11月13日,国内知名人工智能企业彩云科技在其位于北京的总部召开了一场名为“From Paper to App”的媒体沟通会,正式向公众推出了史上首个基于DCFormer架构的通用大模型云锦天章,以及同样是基于DCFormer架构升级迭代的杀手级应用——彩云小梦V3.5。

不过,相较于新模型和新产品迭代,业界更关注的是DCFormer架构在效率层面的大幅提升,彩云科技CEO袁行远介绍,彩云科技团队在基于DCFormer打造的模型DCPythia-6.9B上,实现了在预训练困惑度和下游任务评估上都优于开源Pythia-12B。这意味着,DCFormer模型在性能上,实现了对Transformer模型1.7-2倍的性能提升,这是在大模型基础技术层领域近年来少有的突破。

目前大模型训练的主要成本由三部分构成,即训练成本、推理成本和储存成本。其中,训练成本是其中的主要构成,例如,GPT-3的单次训练成本据估算高达140万美元,这些成本主要由两部分构成,GPU的使用和大量的电力消耗,电力消耗方面,GPT-3的训练耗电量高达1287兆瓦时。而据《华尔街见闻》对GPT-4的细节披露显示,GPT-4总共包含了1.8万亿参数(GPT-3只有约1750亿个参数),相对应的,专家测算,Open AI在25000个A100 GPU上训练,单次训练成本则达到6300万美元,即便是在当下,利用8192个H100 GPU进行训练,也需要2150万美元。
“在Scaling Law失效,真正、彻底的人工智能实现之前,可能仅仅是能源消耗,我们的地球都无法支撑。”袁行远介绍,“优化模型架构,提升大模型的效率,从而有效地降低能耗,就成为必由之路。”
彩云科技的DCFormer架构即是基于模型架构优化的思路而诞生。在今年举办的ICML(国际机器学习大会)上,彩云科技团队正式向公众介绍了DCFormer架构,提出可动态组合的多头注意力(DCMHA),替换Transformer核心组件多头注意力模块(MHA),解除了MHA注意力头的查找选择回路和变换回路的固定绑定,让它们可以根据输入动态组合,从根本上提升了模型的表达能力,实现在DCPythia-6.9B模型上,在预训练困惑度和下游任务评估上都优于开源Pythia-12B模型的表现。
1.7-2倍的性能提升,意味着同样的训练任务,在同等GPU的情况下,效率的同级别提升,之前如果预训练需要消耗100兆瓦时的耗电量,现在仅需要50兆瓦时,成本将大幅缩减。
与此同时,对于很多致力于开发大模型的中小型人工智能公司而言,模型的效率提升也给他们参与AI浪潮提供了全新的机遇。袁行远介绍,譬如Open AI做的是通用大模型,它可能有3万张A100卡,但只有十分之一的算力集中在故事创作上,那就是3000张卡,如果我们能在模型结构上具备优势,利用DCFormer架构实现2倍的训练效率提升,那么只需要1500张卡就能实现与Open AI同样的效果,如果模型架构的效率优势达到4倍,那就只需要750张卡就可以实现。

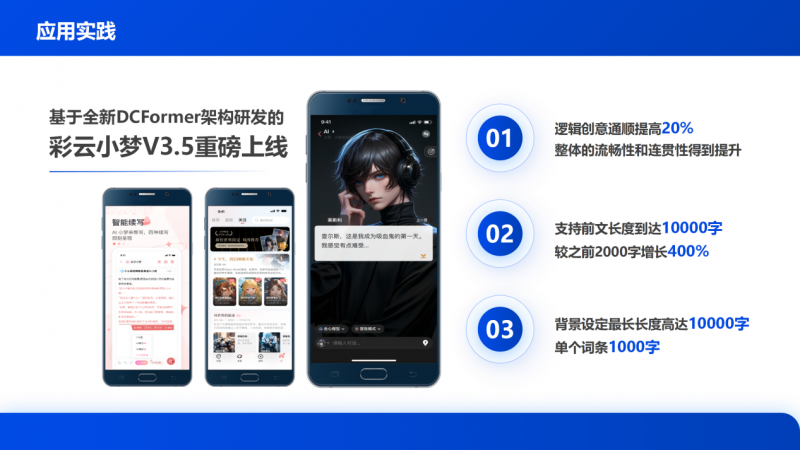
这一点,似乎已经在彩云科技自己的产品,彩云小梦V3.5上实现了印证。这款基于DCFormer架构应用的故事续写、陪伴类型的人工智能产品,在访问深度、交互长度上都实现了同类型产品的领先,平均150分钟的交流时长,超过400+句的深度对话,远超当前业内平均20分钟左右的交互时长。这背后,正是基于DCFormer架构带来的革新。“用户在对话超过400句后,彩云小梦依然能够记得之前对话里的细节,甚至记得对话中各个NPC的爱好、习惯,超长记忆和一致的逻辑,使得彩云小梦成为真正的‘指尖伴侣’。”
“将DCFormer架构的模型效率再次提升一倍,是我们接下来一年的目标。”袁行远介绍,“只有模型效率和智能度提升,才能实现真正的AGI。”