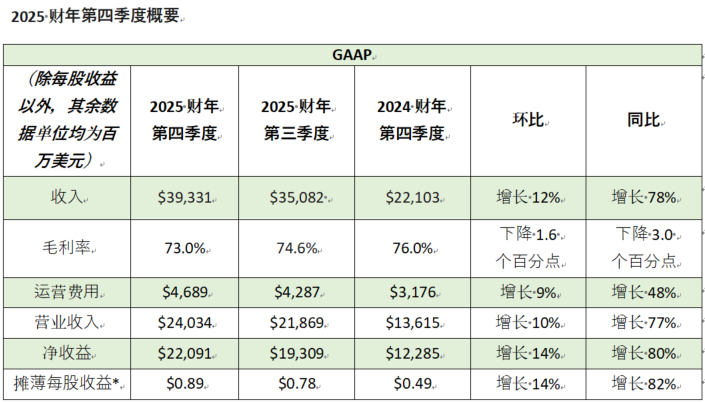
近日,经由马斯克和xAI团队的特别批准,外媒STH的Patrick Kennedy进入到了这个有较多敏感信息的数据中心内部,拍了很多照片和视频,一定程度上,满足了很多人对于这种奇观级别的超算的好奇心。
Colossus的4U液冷服务器,强调为液冷而设计
Colossus采用的是来自Supermicro的液冷机架服务器,服务器采用的是英伟达HGX H100平台。这里岔开点话题:经常有朋友问,什么是HGX、什么是DGX还有MGX?有什么区别呢?

最常见的,MGX主要面向OEM服务器厂商,服务器厂商用它做成AI服务器。HGX常用在超大规模数据中心里,由像Supermicro这样的ODM厂商生产。而DGX是一个集成度最高的方案,开箱即用,看起来金光闪闪,印有NVIDIA Logo的就是。
因为Colossus也是超大规模数据中心,所以,就用了HGX,选择的提供商是Supermicro。STH能进入Colossus内部,除了要感谢马斯克,也还得谢谢Supermicro。
Colossus这里采用的是Supermicro的4U服务器,每台服务器有8块H100,把8台这样的服务器放到一个机架里,单机架就有了64块H100。以8个机架为一组,每组就含有512块H100 GPU,整个Colossus有大概200个机架组。

Supermicro这台4U液冷服务器是完全面向液冷设计的服务器,而不是风冷改造的,这样可以提供更好的液冷散热。此外,这款服务器有更高的可维护性,服务器的组件都安装在托盘上,可以在不移出机架的情况下对服务器进行维护。

服务器后面板配有四个冗余电源,安装有三相供电系统,还能看到400GbE以太网网线,以及一个1U机架大小的歧管,配合底部的带有冗余水泵的CDU(冷却分配单元),为整个液冷系统提供支持。
Colossus的存储部分,SSD闪存大面积部署

Colossus的存储部分也用了Supermicro的存储设备,设备中配备了大量2.5英寸的NVMe存储槽。这让我想起了最近一则消息,有外媒传出,特斯拉要向SK海力士(Solidigm)采购大量企业级SSD的新闻。
随着AI集群规模的扩大,存储系统逐渐从基于磁盘的存储转向闪存存储,因为闪存不仅能显著节省电力,还能提供更高的性能和密度,尽管每PB成本更高,但从整体拥有成本(TCO)来看,在这种规模的集群中,闪存更具优势。
Colossus的网络部分,用以太网替代了IB
多数超算都在使用InfiniBand等技术,而xAI团队选择了英伟达的Spectrum-X以太网方案,不仅获得了超强的可扩展性,部署和维护成本也更低了。在高带宽、低延迟场景中表现更好,搭配智能流量管理功能,提供了高效的数据传输。
具体而言,网络部分采用了Spectrum SN5600交换机提供高达800Gb/s的端口,每个GPU配备400GbE的BlueField-3 SuperNIC专用网卡,提供GPU间的RDMA连接。另有400Gb的网卡给CPU用,算下来,每台服务器的以太网带宽总计3.6 Tbps。

xAI为GPU、CPU和存储各自建立了独立的网络,这样可以确保GPU和CPU之间的通信需求得到优化,GPU网络专注于高速的RDMA数据传输,而CPU网络则支持其他管理和计算任务,从而提高整个系统的性能和效率。
Patrick在文中表示,不要小瞧400GbE的速度,这个带宽甚至超过了2021年初顶级Intel 至强服务器处理器的所有PCIe通道总带宽。而现在,每台服务器就配备了9条这样的连接速度。就问你快不快??

英伟达提到,在训练Grok这种超大型模型时,整个系统都没有出现任何因流量冲突,而造成的应用延迟增加或数据包丢失的情况。Spectrum-X的拥塞控制功能,能将系统数据吞吐量保持在95%,而传统以太网在发生冲突时,只能提供60%的数据吞吐量。

在Colossus超级计算机外部,可以看到大量Tesla Megapack电池。由于计算集群在启动和停止时存在毫秒级的电力波动,电网或马斯克的柴油发电机难以应对,因此采用了Tesla Megapack作为电网与超算之间的能量缓冲装置,确保供电稳定。
以上内容根据STH的Patrick Kennedy在Colossus超算看到的内容所整理和改编而来,供各位猎奇、学习。