
亚马逊云科技的re:Invent上,托管的机器学习推理服务Amazon Bedrock迎来了一系列更新。
现在,Amazon Bedrock不仅新增了非常多的模型可供选择。同时,依靠统一的API,用户可随时切换到新模型,帮用户克服模型选择焦虑症。

模型太多,变化太快,不知道怎么选?
与侧重训练的Amazon SageMaker不同,Amazon Bedrock主要是将训练好的基础模型进行推理,帮助开发人员构建和扩展生成式AI应用,由于更靠近应用创新的部分,因此受到了更多关注。
亚马逊云科技人工智能与数据副总裁Dr. Swami Sivasubramanian将Amazon Bedrock的更新细分成了五个方面,如果非要挑选Amazon Bedrock现阶段最大的价值或者卖点的话,就是它对于多个模型的支持。
当前,生成式AI大模型技术仍在快速发展当中,不同模型在不同应用场景中的表现会有很大差异。对于希望应用生成式AI大模型的企业而言,如何选择合适的模型,如何在新模型出现时快速完成技术切换就显得尤为重要。
亚马逊云科技人工智能、机器学习与基础设施服务副总裁Baskar Sridharan在采访中表示,从原型到产品化的过程中,模型选择是至关重要的关键因素之一。亚马逊云科技通过整合来自领先供应商的广泛模型,为用户提供了极大的自由度。然而,今天可能模型A是最佳选择,几个月后模型B可能更适合,再过一段时间可能需要模型C。因此,用户需要的是既能跟上模型进化步伐,又能保持技术堆栈稳定的解决方案。
于是,亚马逊云科技开始在这两方面发力:一方面提供丰富的模型选择,满足用户多样化的需求;另一方面确保整个生态系统的稳定性,为企业打造兼具灵活性与可靠性的生成式AI平台。这种平衡无疑是推动技术落地的重要支撑点。
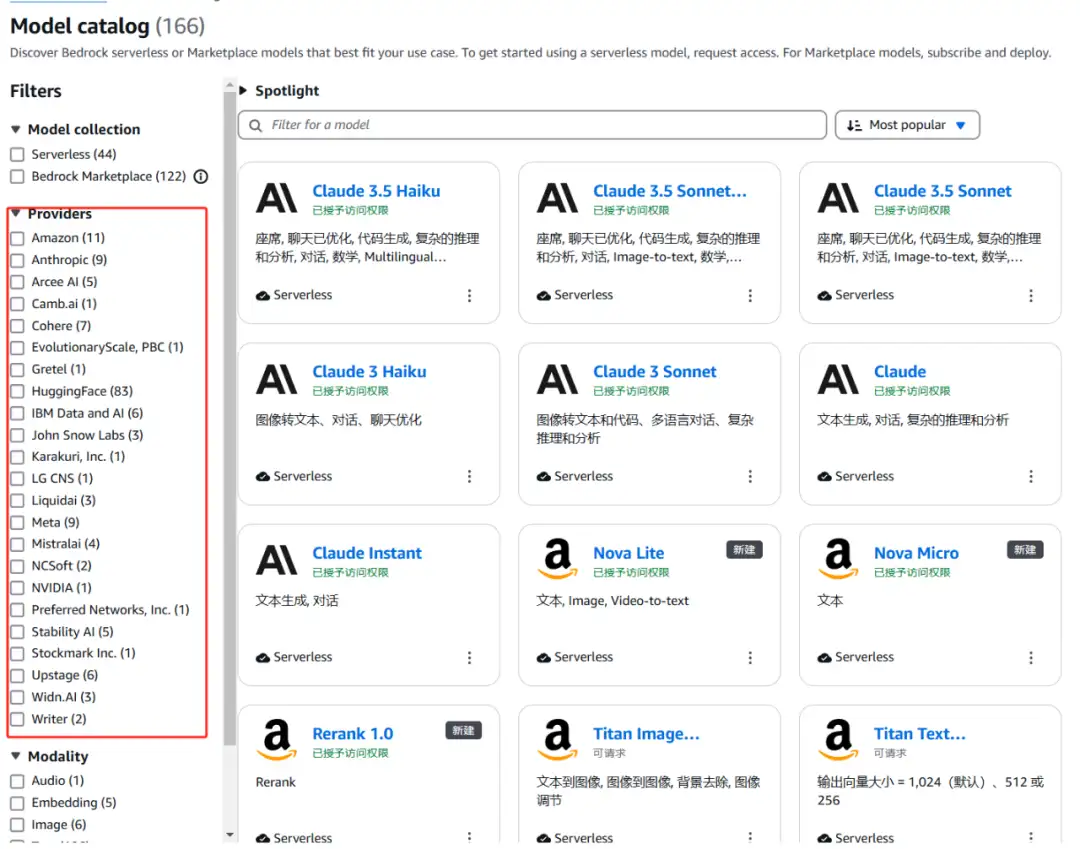
Amazon Bedrock给了用户自由选择模型的权利,平台上不仅整合了来自Anthropic、Meta、Stability AI以及Amazon等23家开发商的模型,覆盖文本生成、多模态理解、图像与视频生成等多个领域。
