智能的算力故事迎来了最高潮。但总讲一个故事难免审美疲劳,“AI+企业数据”有望成为下一个章节的主角。
新主角的接棒登场,通常需要重量级人物的引荐,话语权无出其右的黄仁勋无疑适合扮演这样的角色。他认为,用“数据飞轮”收集数据、捕捉对话、产生智能,将是生成式AI最有影响力的企业级应用,“每五年增长100倍”的神话将诞生于此。
事实上,数据智能这条新赛道已吸引了众多参与者,其中不乏算力基础设施、大模型领域的跨界大佬,也有DataBricks、Snowflake等在大数据市场深耕多年的国际巨头。而近日openAI收购数据库公司Rockset,则再次印证了数据对大模型的无量前景。目前,最流行的玩法是“大力出奇迹”——依托基座大模型的不断进化,打通数据与AI之间的阻隔,进而催生杀手级应用。
由于众所周知的原因,国内在先进算力基础设施方面存在掣肘因素,虽然openAI终止对中国的API服务这一举措为国内的基座大模型巨头们提供了更多的发展空间,但单纯“卷”基座大模型依然很难取得竞争优势;与此同时,数据智能的商业模式尚存变数,除了过往被验证有效的“搜索-数据-广告”模式外,还没有真正跑通的新模式浮出水面。
如果将数据智能比作一座高山,那么国内企业能否像中国登山队当年开辟珠峰“北坡”路线一样,找到另一条通往山顶的道路?
诞生于2022年的数巅科技,在创业途中洞察大数据和大模型双飞轮对企业的机遇,其创始人何昌华博士带领团队另辟蹊径,探索出了通往数据智能巅峰的崭新路径——回到数据智能决策的原点,依托更具原创性和性价比优势的企业大模型,以生成式智能分析应用AskBI为突破口,最大限度降低企业大模型的使用门槛,为数据智能全链路自动化开启新篇章。

从场景出发向下发力,拓展“大模型+工具”模式的进化空间,也许恰是更有助于国内企业突围的数据智能“北坡”路线。数巅科技一路走来,留下的每一步脚印都值得借鉴。
伟大的公司都是从“一个问题”开始
对何昌华博士来说,数据智能并非从天而降,创业的想法也不是心血来潮,最初的种子很早就在土壤中萌芽了。
在斯坦福大学,“同学们都想找更好玩的企业或自己创业”,这种氛围让何博士感同身受。加入谷歌后,他发现“搜索引擎的商业模式就是收集全世界的数据,并用数据解决问题”,大数据、人工智能等技术创新也随之产生,这正是数据智能赛道的根基。
后来,何博士主导的咖啡因项目获得谷歌公司最高的技术奖项,但他还是因为“不甘于平淡”而选择加入国内顶尖的金融科技公司。金融行业数据规模大、质量好,曾被何博士当作实践数据智能理想的最佳舞台。
然而,他逐步发现金融行业也存在诸多碎片化场景,业务与技术的分割问题屡见不鲜,很多AI应用因投入产出比不高而被迫搁浅。
这让何博士开始反思:与其纠结于数据智能的宏大叙事,不如做些更实在的事情——“降低数据智能的使用门槛”,才是市场中最迫切需要解决的真问题。
