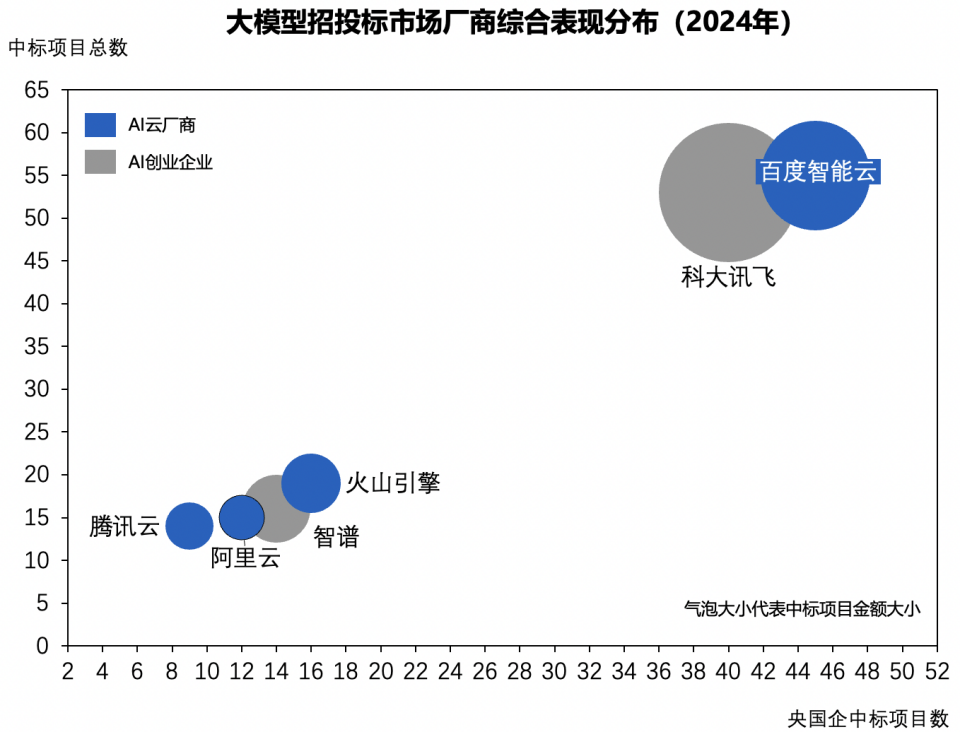
2024全球闪存峰会日前落下帷幕,峰会汇集闪存产业链专业人士以及存储技术爱好者,会议当天,腾讯云存储专家架构师郭强发表精彩演讲,分享了腾讯云最佳实践与存储解决方案,为听众带来很多干货和技术参考。
以下为演讲实录:
我是来自腾讯云存储的架构师郭强,今天非常容幸能够在这里和各位前辈,以及业界的这些同仁们一起探讨存储相关的话题。
我带来的主题是腾讯云数据湖助力AIGC,让多模态变得更简单。主要讲什么内容呢?我们现在有单模态到多模态演进的趋势,这样的过程追一定会涉及到数据处理,包括一些性能上的要求等等,对我们的存储提出了挑战。
在这里我们会遇到什么问题或者面对问题的时候有哪些选择?以及我们最终做了什么选择?这是一些值得探讨的话题。今天我在这里用这25分钟的时间和大家简单聊一下。
接下来我的演讲里面有一个FLOW,是我在整个AIGC过程中涉及到的所有环节。
前面是一个总体概述,大致度这个存储有一个要求上的理解和概念。之后用一个详细的PPT展示具体的哪个环节里面遇到的问题。
很有必要做一个前情提要。我们的大模型发展。一个非常温柔的下午,我坐在外面,东北三线城市的老妈给我打电话,我妈打了一个电话问我,儿子,AIGC和之前你跟我说的人工智能有什么区别?后面的话我已经不记得我讲的是什么了,但是只觉得那一刻AIGC可能真的火了。可以看到在最开始的时候有很多前辈从上世纪50年代开始做这个事情,追溯到50年代这些前辈们生成的非常粗糙的图片,让大家有感觉说原来计算机可以做这个事情。90年代的时候有了神经网络的夹持,大家科医生成一些文本和图片,在一些特定的场景解决一些特定任务,这个时候大家第一次感觉到原来计算机真的可以做这件事情。2010年前后,因为当时有了GNN网络的出现,也就是生成式对话网络,一个生成器,一个判别器,两个人去博弈,大大加速了通用大模型的迭代速度。我们有的时候分不清到底是人生成的还是机器生成的。
近几年大家知道的ChatGPT 3、4、5,今年年初OpenAIGC发布的sora,让大家觉得AI时代可能真的来到了。
伴随着这样的发展,首先它的模型参数会有一个指数级增长。ChatGPT3应该有1750亿个参数,ChatGPT4就更多了。伴随着这样组数的增长,伴随着它来的一定是数据量的增长。ChatGPT3是几十TB的数据量,因为它是文本类的,当我们从单模态走向多模态的时候一定会引爆一些图片、视频进来,这个时候体积一下子就会变得很大。现在有一些客户已经用了TB级的。现在看到有一个趋势会走向DB级,这是我们遇到的第一个问题,当我面对这种海量数据的时候,我们应该去选择什么样的存储。首先要满足一个要求,它可以制成海量的数据,我也不知道我的数据以后会变的多大,可能会需要它有一个非常良好的扩展性,在这样海量的数据下能不能花最少的钱,这是非常现实的问题。我们大致对它有了这些诉求。
我们先多模态发展,这里面的问题已经被AIGC的从业者解决了,简单来说,它会把所有的这些无论是文本、视频、图片还是音频的数据,都通过各自的编码器转换到一个更高级的纬度里面,更高的纬度也就是写间的向量,变成一个多维向量。变成一个多维向量之后,最终所有人就会在learn space里面做到一个统一,大家团聚了,训练的时候大家可以相互作用,让我们的模型演进更快。
