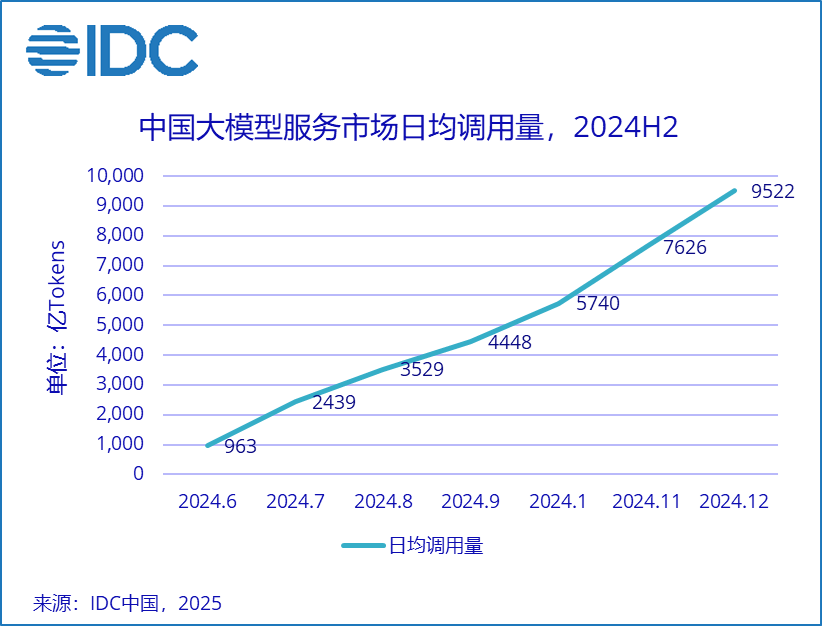
AI作为引领新一轮科技革命和产业变革的战略性技术,正成为发展新质生产力的重要引擎。预计未来两年,AI大模型将落地50%+行业场景,引领广泛的智能化革命。数据作为AI产业链的基础要素,其规模与质量直接决定了AI智算的广度与深度。

在AI大模型的全生命周期中,包含4个关键环节:
● 数据归集:数据采集方式多样,需兼容NFS、SMB、S3等多种存储协议,构建超大容量、灵活适应的“数据仓库”。
● 数据预处理:针对数据在此阶段的复杂性与无序性,需构建可灵活应对混合IO负载与多变读写模式的存储架构。
● 模型训练:需高效加载数据至GPU进行计算,对存储性能有严格要求(高IOPS、高带宽、低延迟),以确保训练过程的流畅与高效。
● 推理应用:需快速加载海量模型文件,单个文件大小在几十GB至上百GB不等。若同时启动数十个推理业务,整体数据量将达几十至上百TB,对读取效率提出较高要求。
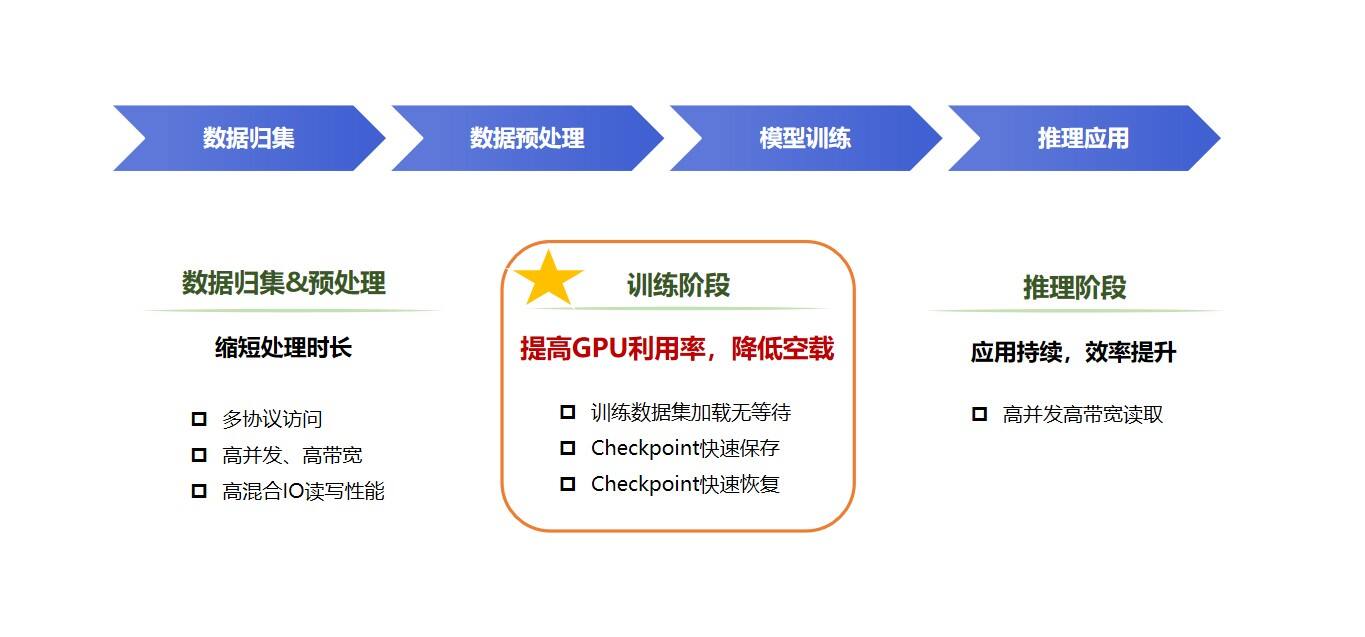
在整个流程中,模型训练是最重要的一环,对存储系统性能要求极高。为确保训练任务如期完成,实现训练数据快速加载、GPU无等待、Checkpoint(AI大模型训练过程中定期保存的模型状态快照)快速保存与恢复的目标,通常需要存储系统提供数百GB/s的带宽,以及千万级的IOPS处理能力。