每一家伟大的公司,都是从“一个问题”开始的。2022年,何昌华博士着手组建创业团队,数巅科技由此启航。
大模型是数据智能全链路自动化的终极答案
在创业初期,数巅科技的解题思路是“DataOPS+MLOPS”,将数据治理与模型训练、推理结合起来,为客户提供一揽子工具,使其更容易操作,进而降低使用门槛。
从公司愿景的角度看,实现从数据到智能决策的全链路自动化,是何昌华博士梦寐以求的目标。他以自动驾驶进行类比:即使暂时做不到L4、L5,也至少可先做到L3,再通过“副驾”(工程师)辅助,让用户的感受接近L4甚至L5。
那时,面对纷繁复杂的数据场景,大多数人工智能公司主要借助AI小模型解决痛点问题。每个场景往往对应不同的AI算法,要分别做调整和优化。这意味着“副驾”的负担很重,距离自动化还比较遥远。
直到2022年11月,大模型横空出世,何博士在亲自试用并向业界朋友详细了解“内情”之后,又经过了反复思考的过程,最终得出了自己的判断:“大模型为数据智能全链路自动化提供了真正可能”。
其实,这个结论的形成并非一帆风顺。彼时盛行一种说法——“大模型是人类所有已知知识的压缩”。如果大模型能回答一切问题,那么数据处理和分析环节就可能失去独立存在的价值。
擅长独立思考的何博士却有不同的看法:根据大模型的基础架构和计算模式,还不能做到“包打天下”。拥有知识也不是大模型的必要条件,基于知识产生逻辑判断才是其核心能力。因此,所有数据应该通过企业数据和外挂的知识库来解决,大模型则调用不同工具完成相关任务。
由此可见,大模型非但不是数据公司的“终结者”,而且可能成为数据智能全链路自动化的“拯救者”。与过去的AI小模型相比,大模型解决的最关键问题是以通用的语言沟通能力和任务拆解能力,取代大部分需要定制化的服务,为数据智能自动化奠定坚实基础。
当然,自动化不可能一蹴而就,对于某些应付不了的问题,大模型还可调用工具加以解决。有人可能“抬杠”——以前定制小模型,现在定制工具,不是一样的吗?区别在于,工具可以做到标准化,且数量级规模比场景小很多,这对自动化带来的正面影响足以催生质变。
打造驱动数据智能真正落地的企业大模型
对数巅科技这样的开拓者而言,看清战略方向之后,更重要的是打磨产品及方案,解决数据智能的落地难题。
第三方机构的研究表明,在AI应用落地进程中,80%的问题出在数据上,20%的问题与算法有关。通常的情况是,做数据的公司缺乏AI基因,而做AI的公司多数也不精于数据。
数巅科技的核心团队来自数据、计算存储、AI等多个领域,在技术创新、产品研发、商业化运作等方面都拥有丰富经验,这为打破AI与数据之间的壁垒、构建企业大模型创造了必要条件,openAI收购Rockset也印证了这一内在逻辑。
在大模型领域存在一个悖论——无法在同时满足高准确率、高通用性和低成本的情况下,确保项目落地实施。数巅科技在用户可接受的范围内做了一些调整,将“高准确率”定义为业务可用,即准确率足够高,出错的时候能被用户识别,且可解释产出的结果。