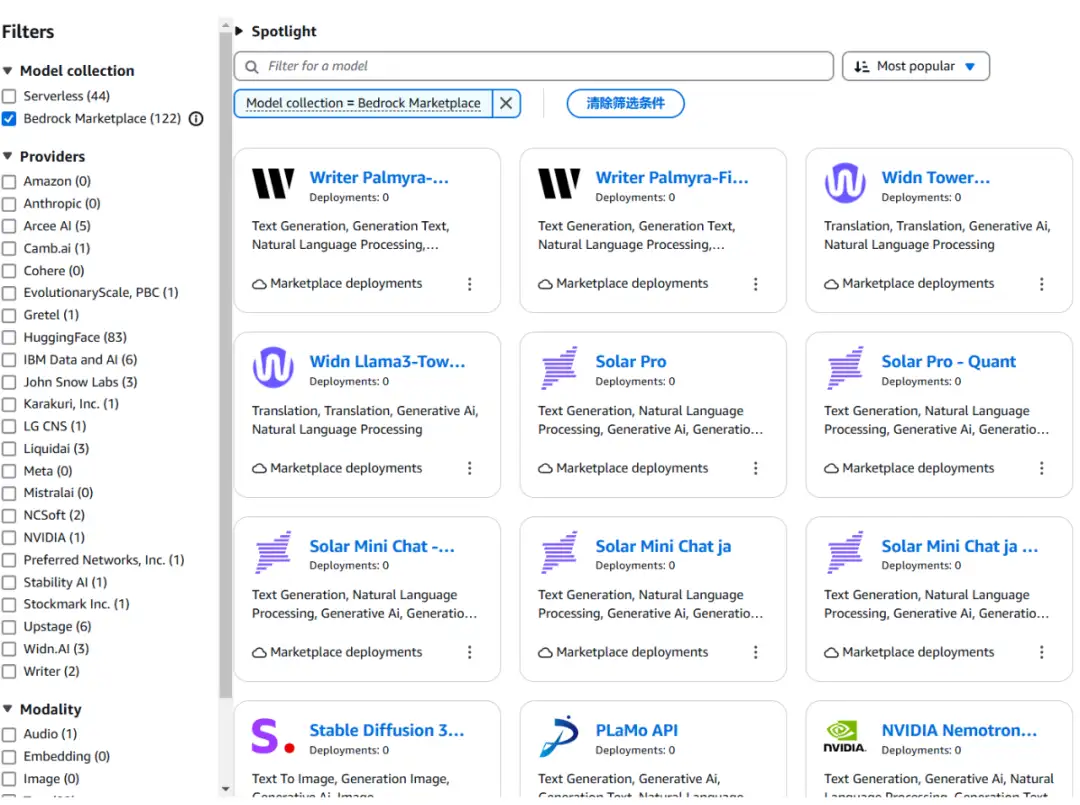
其中,新推出的Amazon Bedrock Marketplace使用户能够访问另外120多个大模型。与原来最大的不同点在于,Marketplace都需要用户自己创建推理模型的主机,而原来的都是Serverless这种高级的方式。不过,两者都可以用统一的API调用。
看得出来,Amazon Bedrock在竭尽所能地提供更多模型可供选择,用户可以在这里评估模型的效果。当用户面对N多模型不知如何选择的时候,可以在这里做出选择,哪怕模型并不是最理想的,也不用焦虑。
这是因为,Amazon Bedrock提供的是统一的API,这意味着可以简化模型集成和切换的过程。当有新的更合适的模型出现,开发者可以快速完成切换,无需进行大量代码修改即可升级到最新的模型,真正克服大模型选择困难症。
除了推出更多模型,亚马逊云科技还在将Amazon Bedrock打造成更适合大模型的云服务。
Amazon Bedrock优化推理的成本、延迟和准确性
过去两年以来,AI算力关注的绝对焦点就是训练。然而,随着文生视频大模型越来越多,同时,专家发现,依靠模型“慢思考”的模式可以提高模型的最终表现,依靠推理算力提高模型表现的做法受到关注。于是,未来推理的负载会越来越多。
在re:Invent期间,亚马逊云科技的Amazon Bedrock为优化生成式AI推理效率推出了多项创新功能,帮助开发者在成本、延迟和模型准确性之间找到更好的平衡。
其中,新的模型蒸馏功能支持将大型模型的知识转移到更小、更高效的模型上,可实现高达500%的速度提升和75%的成本降低。
此外,新增的延迟优化推理选项让开发者能够利用最新的AI硬件和软件优化,进一步提升推理性能,满足多样化的业务需求。
Amazon Bedrock新推出的提示词缓存功能能够缓存重复使用的提示前缀,从而避免模型重复计算,延迟最多降低85%,成本最多降低90%,特别适合文档问答、代码助手、智能搜索或长对话等需要复杂提示的应用场景。
Amazon Bedrock新推出的智能提示词路由功能,通过动态分配提示请求到模型家族中的不同基础模型,实现高质量响应的同时降低成本,最多可节省30%。