以自然语言处理(NLP)在大型预训练语言模型GPT3中的Checkpoint保存场景为例,175B的参数规模,其Checkpoint文件达3TB左右,若要在30s内完成Checkpoint文件的保存,其写带宽需达到100GB/s。为此,亟需构建高性能、高可扩展性的数据存储底座,以支撑AI大模型的核心业务流程。
凭借在数据存储领域十余年的创新与积淀,宏杉科技精耕细作,以MC27000-MOFS高性能分布式并行存储系统与MacroDisk智能盘柜为核心,打造智算中心AI存储解决方案,为AI大模型的精研之路奠定坚实基础。
MC27000-MOFS高性能分布式并行存储,提供高效运行引擎
数据归集和预处理阶段,MOFS系统可构建基于传统HDD硬盘的海量数据资源池,支持NFS/CIFS/HDFS协议互访与多节点并发读写,极大地加速了数据的导入与处理。其单集群单文件系统容量可达1000PB,文件数量达千亿级,充分满足AI智算对海量数据的处理需求。
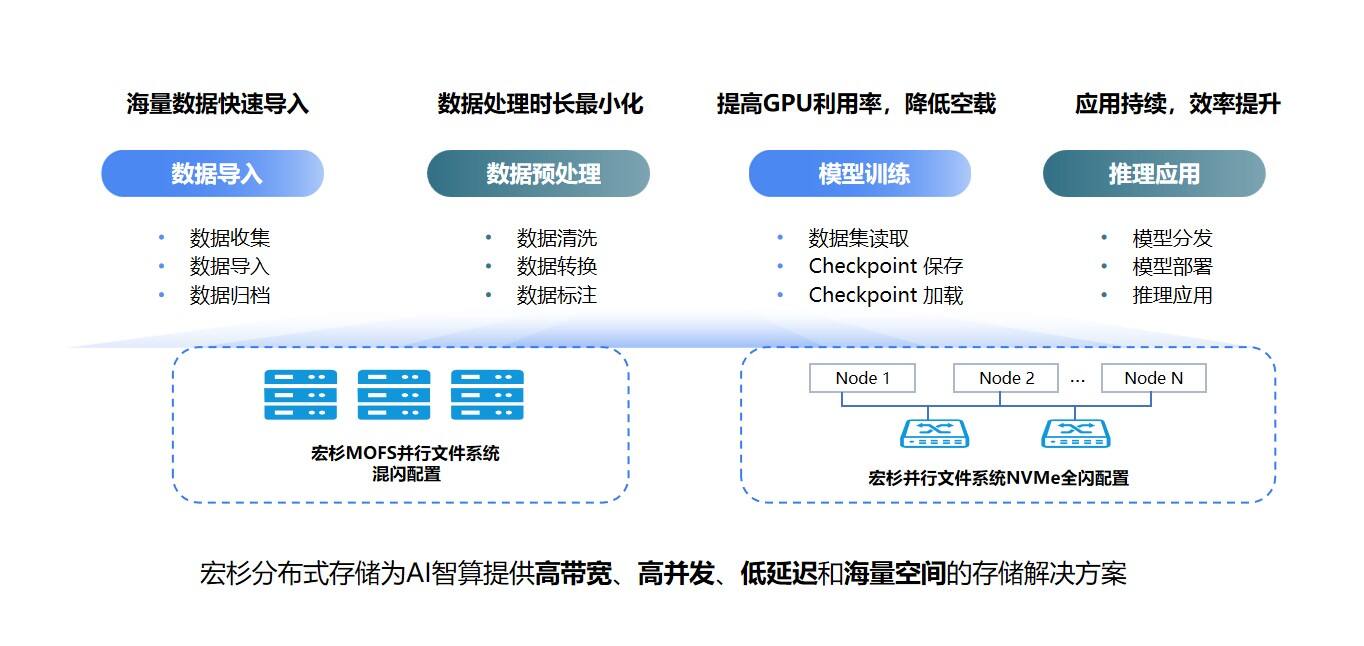
在模型训练和推理阶段,MOFS系统可提供全NVMe介质的高性能资源池,通过部署增强型客户端,并融合客户端切片、MPI-IO、RDMA网络、小文件聚合等先进技术,系统单节点混合读写性能可达30GB/s以上,实现了数据的高效处理与流畅传输。
MacroDisk智能盘柜,打造稳定存储底座