从降低客户使用门槛的角度看,企业大模型的性价比也至关重要。因此,数巅科技将“低成本”定义为项目落地初期的成本一定要低,可以单机部署,且使用和维护零门槛;同时将“高通用性”定义为能够工具化、自动化。
据何昌华博士透露,在数巅企业大模型研发过程中,发现300亿到500亿参数产生的逻辑能力已经足以解决给定场景的问题,且调用相关知识和工具后通用程度也较高,这样就能解决客户做数据分析的实际问题。
测试结果显示,数巅百亿大模型分析准确度达95%以上,远超千亿大模型 GPT4+NL2SQL70%左右的准确度。在不拼参数规模也能取得好成绩的背后,离不开一件“秘密武器”的鼎力支撑。
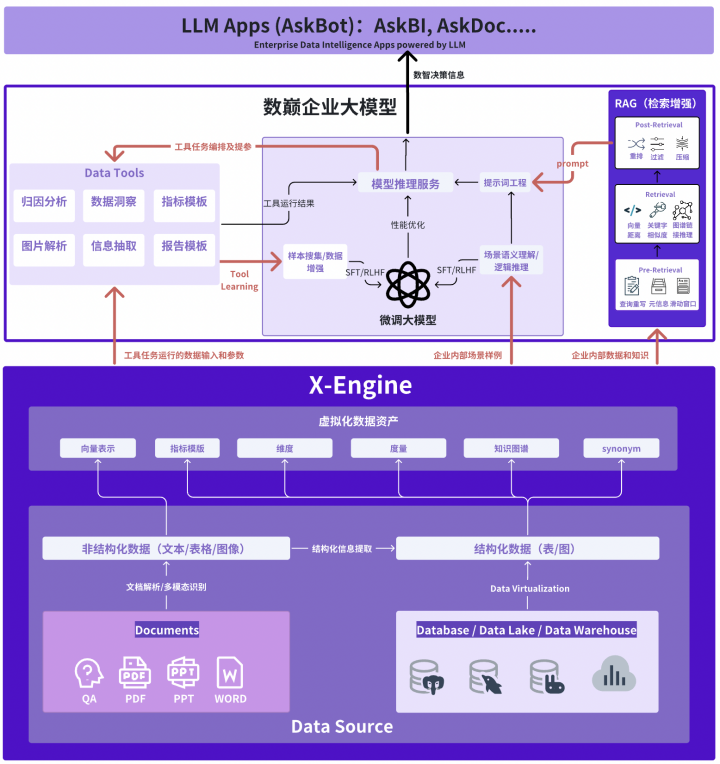
数巅企业大模型
在数巅企业大模型的底座中,数据虚拟化引擎X-Engine发挥着举足轻重的作用。它为数巅企业大模型提供多模态数据的统一接入、计算存储、数据治理、数据加速等一站式能力,堪称数据智能自动化的最佳推进器。
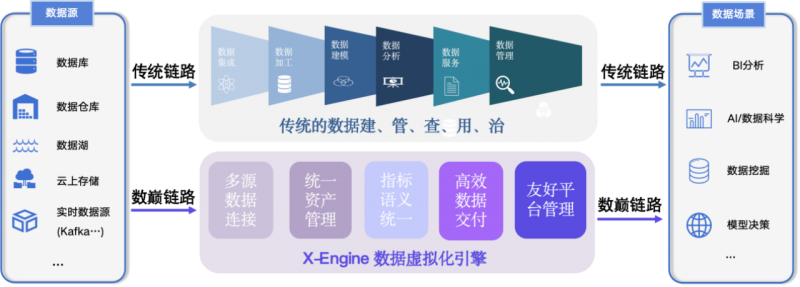
与传统的数据治理ETL模式不同,X-Engine提供的是一张虚拟的表,生成这个表无需耗费计算存储资源,只有访问数据的时候才进行计算。为了无限接近随取随算的理想状态,数巅科技一方面提升计算存储性能,比业界同类产品增强5至10倍;另一方面用智能引擎做预测,基于预测提前自动生成结果,并以系统自适应的方式覆盖超预期需求。在X-Engine的加持下,数据全链路自动化的梦想逐渐照进现实。
以某头部银行信用卡业务财务中心进行财务数据分析和洞察的场景为例:该行有近1万名员工负责各分行的损益分析,每到月底会面临大量取数、制表、制图、解读等工作。在生成式智能分析应用AskBI的助力下,员工通过自然语言交互,即可完成229条以上的财务指标及数十个维度的自由组合分析,员工1分钟内即可快速获取各财务数据分析和报表查询,准确率可达90%,显著提升了员工的工作效率以及银行的数字化管理能力。
虽然市面上也有类似功能的产品,但大多与AskBI的定位和演进方向不同。一些产品将自然语言直接生成代码,主要为工程师服务,而AskBI则定位于“大模型帮助企业基于数据做决策”,提供从数据提取到报表生成再到归因洞察分析的完整链路,促进数据智能全面落地。
据了解,数巅企业大模型解决方案已在金融、通讯和制造业等场景成功落地,朝着端到端地帮助企业解决从数据到决策的难题迈出关键一步。站在更长远的视角,“让数据智能像水电一样简单”,让每位员工都可以基于生成式智能分析做出数智化决策,真正实现数据智能决策全民化,是数巅科技的发展愿景。何昌华博士表示,如果大模型调用工具解决数据全链路自动化这条路走得顺利,能在三年内集齐数据智能领域的主要工具,数巅科技有望让梦想尽快照进现实。山顶还很遥远,路上的风景值得期待。