它帮助开发者优化任务的处理,用更高效的模型处理简单任务,而复杂需求则交给更强大的模型,它提供了一种更高效、更经济的模型管理方式,加速开发并提升整体性能。
Amazon Bedrock让用户更高效地使用用户自己的数据
用户向通用模型发出提示词,只会得到一个通用的答案,而如果模型能使用用户自己的数据,就可以得到有更多上下文的回复。
在过去两年中,我们知道用户可以对模型的微调和RAG(检索增强生成)技术来使用自己的数据,从而生成更符合上下文的答案。
RAG是一个相对技术化的语言,Amazon Bedrock把它包装成了知识库服务。在re:Invent期间,亚马逊云科技对RAG技术能力,也就是知识库相关的服务提供了四项增强的能力,其核心思想就是帮助用户更方便地把自己的数据交给模型。
第一个叫GraphRAG。这里的Graph不是指图像,而是知识图谱。它用知识图谱来帮助生成式AI更智能地整合和理解分散在多个数据源的信息。幸运的是,开发者不需要了解复杂的知识图谱技术,GraphRAG会自动完成这些工作,最终让模型给出更相关、更可信的答案。
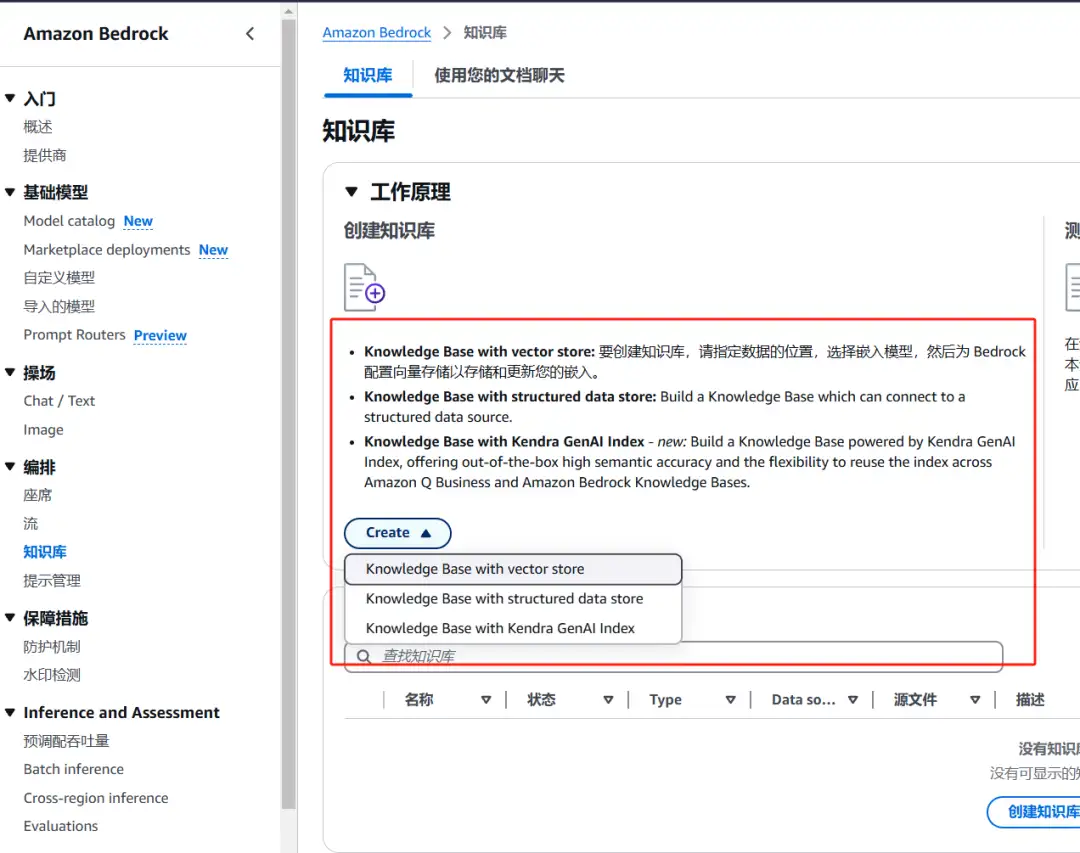
知识库结构化数据检索功能:让生成式AI能够直接从Amazon Redshift中提取结构化数据,并生成精准的自然语言响应。通过这一功能,开发者无需构建复杂的SQL查询,系统会自动将自然语言请求转换为SQL,查询所需数据并整合到AI模型的响应中。该功能简化了企业利用结构化数据开发生成式AI应用的过程。
Amazon Kendra GenAI Index是一款高精准的智能搜索工具,通过高精准的智能搜索和数据整合能力,快速接入和整合内容,无需开发复杂的自定义搜索机制或进行繁琐的数据迁移,全面提升数据利用效率。它无缝集成Amazon Bedrock知识库及相关功能,帮助企业轻松构建高级生成式AI应用。