这个多模态给我的直观感受是最好的,为什么?我觉得它非常有前景。我来自杭州。有一天我走在西湖的上面,旁边突然有个小孩问我,叔叔,这棵树是什么树?我赶紧把我的ChatGPT3打开,VPN一连,我详细描述了一下这个树,期待它给我回复,但实际上失败了。如果这个时候我是多模态的,直接一张照片下来问,这是个什么树?马上结果就回来了。多模态的AIGC的模型,以后一定会有非常广阔的应用空间,也同样技术会普惠到每个人。
训练模型,从data collection进来,我们做数据的预处理,预处理之后做特种工程,之后就是训练数据,之后推理、输出。假如你和我是一家公司的CTO,要搭这个环境,首先要解决一个问题,有这么多的平台,都要存储,一般是S3协议,但这些平台比如说data collection这里基本说跑不掉大数据,所以它是HTPS协议。第二,在训练和推理的时候应该是post C语义,这个时候S3和两个协议之间怎么去对,肯定对不上,我们就会遇到一个问题,这个协议不知道怎么办,我们对于这块存储的第一个要求,就是somehow somewoy去支持,让我们在I3 HDFS之间做一个流转。这里有很多的模块,简单我称为ABCD,这些模块都需要读数据,都需要处理数据,都需要访问它们,怎么办呢?如果回到十年前,在每一个A下面放一个存储,B下面放一个存储,数据拷贝很多份,解决了低时延,也解决了LPS的问题。现在容忍不了了,就算现在去搞成四份,在流动性上也会有问题,我需要时间来等它从A到B,B到C,会非常非常浪费整个AIGC训练的过程。
在这个过程中一定要提供统一的数据湖,能够它存储只存一份,每个平台访问的时候都非常快。数据向着异地迈进,一定会涉及在单位时间内读取尽量多的数据,这个时候就是带宽,一定要也一个高吞吐,高吞吐的前提是能够提供稳定低时延,不然就是抛开时延谈高吞吐都是耍流氓。所以这个地方一定要加上限制条件低时延。这是我觉得有这么多的可能的诉求。
下面是推理,推理之后能不能随便生成的东西出来,肯定不行。比如说前段时间我在you tube上面看,一个博主训练B站的网友的评论,去大战弱智吧。如果我给它灌的都是这些数据,模型又不拒绝,最后输出的结果一定会非常混乱,这个人输出的逻辑或者语气可能都不对。去年7月份网信办发了一个文,叫《生成式人工智能服务管理暂行办法》,这个办法规定,对于AIGC生成的这些内容需要满足一定的合规性。所以在这里我们一定要做审核,这是一定的。
我们对存储的过程讲完以后就到了真正核心的地方。这是在整个AIGC从数据进来到出来的画面。
数据进来,大家会从全世界爬数据,也可能用一些公共的平台,比如这些公共平台的数据集提供一些现成的数据给你,或者爬虫或者怎么样,或者去一家国际公司,我在新加坡、泰国各个公司,每个公司里面都有数据,拉到某一个点,比如新加坡,怎么办?我们提供了一个分布式的存储迁移工具MSP,它是一个分布式的,可以做一个动态的互缩容,满足一个大带宽,同时结合腾讯云的全球加速网络,可以让我们在传输的过程中优先走腾讯云的骨干网,这样就避免跨国传输的时候遇到的问题,就是丢包、失败率高等等,这些是不可控的,从这个国家的路由出去是哪一个供应商,有可能这个供应商马上面临倒闭,这是有可能的,它的线路自然就不会太好,进一步会影响我们整个的效率。
数据进来之后到了load dataset(音),我们就要去做一个预处理。在这里的时候又要想到这个问题,如果我们是CTO会面临什么样的问题?数据读过来需要各个平台,然后在这里面reduce的时候是positive, 然后training(音),在这个过程中要去做一个不同语义的支持。
