
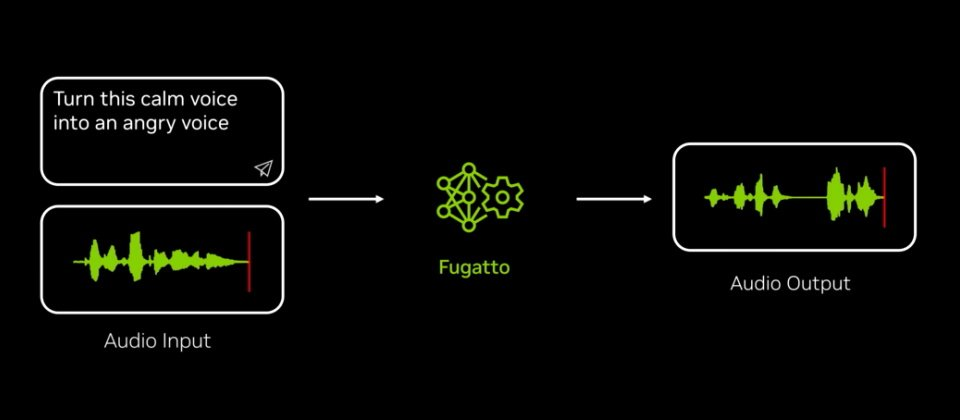
英伟达本周发表一个能依文字或音乐文件提示,生成或修改一首混合音乐、人声和音效的AI模型,名为Fugatto。
图片来自英伟达
现今有多家厂商,包括谷歌、Meta推出可生成短曲、音效、或修改现有音乐的AI模型,英伟达发布的Fugatto可依据用户输入的文字,或上传的音频文件,生成或修改音乐、人声或声音的元素组合。例如它可以根据使用者文字提示生成音乐片段、在现有歌曲加入一种乐器声音(或移除),或是改变人声腔调或是情感,甚至发展出全新的表现方式。
Fugatto全名是“Foundational Generative Audio Transformer Opus 1”,是一个基础生成式transformer模型,为英伟达在之前语音模型、音频编码及音频理解等基础上的研发成果。模型本身包含25亿参数,是在32颗H100 GPU的DGX系统,在一年多期间,以数百万音频样本及文字资料训练而成。
Fugatto训练团队遍布印度、巴西、中国、韩国和约旦。英伟达指出,研究团队使用多面向策略产生资料和指令,以确保模型能胜任多种不同任务,他们也审视现有数据集,找出数据间的新关联性,在不需额外新数据集情况下,使模型学习到新任务且获得高准确性。
例如Fugatto使用名为ComposableART的技术,把原本个别使用的指令组合起来,像是组合多个指令,例如用户可要求它用悲伤情绪说一段法语,还允许插入不同指令的功能,方便使用者微调,像是腔调浓重或是悲伤程度。
英伟达还贴出了一段影片,展现Fugatto可为电影创造出震撼的配音。
Fugatto还具备时序插入(temporal interpolation)能力,可生成随时间改变的声音,像是暴风雨中由近而远传递的雷声,也提供声音地景的微调功能。此外,有别于其他多数模型只能重建模型团队输入的训练资料,Fugatto还让使用者新创造全新的声音地景,像是风雨过后随着鸟鸣来到的清晨。
目前很多企业都在积极开发生成音乐、人声及音效的AI技术。ElevenLabs、DeepMind都在开发助力影片配音的技术、Meta去年公布可同时接受文字和音频输入的AudioBox。OpenAI也在今年早些时候也公布了以15秒样本生成人声的模型。






