第一次去现场参加re:Invent大会,第一次在亚马逊云科技re:Invente展区看风景,一口气看到了很多有意思的东西。接下来,根据目前掌握的资料和信息,简单分享下目前关于UltraServer的相关信息。

现场我看到了AMD的MI300,英伟达GB200,还有亚马逊云科技的Trainium2,以及基于Trainium2的超级服务器UltraServer。

而这,就是英伟达的超级芯片GB200,一块Grace CPU还有两块Blakwell200芯片,三者之间用NVLink两两互联,外部用NVLink交换机继续连接,扩展到有72块B200显卡,内存可共享的大集群。

这是GB200装入服务器之后的样子,可以看到,它已经采用了冷板式水冷方案。没办法,它的功耗太大了。

值得注意的是,这张截图左边绿色框全部都是英伟达做的,亚马逊云科技做这台服务器时,不需要对这部分做太多修改,也没办法做太多修改。
而右面部分是亚马逊云科技利用Amazon Nitro系列打造的,提供网络、安全、还有SSD存储等方面的能力,Nitro是亚马逊百试不爽的数据中心神器,被叫做服务器里的服务器。
这应该就是最新发布的P6实例背后的服务器,最大的问题是它不够灵活。为了解决这个问题,亚马逊云科技拿出了UltraServer服务器。

这就是此前发布的Trainium2芯片,有两个大的计算Die,两边都有HBM。
有意思的是,这一代还把电压调节器直接嵌入芯片封装的外围,这种设计减少了电力传输路径的长度,从而减少了高负载时,因为电压下降而导致性能下降的问题。(这一功能叫Backside Power Delivery)

这是我在现场看到的UltraServer服务器,没错,两个机架现在都能叫一台服务器了,这台服务器非常的不简单,不寻常。
这样一台UltraServer服务器其实可以分成四个部分,为了方便了解,现在只看它的四分之一。
这四分之一应该就是一台Trainium2服务器,它能构成普通的Trn2实例。

接下来介绍一下内部构造:
首先看到,最上面有一堆褐色的连接线,这就是PCIe连接线。
连接线的一头插在了CPU的盒子,连接线的另外一端连接8个放着Trainium2芯片的盒子,每个盒子里有两个Trainium2芯片。
请注意,这里完成了CPU跟Trainium2加速器的解耦。也请回忆一下跟GB200超级芯片的区别。
介绍完了CPU跟显卡的连接,再来看紫色的线,它负责连接800G的交换机。

上图就是800G的网络交换机,其定位有点类似英伟达的Spectrum SN5600以太网交换机,两者都有64个端口。另外,淡黄色的线是IO的连接器,是负责连接存储用的,负责存储的解耦。