我们把它想象成一个真的桶,数据桶。大家在自己的办公室里一般都有饮水机,上面有一个水桶,把水桶倒过来,这就是我们的桶。上面有一个嘴,这个嘴很小,大概只有一厘米多的直径。下面有15升的水,这就好象我们通用的云对象存储,比如cos就是这样,15Gb往下倒很久很久,倒不出来,很着急,因为后面的训练一直在等,训练又要用到GPU,浪费了后面的时间就是浪费了大把的金钱。我就要想怎么把这个口给砍掉,把水直接倒出来。
我们推出了腾讯云的产品叫GooseFS-Cache,Goose是一个鹅。它提供了三级加速,首先利用了GPU闲置CPU资源和下面的一些memory,以及它的一些SSD。大家知道,去买GPU服务器的时候有很多浪费CPU和SSD,这个过程追我们把它用起来,变废被宝。怎么用呢?在fields(音)客户端,在GPU这边部署之后,当我们的数据在memory命中的时候直接在近端返回,这是非常快的,这个我们叫Cache级的加速度,就是GooseFS-Cache L1。当它命中的时候没有怎么办?这是在一个GPU的NVM里面的,这个返回也非常快。如果这里没有命中,从隔壁拿一下,传过来,在异部的拉一份过来,原因是以防他一会儿还要用。这是GooseFS-Cache L2。
最后一个对客户是无感知的,只要你用了我们的数据湖,我帮你做。原理是什么?即使我们有两层加速以后还面临两个问题,我有一些是热点文件,我们会根据热点,以及访问的热度等等,我们把它做一个复制,可以在各个节点之间。这样的存储可能是一个reaching级的产品,实际上它是这样架构的,我们就可以在近端点放一个,当这一块的GPU访问的时候可以做到精准访问。这是GooseFS-Cache L3。
整个的方案里面有一个非常好的点,没有给客户或者用户增加过多的负担,因为我是变废为宝。这种情况下,我们可以提供百万级的IOPS,以及tb级别的存储。
训练的时候训练完成要写check point,写check point实际上是一个大学问,最开始写check point的时候不是很大,大家没有人在乎它浪费的时间,随便写,随便间隔,现在不一样了。现在随着模型变大,它的check point从原来的兆级别、G级别,已经变成了TB级别。如果我的check point是1TB,用对象存储15Gb的带宽,大概十几二十分钟才能写完。我姑且认为它是十分钟,check point一小时写一次,一天24小时,相当于一天24小时有四个小时都在写check point。为什么这是一个不能容忍的事情呢?我们写check point的时候实际上就是把GPU的显存写到持久化里面去,这个过程中是所有的GPU都要停下来的,它们停下来,就等于每个GPU节点返回YES OK,所有的节点都说OK了,大家再回来开始干活。
这个过程中又回答之前说的GPU合适的浪费的问题。我们认为或者业界认为写1TB十几秒,才能符合我们现在对效率的要求。我们倒推一下,1TB除以十几秒,算出来大概需要800Tb的带宽,所以我们需要寻求一追办法去解决它。业界的第一种方式是用高性能存储,比如文件存储,但是它很贵。再一种就是异步写的方式,就是先写到memory或者SSD里面,之后再异步到持久化存储里。但是有两个问题,一个是安全性,万一断电了怎么办?二是会让我们的整个架构变得更复杂。这个过程中,我接触的绝大部分的AIGC的从业者选择的都是写高性能存储。