当前,Lustre/GPFS等并行文件系统已被广泛应用于AI训练流程之中,成为驱动AI智算发展的关键力量。然而,Lustre的多个数据存储单元(OSS)并未自带数据保护功能,当一个客户端或节点发生故障时,其中的数据在重新启动前将不可访问。因此,存算分离是此架构下提升系统整体可靠性的关键路径。
在Lustre/GPFS并行文件系统+集中式存储的整体架构下,宏杉科技以MacroDisk智能盘柜为关键硬件支撑,面向HPC、AI等场景,无缝对接客户Lustre/GPFS等原有并行文件系统,为AI训练构建了极致性能、极致可靠的存储资源池。
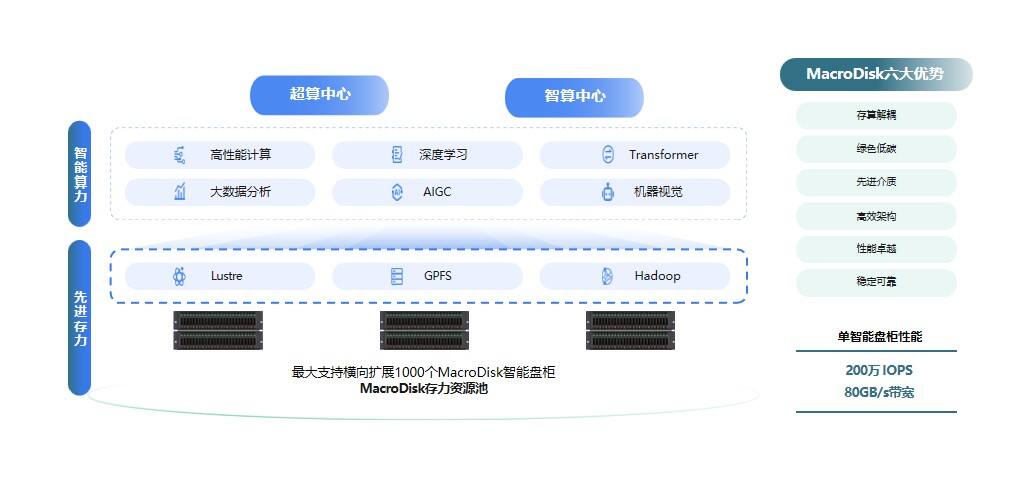
MacroDisk支持NVMe over ROCE+INOF、NVMe over FC两种高速数据传输方式,单套设备即可提供200w IOPS、80GB/s带宽;采用双控制器Active-Active架构,确保数据的高效读写及访问;集成磁盘监测、慢盘检测、磁盘诊断等功能,实现对磁盘健康状况的实时监控与精准维护;引入CRAID3.0技术,采用22+3或者23+2的比例进行数据硬盘和校验硬盘的配置,在保障数据安全的同时,实现高达92%的空间利用率,为AI智算中心的稳定运行与未来发展提供了强有力的支撑。
随着国家政策的持续推动与技术趋势的加速演进,AI智算正迈向更加高效、智能、安全的新纪元。作为一站式数据存储专家,宏杉科技将紧跟行业发展脉搏,以数赋智,用更多前沿创新方案助力AI产业“新蓝海”的开拓。