Data Automation数据自动化功能:该功能通过一个简单的API,将非结构化数据自动提取、转换为结构化数据,并生成符合生成式AI应用需求的自定义输出,无需开发者编写任何代码。这项技术可大幅降低数据处理复杂度和成本,让企业能够充分利用多模态数据,构建更智能、更高效的生成式AI应用。
构建具有安全性和负责任的AI
可以说,生成式AI在企业应用场景中落地最优先考虑的就是安全性,Amazon Bedrock Guardrails可以为生成式AI应用实施定制的保护措施。
Automated reasoning checks自动推理检查功能(预览版):该功能通过数学验证技术检测大型语言模型(LLM)的幻觉现象,确保生成的答案准确,并提供可验证的证据,从而提升生成式AI在关键场景下的透明性和可信度。该功能允许领域专家创建规则化的推理政策,将复杂业务逻辑融入AI模型的验证流程。
Amazon Bedrock Guardrails的多模态毒性检测功能新增图像内容的检测与过滤能力,能够识别并屏蔽包含仇恨、暴力、侮辱或不当行为的图像内容。该功能适用于所有支持图像数据的模型,包括微调模型,与文本过滤功能共同构建统一的安全保护层,帮助开发者确保生成内容的安全性与合规性,满足多模态AI应用安全需求。
多智能体协作功能,解决更复杂的任务
智能体(Agent)是指能够感知环境、进行决策并采取行动的系统,它是AI系统中不可或缺的部分,其自主性和适应性使其在众多场景中具备巨大价值,推动了AI的实际应用与发展。

Amazon Bedrock新增多智能体协作功能,支持多个专属智能体共同协作,通过智能编排实现从语言理解到主动推理和执行的全流程自动化。开发者可轻松构建和管理智能体系统,将高级目标分解为可执行的步骤,大幅提升解决复杂任务的能力。
小结
Amazon Bedrock在此次更新中全面提升了生成式AI的实用性,从模型选择、推理优化到数据整合、安全性保障,再到智能体的编排与应用,为开发者提供了更强大且灵活的工具组合。
这些功能降低了生成式AI的开发门槛,还加速了其在企业场景中的落地与价值释放。在生成式AI蓬勃发展的当下,Amazon Bedrock无疑为企业提供了通向智能未来的重要桥梁,为推动整个行业迈向更高水平贡献了强劲动力。




