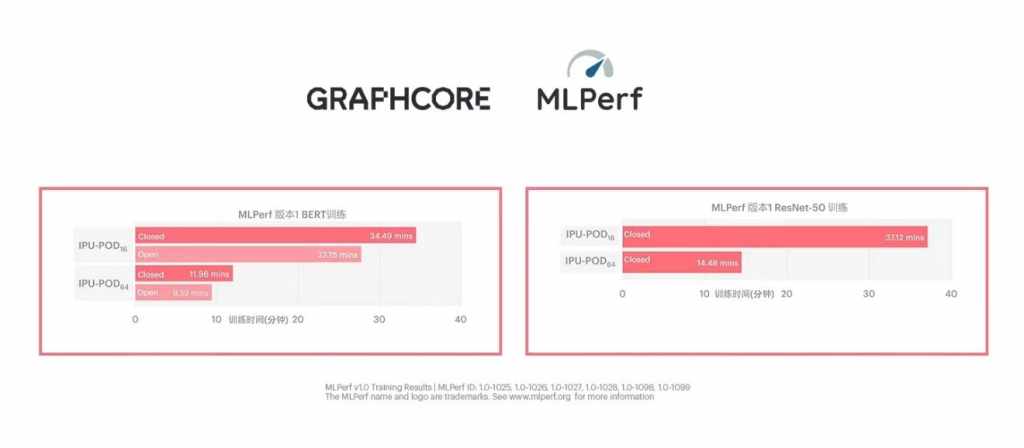
来源:内容编译自blocks & files。

最新版本的MLPerf存储基准测试需要仔细研究,以便比较供应商的单节点和多节点存储系统在三个工作负载、系统特性以及两种基准测试运行类型中的表现。基准测试背后的组织MLCommons联系了我们,并提供了有关基准测试背景和使用的信息。我们在这里转载它,以帮助评估其结果。

MLCommons的市场总监Kelly Berschauer告诉我们,基准测试最初主要针对的是人工智能实践者,他们以训练数据样本和每秒样本数来思考,而不是以文件、MBps或IOPS等存储人员的方式来思考。MLPerf存储工作组的成员决定在v1.0版本中,将存储基准测试报告与购买者寻找的更传统指标(MB/s、IOPs等)对齐。基准测试中的每个工作负载定义了一个“样本”(对于该工作负载),作为一定量的数据,每个单独样本的大小围绕这个数字有一定的随机波动,以模拟我们在现实世界中会看到的一些自然变化。最终,MLPerf将样本视为一个恒定大小,即实际大小的平均值。平均大小分别是Cosmoflow(2,828,486字节)、Resnet50(114,660字节)和Unet3D(146,600,628字节)。由于样本是“固定”大小,我们将其乘以每秒样本数,得到MiB/s,并让人工智能实践者知道他们可以反向计算出他们感兴趣的每秒样本数。
比较每个GPU的获得MiB/s值并没有太大的价值,因为基准测试认为“通过结果”是Unet3D和ResNet50的加速器利用率(AU)达到90%或更高,而Cosmoflow则为70%或更高。我们文章中包含的图表仅显示MiB/s/GPU结果的变化高达10%。基准测试使用AU百分比作为阈值。这是因为,由于GPU是重要的投资,用户希望确保每个GPU不会因为存储系统跟不上而缺乏数据。基准测试并没有额外的价值,以保持GPU超过90%的忙碌(或Cosmoflow超过70%)。
比较每个客户端系统的MiB/s值(基准测试称之为“主机节点”)也不是很有价值,因为在给定的计算机系统中可以安装的GPU数量有物理限制,但在“主机节点”上可以运行的模拟GPU数量没有限制。因此,基准测试报告的“主机节点”数量与需要托管相同数量GPU的实际计算机系统数量之间没有关系,我们无法从中得出任何结论。基准测试使用模拟的GPU,使存储供应商能够运行基准测试,而无需实际付出大量投资获得如此多(通常)的主机节点和GPU。
给定的存储设备可以支持的模拟GPU训练集群的“规模”是这个基准评测的核心要点。即对于给定的存储设备集,它可以支持多少同类型的模拟GPU。在现代的可扩展架构中(无论是计算集群还是存储集群),没有“架构最大”性能,如果你需要更多的性能,通常只需要添加更多的设备。这当然因厂商而异,但这是一个好的经验法则。v1.0版本的提交者使用了数量各异的存储设备,因此我们预计报告的最高性能数字会有很大的差异。
不同的GPU集群“规模”肯定会对存储施加不同程度的负载,但每个GPU的带宽必须保持在所需带宽的90%或更高,否则结果将不会“通过”测试。
分布式神经网络(NN)训练需要定期在GPU群体之间交换NN权重的当前值。没有权重交换,网络将根本无法学习。AI社区已经对权重交换的周期性进行了深入研究,基准测试使用了每种工作负载权重交换间隔的公认规范。随着训练集群中GPU数量的增加,完成权重交换所需的时间会增加,但权重交换是必需的,因此AI社区将其视为不可避免的成本。基准测试使用“MPI屏障”来模拟定期的权重交换。MPI屏障迫使GPU都到达一个共同的停止点,就像现实世界训练中的权重交换一样。基准测试最近计算的AU不包括GPU等待模拟权重交换完成的时间。
无论GPU集群的规模如何,每个GPU的每秒带宽值都将是相同的值,只有在模拟权重交换期间,才会定期出现没有存储IO请求的时候。如果将总数据移动量除以总运行时间,似乎随着规模的增加,每个GPU所需的B/W在下降,那是因为如果没有正确计算权重交换的“静止时间”,就会出现这种情况。
MLPerf计划在v2.0版本中将功率数据作为基准测试的一个可选方面纳入其中,并且很可能会要求报告每次提交时设备消耗的机架单元数。同时,它还在考虑为v2.0增加几个额外的功能。与所有基准测试一样,MLPerf工作组将通过一段时间持续去完善这个评测标准。