既然确定了要写高性能存储,我们有没有什么办法能让这个高性能存储更便宜呢?文件存储买的时候可能是100TB,他买了一个空间,确定一天的训练100TB就够了,每天就要付这么多的钱,非常贵。我们一天是一个流线,在这个过程中能不能参考一下TCP的传输信息的方式,能不能做一个窗口滑动。比如从100TB变成50TB,省了一半的钱,就很开心。
在这里,我们基于COS原生,去做了一个GooseFS-X,通过这个X去和桶之间做数据流动。首先这个GooseFS-X是一个全闪存的分布式高性能文件存储,它和COS之间会做一个流动,所有的计算节点挂载都可以挂在GooseFS-X,挂载之后,它的文件路径和对象存储里的前缀一一对应,所以我就可以批量的存进来,批量的导入,配一次,后面都是自由流动的,这里面就会给我们做后面训练的时候省一部分钱。
前面的数据预处理和训练,以及推理完了以后要看最后一部分,相对比较简单,我们推出来要做一个审核。
用我们数据万象的审核产品,比如我输入一个“请画一幅日落的山水画”,我进来了,给它做一个审核,这个审核是什么呢?比如说涉黄涉政涉恐涉爆广告等等,如果发现它是同数无害的就低分放过,如果发现有点危险就高分拦截,如果低分放过了以后我们的模型生成一幅画出来还是在数据湖上,在返回客户端之前还要再审核一下。
如果我输入的词是“请画一幅行进间的坦克”,只有这一句话,没有背景。AIGC输出来的坦克它的背景会是什么呢?我不知道,它成出来的很有可能是不合规的,这个时候我对输出也要做一个审核。当然现有的客户有两个都用的,也有用一个的,最后输出的时候倾向于这样的是最多的。输出的时候可以用一下万象里面其他的音视频能力。
我把腾讯云数据湖的Data lake Architecture讲完了。最后一点时间讲一下数据万象,它是整合了腾讯的AI技术,用了这么多的技术去打造一个数据处理的百宝箱。它是一个长在对象存储COS上面数据处理的工具,音频、视频、图片、文本都是可以的。并且我们向大家开放了API、SDK,大家可以直接使用。如果你已经用了COS SDK,这个时候不需要更换SDK,可以用COS SDK直接访问万象。
我们今年做了一个大模型叫Meta Insight,它实际上是一个结合图文的大模型,需要解决什么问题呢?面对海量数据的时候可以做一个精准搜索,这个搜索不需要输一些特定的格式,只需要输像刚刚的“给我一幅画黑白的山水画”,就可以搜出来。原理比较简单,我们在数据入湖的时候给它做一个抽象,抽象成向量,向量后放到向量数据库里,当你靠API检索数据的时候,输入的这些内容也去做一个向量化,两个向量一匹配,分高的就反还给你了。
其实我们最初做这个事情的初衷不是为了搞一个大模型,我们在思考用了腾讯云的数据湖客户,当他们有了百亿千亿万亿文件的时候,他一定会为搜索文件而担忧,有困难。我们在这个过程中,通过这种方式让大家面对海量数据的时候提供一个工具和可能性,让大家在这个过程中解放一些劳动力。
这是我们COS Data lake的所有东西,涵盖了训练、推理、数据治理、审核的一些内容。
我想讲一个事情,腾讯云的数据湖时钟坚定不移地致力于支持和推动AIGC的发展,相信术业有专攻,应该让专业的人做专业的事,从而解放劳动力,让AIGC从业者的宝贵时间都用在上层的应用和创新当中。
谢谢大家。