缩小一下图片来看,这里会注意到蓝色的很粗的线,这就是最新介绍的NeuronLink,名字跟英伟达的NVLink很像,功能也有点像,都是chip-chip的连接线。
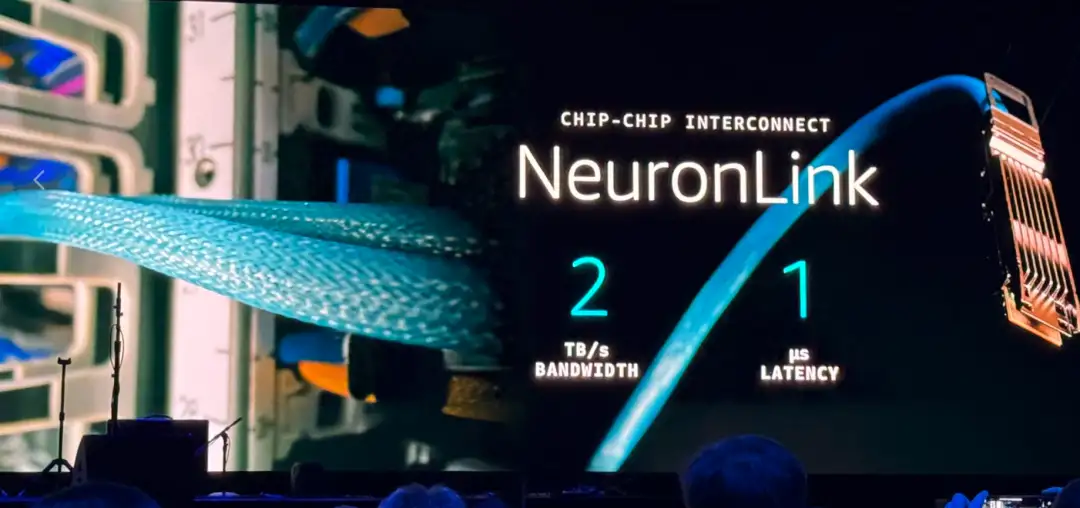
不过,它只是连接另外一个放置Trainium2盒子的线,每个盒子伸出来两根蓝色的线。不难脑补出这个图谱,是一个两两互联的方块,但没有对角线的直接互联。
这就是UltraServer的大致情况,四个计算盒子加上32个Trainium盒子,就组成UltraServer。
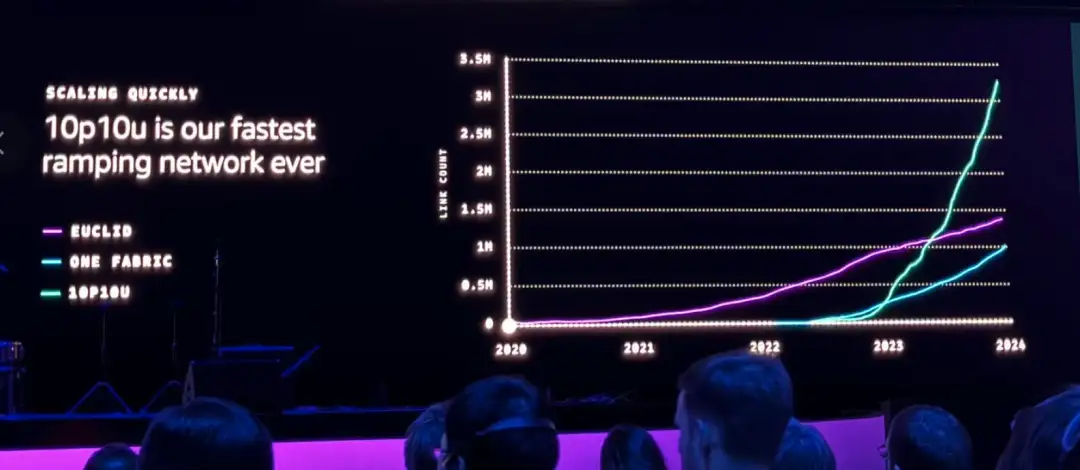
另外,UltraServer之间会用10P10U的网络进行互联,所谓10P10U指的是,10Pb/s的传输带宽,以及10微秒的网络延迟,连起来之后,就组成了可用于训练的超级集群。(注:10P10U也被称作是UltraCluster 2.0)

有朋友注意到,亚马逊云科技还提到了SIDR,它提供了一种高效的方式来快速检测和响应网络故障,能在很短的时间重新规划网络路径,为大规模集群提供了超高的网络可靠性和故障恢复能力,也是 10P10U 网络的重要支撑技术。
最后提一下,亚马逊云科技高级副总裁Peter DeSantis在演讲中特别提到了Tranium2支持的 Systolic Arrays (芯片脉动阵列)架构。
它跟CPU还有GPU需要反复读取内存传递数据的做法不同,它在拿到数据之后,能够在Tranium2之间直接传递计算结果,最大程度减少内存带宽压力,能更高效地处理矩阵乘法和稀疏张量等深度学习工作负载。

UltraServer这种解耦的设计与英伟达GB200的方案相比,有很多好处:
第一个就是,因为它完成了CPU跟Trainium2这种ASIC加速器的解耦,单个加速器出问题之后,不会影响整台服务器工作。
而UltraServer在单个Trainium2出问题之后,只需要把它所在的Trainium盒子拿出来替换掉就行了,增加了灵活性和可维护性。
另外一个优势在于,它采用的是风冷的方案,刚才也看到了,GB200服务器方案是液冷的,维护起来会比较麻烦。
我注意到,UltraServer本身并不是要去直接取代英伟达的GB200。UltraServer强调的算力是FP8的,FP8 正在迅速发展,并逐渐被引入训练环节,特别是在优化计算性能和内存利用率方面。

而在目前,FP16 是训练环节的主要选择,因为它成熟稳定,能满足模型精度需求,并显著提高性能,这目前仍是英伟达的显卡更有优势的领域。亚马逊云科技也强调,自己是最适合GPU的云。
以上就是目前我知道的,关于Trainium2的UltraServer服务器的主要内容。如果您知道更多细节,或者我有理解不对的地方,欢迎评论区互动讨论。